Starting with entity extraction, you can determine if the content contains the appropriate semantic annotation and relevant entities to improve your ranking on Google.
In a few clicks, you can analyze the entities behind a search query and the entities behind a web page (whether it’s your page or a competitor’s) and develop a semantic content strategy that determines which entities can enrich your content and beat the competition.
The Entity Analysis is straightforward and supports hundreds of languages with many different alphabets (any language natively supported by WikiData).
It includes:
The list of entities with links to DBpedia or WiKidata,
The confidence level of each entity (a value from 0 to 1 that takes into account factors such as thematic relevance and contextual ambiguity),
The ranking of the entities in the SERP (this data is obtained during the analysis of the entities to which a query refers),
The number of occurrences in the text (i.e., how often the entity appears in the mentioned content).
You can select the most relevant entities, and the SEO Add-on will automatically create the JSON-LD for you!
To know which search queries you should boost, you can connect the SEO add-on to your Google Search Console and sort the analysis based on your traffic data. Here you will also find a column with the “Opportunity Score“, which suggests which search queries you should target to choose the best ones for your content.
Learn how to use the SEO Add-on for Google Sheets, watching this demo👇
What is the difference with WordLift?
“Things, not strings”
Amit Singhal, Google SVP of Engineering, 2012
This is the Semantic Web.
Entities that stand for an idea, concept, person, or place, are the real star of Semantic SEO. Google and the search engines are using more and more entities to figure out how to rank websites and web pages.
Therefore, keyword research is no longer enough. This is where our SEO add-on comes into play. With a few simple clicks, you can analyze and compare entities either by search queries or URLs or both and find the ones that are really relevant for your website to get a better search engine ranking.
Indeed, once you have identified the entities most relevant to your business, you can copy and paste the JSON-LD into your website to speak Google’s language and see your organic traffic grow.
If you are already using WordLift, you can analyze the entities and compare the entities annotated in your content with the entities that rank for the search query, as well as those of competitors, and then figure out how to optimize the content to rank better on Google.
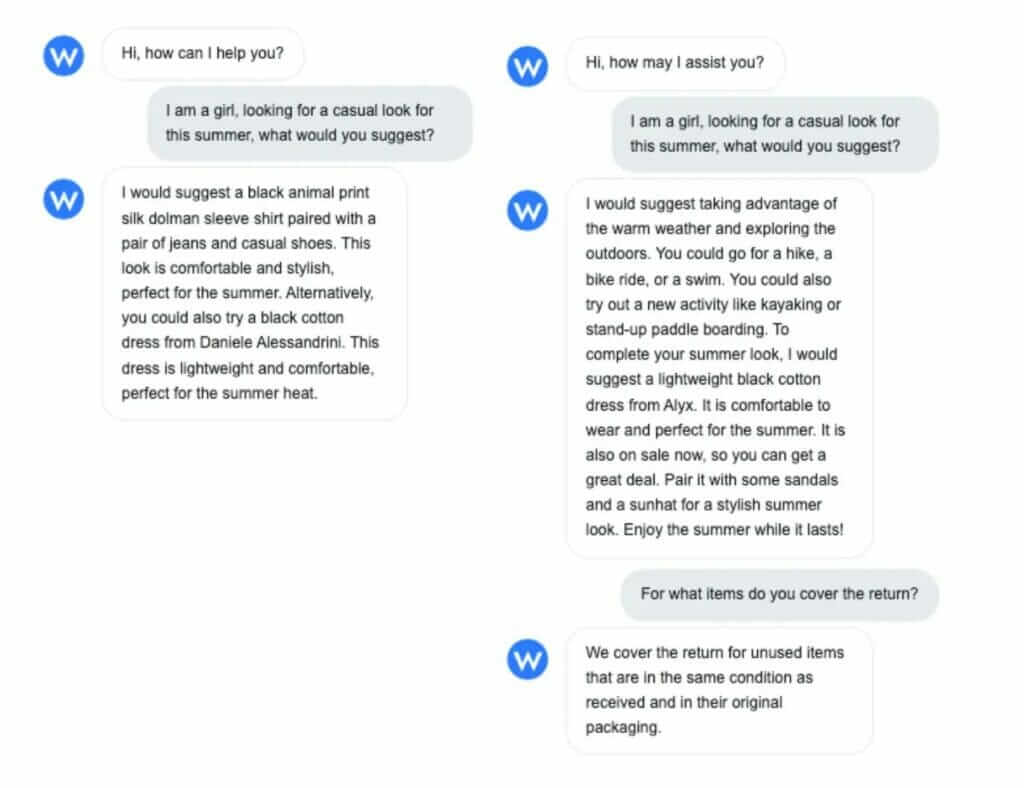
WordLift is an AI-powered SEO tool that analyzes your content, identifies the most relevant concepts for your business, and allows you to insert semantic markup without needing any technical knowledge. These relevant concepts are the entities and are collected in a vocabulary. By relating the entities to each other, you can build the Knowledge Graph. It’s the infrastructure behind your website that allows Google and search engines to understand what you are talking about, and to see the relationships between pages and content, and their value.
This way, your website will rank better and get more organic traffic. Not only that, but users searching for products, services, or businesses like yours will find information that is more relevant and they will spend more time on your website and you can increase the conversion rate.
SEO Add-ons for Google Sheets™ and WordLift plugins are different, but they can work together to automate your SEO and save you more time, energy, and even money.
When you use the SEO Add-on together with WordLift, you can analyze entities and optimize your content so that Google and the search engines understand what you are talking about, and you get better rankings and more organic traffic to your website.
So, to sum up, what are the benefits of using the SEO Add-on for Google Sheets™?
Understand how to rank for a specific search query;
Learn how to optimize the ranking of your favorite content;
Compare a glance entity between competing URLs, search queries, or both;
Analyze the semantic spectrum you need to cover a specific topic.
The SEO Add-ons for Google Sheets™ is included in the Business+E-commerce plan. Or you can purchase it separated on StackSocial. If you buy the Add-On and want to add WordLift to your SEO tools, you’ll get a special discount. To learn more, talk to our team of experts.
In a quest to redefine the landscape of Search Engine Optimization (SEO), Artificial Intelligence (AI), and knowledge graphs, WordLift embarked on a transformative journey known as the WordLift NG project, funded by the European Union. The project sought to surpass the constraints of the conventional WordPress ecosystem, ushering in a new era of digital intelligence.
Collaborative Endeavors
The project was operated by a Consortium consisting of WordLift and three esteemed Austrian partners: the Computer Science department of the University of Innsbruck, Salzburgerland Tourismus (the Salzburg tourism board), and long-time technology partner, Redlink.
At the center of the project was a fundamental commitment to advance the WordLift plugin beyond the WordPress platform. This strategic move broadened its horizons and exemplified a bold leap into new frontiers. This initiative was perfectly intertwined with the overall objective of enriching the range of offerings provided by WordLift, resulting in a series of product innovations and increased accessibility, all meticulously designed to meet its user community’s diverse needs and preferences.
The work carried on by the four partners resulted in attaining key objectives and establishing a robust foundation for future developments.
Project Summary and Key Achievements
The creation of the WordLift NG platform stands as a remarkable achievement, offering advanced service management and scalability. The shift from a monolithic to a microservices architecture has empowered the platform to efficiently handle high-traffic websites, making it an invaluable asset for both WordPress and non-WordPress users.
WordLift’s dedication to customer migration has yielded impressive results, ensuring seamless transitions for a diverse global clientele. This significant endeavor highlights the company’s unwavering commitment to maintaining operations and ensuring customer satisfaction.
Some of the functionalities developed within the project have significantly impacted the effectiveness of the final WordLift NG outcome, such as an improved GraphQL integration for enhanced scalability of query complexity. This was extremely important to the development of the upcoming content generation module.
The innovation of solutions for websites beyond WordPress has further solidified WordLift’s position as a frontrunner in Italy’s AI landscape.
WordLift achieved the more prominent results within the scope of the project, such as:
Improvement of the backend performances by enabling and querying graphs
Implementation of semantic search and content recommendations for users
Successful integration with digital assistants.
WordLift delivered a solid platform based on a B2B2C model that enables brand recognition, effective distribution, and network building.
Furtherly, within the scope of the project, WordLift developed tools and functionalities, beyond the product, such as an SEO add-on for Google Sheets, the introduction of a connector for Google Looker Studio, and the establishment of a versatile content generation tool.
Ongoing and Future Objectives
While the project’s central objectives have been achieved, the WordLift NG consortium acknowledges that innovation is an ever-evolving journey. Several goals, which serve as beacons for future endeavors, require further development activities to realize their potential fully.
Ongoing experimentation on semantic search remains a dynamic pursuit as WordLift explores the use of generative AI and structured data to develop new workflows.Similarly, the quest to create conversational interfaces powered by the knowledge graph signifies a commitment to stay at the forefront of AI advancements. The initial prototypes exhibit promise, but continued refinement is essential to ensure scalability and compliance with emerging European regulations.
The combination of large language models (LLM) and knowledge graphs, in what we are callingNeuro-symbolic AI, represents a promising avenue to explore, requiring rigorous experimentation and systematic investigation to discover synergies and maximize the potential of these domains.
Impact and Future Prospects
The WordLift NG project marks a significant milestone in the company’s pursuit of excellence in AI-driven semantic search and content generation. The achieved objectives underscore WordLift’s commitment to innovation and ability to adapt to the ever-changing technological landscape.
The pioneering spirit demonstrated throughout the project promises cutting-edge advancements, continued collaboration, and a steadfast commitment to reshaping the semantic search and knowledge representation world.
In the spirit of European innovation, WordLift stands ready to inspire, disrupt, and drive transformative change, propelling the company, its partners, and the industry toward new horizons of possibility.
AI researchers have made tremendous strides in building language models that generate coherent text. A seminal paper introduced in 2017 by the Google Research team (“Attention is All You Need”) introduced a new neural network architecture for natural language understanding called transformers that can generate high quality language models with significantly less time for training.
These models have been harnessed to tackle a wide range of problems, from open-ended conversations to solving math problems, from poetry to SEO tasks like writing product descriptions. Generative AI comprises, alongside text generation, other abilities that a powerful new class of large language models enables: from writing code to drawing, from creating photo-realistic marketing materials to creating 3D objects, from producing video content to synthesizing and comprehending spoken language with an unprecedented quality.
This blog post provides an overview of Generative AI and how it can potentially be used in the context of SEO.
I have been generating synthetic images for almost two years with diffusion based models. Our team here at WordLift creates thousands of AI. content snippets every month, from product descriptions to FAQs, from short summaries to introductory text. We actively collaborate with companies like OpenAI, Microsoft, and Jina AI to scale these workflows for our clients (SMEs and enterprises).
Satya Nadella and Sam Altman from Open AI during Microsoft Ignite 2022 (WordLift is there!!)
Here is the table of content, so you can skim through the article:
One way to look at the evolution of Generative AI is to map key innovations in the field of LLMs and see how they can be potentially used in specific SEO workflows.
Below, I highlighted the foundational models that can have an impact in the different areas of SEO (from entity SEO to programmatic, from Google Lens to 3D Serps) and the potential workflows that we can build on top.
AI-Powered SEO Workflows
Text Models
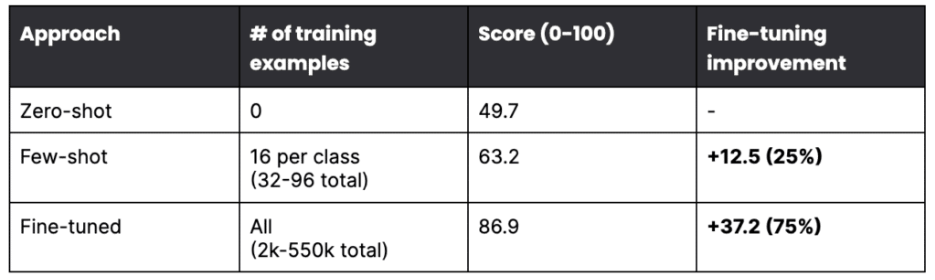
This is where the state of art is the most advanced, and the adoption is increasing faster. Models are incredibly diverse, and each one has its characteristics, but generally speaking, depending on the workflow, you can either start with a simple prompt (also called zero-shot), provide a more elaborate set of instructions (few-shots training), or fine-tune your model. Here is how you can use generative models that work with text.
Internal Links
In SEO,internal linksremain a valuable asset as they help search engines understand the structure of a website and the relationships between different pages. They also help to improve the user experience by providing a way for users to navigate between the different pages. We can take into account semantic similarity, entities and what people are searching on our website to make these links effective. Here is a blog post about automating internal links for eCommerce websites using LLM.
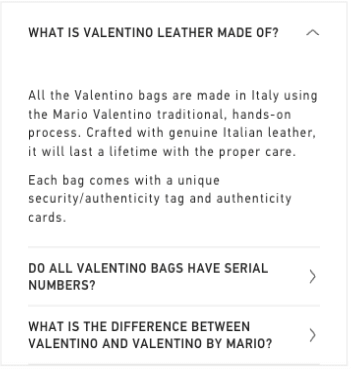
FAQ Generation
Adding content in the form of questions and answers has become a great tactic in SEO. As Google becomes more conversational, questions and answers marked up with structured data provide searchers with more relevant content in various contexts: from the people also ask block to FAQ-rich results, featured snippets, and even the Google Assistant.
An example of automated FAQ for a luxury brand.
Workflows here have become highly sophisticated and take advantage of multiple AI models to help editors in the different areas of the work: from researching the topic to planning, from writing the answer to reviewing it, adding internal links, and validating the tone of voice.
Product Descriptions
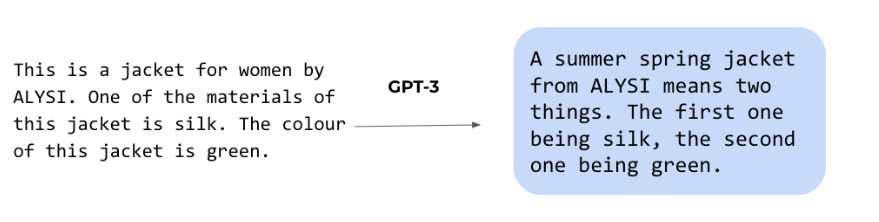
Language models are perfect for creating high-quality product descriptions for eCommerce websites to fuel sales. The short form and stylized nature of product descriptions are an ideal fit when combined with the time and cost pressures on editorial teams working on thousands of products daily. The game-changer when creating product descriptions using models like GPT-3 by OpenAI or J1 by AI21 is the vertical integration of product data and the ability to craft UX patterns for fast feedback loops.
Summarization
Starting in 2019, I began using BERT-like models for automating the creation of meta descriptions. We can quickly summarize a lengthy blog post. Can we help editors accelerate their research by summarizing the top search results? The impact of text summarization in SEO is enormous.
How WordLift uses extractive summarization to improve the UX on blog posts.
Introductory Text
Can we describe the content of a category page using a fine-tuned LLM? Is it possible to personalize content to make it more likely to be of interest to a specific target audience? Generating short form content is a great way to use foundational models.
Structured Data Automation
Graph enrichment is becoming essential to gain new features in the SERP and to help search engines understand the content and the relationship between entities. From named entity recognition to topic extraction, we can turbocharge schema markup with the help of RoBERTA, spaCY, and the WordLift NLP stack.
Chatbot
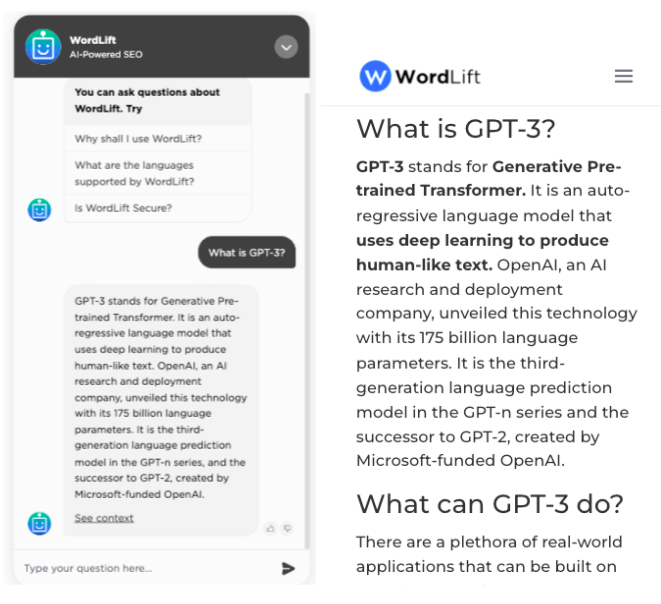
LLMs are becoming strategic in conversational AI or chatbots. They have the potential to provide a better understanding of conversations and context awareness. One of Google’s engineers was even (wrongly) convinced that an LLM like Google LaMDA could be considered conscious. SEO is an important aspect when creating a conversational experience. Why? As we work extensively to train Google with question-answer pairs, we can re-use the same data (and the same methodology) to train our own AI system.
The chatbot on our documentation website (on the left) extracts answers from the blog post (on the right) and helps users find the right information. It works like a search engine and like every search engine, SEO is a blessing.
One way to provide contextual information when constructing an AI-powered conversational agent, such as a shopping assistant, is to combine the structured world of knowledge graphs with the fluent, context-aware capabilities of language models (LMs). This fusion, which we call neurosymbolic AI, makes it possible to transform the user experience by creating personalized conversations that were previously unthinkable.
We have developed a new connector, WordLift Reader, for LlamaIndex and LangChain to transform static and structured data into dynamic and interactive conversations.
With only a few lines of code, we can specify exactly what data we need by extracting from our KG the sub-graphs we want. We do this by using specific properties of the schema.org vocabulary (or any custom ontology we use).
The connector uses GraphQL to load data from the KG, this ensures conversations are always up-to-date with the latest changes to the website, without the need for crawling.
The following example is a shopping assistant built using this approach. As can be seen, the combination of multiple schema classes helps the AI to respond to multiple intents:
schema:Product to recommend products
schema:FAQPage (on this site) to answer questions about the store’s return policy
Code Models
They are already having a significant impact on developers’ productivity, as demonstrated by a recent study by GitHub. Developers feel more fulfilled when they use AI in pair-programming mode. There are still several concerns about IP violations that models like GitHub Copilot introduce, and too little has been done to address these problems. Nevertheless, also in the SEO industry, they are starting to play a role.
Text to Regex
One very simple use case is to convert plain english to regex to help you filter data in Google Search Console. Danny Richman got you covered and if you want to learn more here is his recipe.
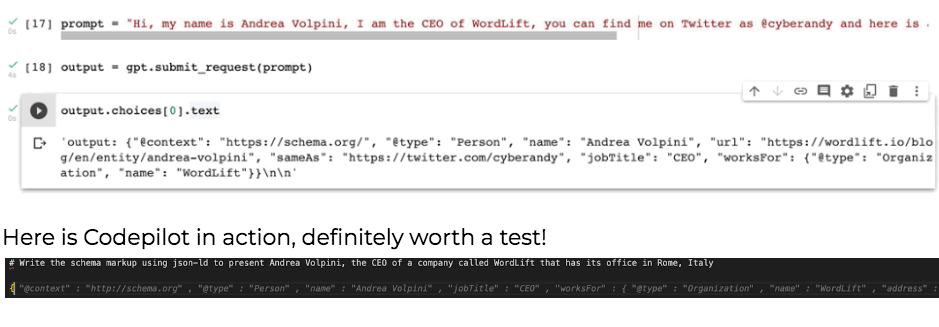
Text to Structured Data
I trained the first model a couple of years ago using GPT-2 and right now using Codepilot things are getting a lot simpler. These solutions are very helpful to sketch the JSON-LD that you would like to get.
Image Models
Generative AI models for image generation are revolutionizing the content industry. We have seen AI-generated images going viral in only a few months and even winning fine art competitions. Each model has its unique touch; you will get more fantasy-like images from Midjourney and more realistic results from DALL·E 2 or Stable Diffusion. All models share the same understanding of the world, and this is encoded into CLIP, a Contrastive Language-Image Pre-Training by Open AI trained on a vast amount of (image, text) pairs. CLIP can be instructed to analyze the semantic similarity between an image and a text. If you genuinely want to understand how AI models for generating images work, CLIP is where to start.
Here is an introductory Colab that you can use to see how CLIP works (powered by Jina AI): [Colab] – Code to experiment with CLIP
Super Resolution
One very simple thing to do, in the context of SEO, is to use AI models to increase the resolution of images associated with blog posts or products.
SEO image optimization, especially when combined with structured data, helps increase click through rate.
Here is a blog post and the code to get you started with image upscaling: [Blog Post] – AI-powered Image Upscaler [Colab] – Code to upscale images in batches
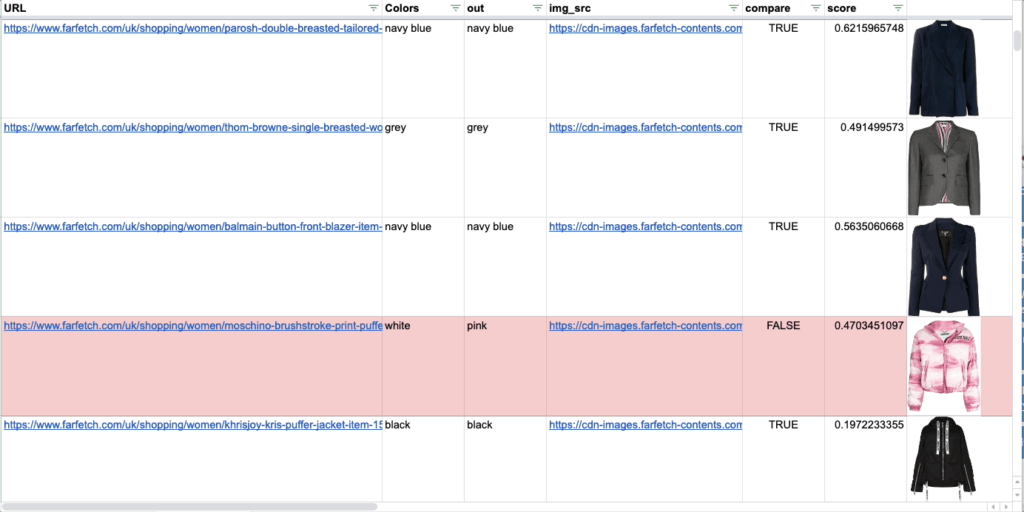
Visual Inference
Imagine the potential to automate extensive evaluation on large product catalogs by training a model that can analyze images and verify that there is a correspondence with the text that describes each product. This is what we are doing using pre-trained CLIP models.
Generating Product Images
Investing on image quality for retail stores is usually an easy win for SEOs. The technology is not yet there but there are some interesting startups like vue.ai focusing on this use case and I expect we will have something ready for our clients within a few months. Typically you will focus on:
Generating images in different context (changing the background, changing the style)
Generating on-model product imagery
Creating images from different angles
Video Models
Progress made on the text-to-image generation field paved the way to text-to-video generation. There are models already in this field by Microsoft, Meta and recently also Google. Make-a-video by Meta AI is an interesting experiment that present the state of the art in this sector.
Speech Models
As CLIP has been revolutionary for images, Whisper, a general-purpose speech recognition model by OpenAI, is impactful for audio and audio video. Whisper has been trained on 680,000 hours of multilingual and multitask supervised data, bringing automatic speech recognition (ASR) to a new level. You can, as in the example below, automatically add subtitles in English to a video in German or summarize it in a few sentences.
Here is the code to get you started with Whisper and YouTube optimization: [Colab] – Code to transcribe a YouTube video, produce subtitles, generate a summary and extract questions and answers.
3D Models
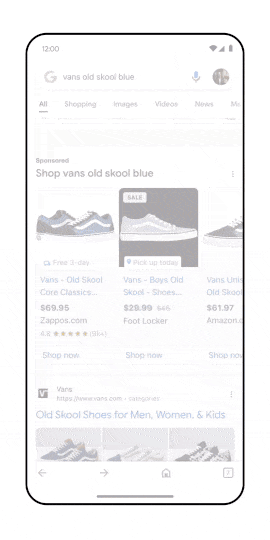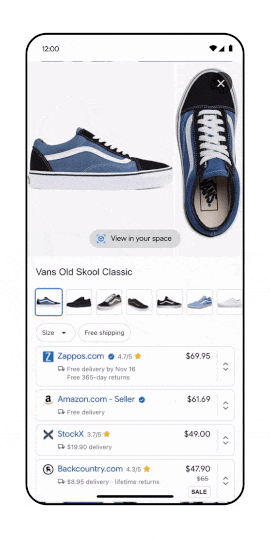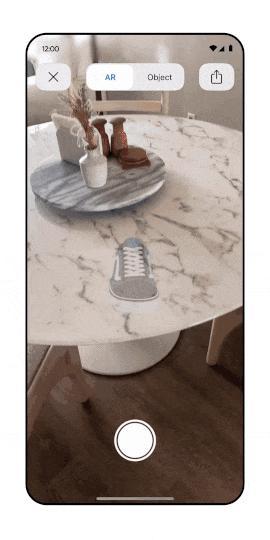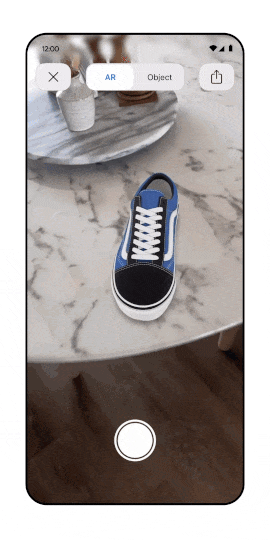
Google and NVIDIA have introduced foundational models to populate virtual worlds and enrich AR/VR experiences. A notable example is GET3D which can generate diverse shapes with arbitrary topology, high-quality geometry, and texture. This area will expand as 3D results on Google will increase. Just recently, Google introduced support for 3D shows models. Google’s senior director of product, shopping Lilian Rincon, has also confirmed that Google is actively working on a technology to facilitate the creation of 3D models more straightforwardly.
Is it already time to talk about Metaverse SEO? For sure AR/VR is becoming an important acquisition channel.
Generative AI Strategy
The flywheel of SEO success
Generative AI is still in its early stages. The model layer is becoming effective thanks to open-source (think of the impact of Stable Diffusion, CLIP, Whisper, and many other freely available models) and well-invested startups like OpenAI, JinaAI, and Hugging Face. However, even when we look at the SEO industry, the application space has barely scratched the surface of what is possible.
Some of the applications that we are building look like the first mobile applications for the iPhone or how websites looked in the nineties. It’s a pioneering phase and an exciting time to live.
To create a sustainable competitive advantage, we are focusing on our niche: AI-native workflows forSEO. As much as the potentials are broad, we don’t see value in doing everything for everyone. We must focus on marketers, content editors, and SEOs to make a real impact. To win, based on the experience we did so far, organizations shall focus on the following:
An exceptional data fabric. Value is extracted when we can fine-tune models and iterate at the speed of light. If we have a knowledge graph, we have a starting point. The chatbot on our website is trained in minutes, with data ingested using a simple query that gets all FAQ content from our blog and all pages inside Read the Docs. When working on an eCommerce website, to validate AI-generated product descriptions, you need a data repository to verify the information quickly. If your data is still in silos, build a data layer first. Integrate this data in an enterprise knowledge graph. Prompting without semantically curated data does not scale.
Continuous prompt improvements and user engagement. You need a magic loop to unleash human creativity and blend it with Generative AI. When people talk to me about AI today, I am primarily interested in two aspects:
What is their interaction paradigm (how humans are involved in the process), and
How is content evaluated? What does the validation pipeline look like?
Ethical values. Potentials are impressive and so are the threats behind these large language models. We need to take great care in planning how to use generative AI. We need to be strong. There are many uncertainties on copyright issues, toxicity, cultural biases and more. We have to be conscious and make sure that users are informed when they read or interact with synthetic content (watermarks for images are a good practice that could be introduced, we might also need to add something specific in schema markup etc.).
Anatomy Of The Perfect Prompt
Every model is a snapshot of the Web (or the chunk of the Web used for its training). Prompting (or prompt engineering), in its very essence, is a reverse-engineered version of the Internet. In a way it reminds us of search engines in the early 2000 where only with the right keyword you could get to the desired results. In prompting, we need to understand what keywords characterize a given expression or an artistic style that we want to reproduce.
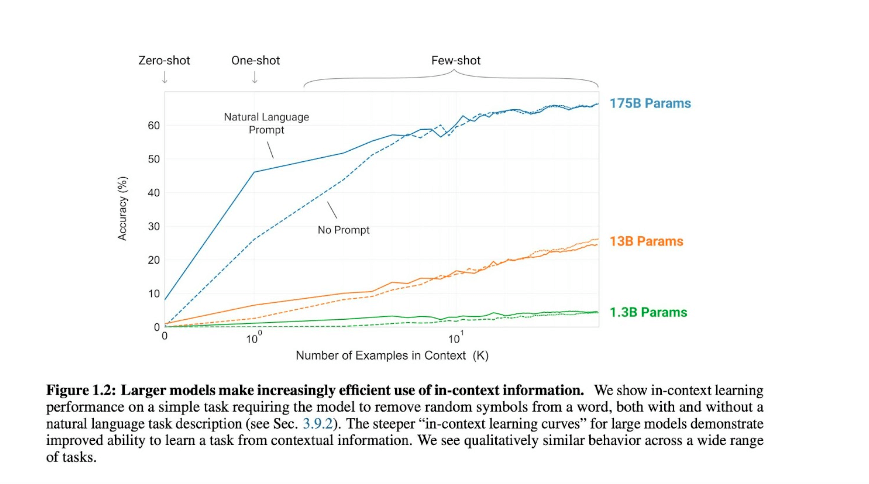
This is an early preview elaborated by David McClure of the corpus of data used for the training of BLOOM – an open source LLM created with the help of EU fundings and HuggingFace. This is a sample of 10 million chunks from the English-language corpus that represent only 1.25% of the information behind BLOOM!As models become larger their ability to provide accurate answers with simple prompts increases.
GPT-3 has revolutionized NLP by introducing the concept of few-shot settings. From the original paper by OpenAI we read:
“We train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting.”
Since then a lot has changed but few principles remain valid across the different models. These principles are applicable for the generation of text as well as images. Let’s review them:
Meta instructions: these are particularly important when using text-to-text models. Things like “Summarize this for a second-grade student” or “write the following text as if you were an expert SEO”. By doing this we can help the model understand the expected output. These initial instructions are becoming more relevant as models evolve. We now have models like FLAN-T5 by Google that are solely trained on instructions and the performances are impressive. Research done on LLM has also exposed the emergent features of these models that can be best expressed by using expressions like “A step by step recipe to make bolognese pasta” or sentences like “Let’s think step by step, what is the meaning of life”.
Large Language Models are Zero-Shot Reasoners
Simply adding “Let’s think step by step” before each answer increases the accuracy on MultiArith from 17.7% to 78.7% and GSM8K from 10.4% to 40.7% with GPT-3.https://t.co/ebvxSbac1Kpic.twitter.com/lpZwDTf06m
— Aran Komatsuzaki (@arankomatsuzaki) May 25, 2022
Content type: these modifiers are very helpful when dealing with CLIP or other models trained with both images and text. For example if I want CLIP to extract features from the image of a product, I will start with “a photograph of”. This will help CLIP understand the type of content I am expecting to analyze or to generate.
Description of the subject: here we want to be as descriptive as possible. This is where we need the Knowledge Graph the most. I need a robust taxonomy with all of its attributes to create a solid description of let’s say a product.
Style: when writing text the style of the writing will be part of the meta instructions. “I want to write [a,b,c] with the style of Allen Ginsberg” would be a good example. When generating images we can refer to the style of a famous painter or a photographer.
When dealing with the generation of images it is also a good practice to injecting materials and techniques using the same language used on well known imagery websites: Digital art, digital painting, color page, featured on pixiv, trending on deviantart, line-art, tarot card, character design, concept art, symmetry, golden ratio, evocative, award winning, shiny, smooth, surreal, divine, celestial, elegant, oil painting, soft, fascinating, fine art.
Format: are we composing poetry or are we generating the cover of a magazine like the digital artist Karen X. Cheng did for the Cosmopolitan? What is the expected format for the generated content? One important part of the prompt would do just that. Helping us define the composition. If we deal with an image this will include aspects like image ratio, camera angle, resolution and even type of lenses or rendering details: ultra wide-angle, wide-angle, aerial view, high-res, depth of field, massive scale, panoramic, fisheye, low angle, extreme close-up, tilt and shift, 4k, 8k, octane rendering. Here is an example of format when dealing with poetry. I just made it up but if you need a rabbit hole, dive into AI poetry generation by the brilliant Gwern.
Additional parameters and weights: every system has its own set of arguments that can be attached at the end of the prompt. To give you a simple example when using Midjourney we can specify the version of it by adding —v 4 or we can typically change the starting point by applying –seed. Also we can define weights for each word inside our prompt. In Stable Diffusion for example anything after ### will be interpreted as a negative prompt (something that we don’t want to see). In GPT-3we can use a function called logit biases to prevent or to incentivize the use of a set of tokens. As models evolve it is interesting to exploit these new areas of opportunity. With the latest version of Midjourney or DALL·E 2 for example we have now the support for image prompts or even multiple prompts at the same time.
Images or other files: we can also add in the prompt a set of images and blend images with text. The model will bring embeddings from both images and text within the same vector space. This opens tremendous opportunities as we can work with multiple modalities. As long as we can compute the embeddings of a file we can use it in a prompt.
Getting Started With Prompt Engineering
Crafting the perfect prompt is becoming an art form and a meaningful way to boost productivity across many fields, from programming to SEO, from content writing to digital art. In the last two years, I have been doing all I could to learn and share the craftsmanship of using prompting. It is a skill for literally anyone. These days, things are evolving fast, and there are new and emerging capabilities in these models that are yet to be discovered, but we also have better tooling to get us started. Here is my list:
Generating featured images for editorial content such as blog posts and news articles is an important part of SEO. Working professionally with foundational models means creating high-quality training datasets. These can be done, only initially manually and eventually needs to scale using semi-automatic workflows.
Results from research by Gao et al., 2022 on the improvement of fine-tuning for increasing accuracy of the model.
Now, suppose you have a particular type of image that you would like to generate. The best option is to fine-tune an image generation model like Stabe Diffusion to generate these types of images. Here below you can see a few examples of the work I am doing with Seppe Van den Berghe, the fantastic illustrator behind our blog covers. The model creates something similar but it is still far from being as good as Seppe. It lacks semantic compositionality in most cases.
You can replicate the same workflow using the code kindly provided as open source by TheLastBenhere.The exciting result so far is that Seppe realizes the possibility of these models and how his creative workflow can change. As usual, while working with generative AI, the journey is more important than the destination. AI-powered art won’t replace illustrators anytime soon. However, illustrators like Seppe realize that technology is close enough that they can adopt some form of Ai-assisted tool to innovate their craft.
The Feedback-Loop Is King (Or Queen Or Both)
When working with Generative AI, we create things and make the work of humans more impactful. Rarely in the last months have we started a project where creators (content editors and SEOs) didn’t change their objectives during the project. We typically begin by replicating their best practices and things they learned from past experiences, and we create something entirely new.
The core of our work is not to replace humans but to expand their capabilities with the help of AI.
How Can We Help Creators Interacting With An AI Model?
Sometimes it is as simple as summarizing search results for a query with the right tone of voice and re-training the model using the provided feedback (i.e., “this is good,” “mhmm, this is not so good,” “This is okayish but not ready for prime time”).
Sometimes it is about turning data into text and encoding existing editorial rules into validation workflows (i.e., “it is ok to use this expression, but we rarely use it,” “don’t mention this when you mentioned that,” etc.). As users interact with your AI model to flag inaccuracies or to check on the quality of the output, your training data becomes more robust, and the quality increases.
On the positive side, LLMs improve significantly as the quality of the training data increases. With a robust model, you can use a limited number of samples (200-400 items can be enough); as the editors provide more input, your training data grows (to thousands of examples), and smaller models can be used. As new models are trained, the validation automatically improves its ability to flag inaccuracy, and more synthetic data can be added to the training.
Future Work
Generative AI in SEO is a strategic asset for online growth. Having a Generative AI strategy in place means focusing on your data fabric and the interaction patterns that help you train small and highly specialized models. Bridging the gaps between LLMs and enterprise business problems is an SEO task.
In its inner nature, SEO is about extensive metadata curation (from nurturing knowledge graphs to publishing structured data) and content optimization. Both skills are in high demand to unlock a wide range of complex enterprise use cases.
We see LLMs evolving into agents and being able to interact with external cognitive assets such as knowledge graphs. Multi-prompt is clearing, opening a new wave of usage patterns for AI models.
What Is A Data Fabric?
A data fabric is a modern data management architecture that allows organizations to quickly use more of their data more often to fuel generative AI, digital transformation, and, last but not least, SEO. Data fabrics are a newer idea, first formally defined in 2016 by Forrester Analyst Noel Yuhanna in his report “Big Data Fabric Drives Innovation and Growth.”
How Can I Make My AI-Generated Images?
For anyone willing to test text-to-image generation or even image-to-image generation here is a list of tools that you can use:
Dream Studio by the same team that released Stable Diffusion;
Diffusion Bee (Mac only) brings you Stable Diffusion on your local computer, this can be helpful when dealing with private images;
DALL·E 2 by OpenAI, the AI system to create realistic images;
Midjourney my favorite pick for AI art generation;
Replicate a startup simplifying the access to AI models by providing an API.
How Can I Optimize My Prompt?
Prompt engineering is a unique interface to foundational models. I don’t expect to see creators disappear, but I hope to see creators at the top of their games becoming very familiar with AI tools and the intricacies of prompt engineering. Here is my list of links to help you improve your prompting skills:
All of this wouldn’t happen without the continuous support from our community of clients and partners experimenting with WordLift to automate their SEO. A big thank you also goes to:
OpenAI, creators of GPT-3, for releasing CLIP and DALL-E (the encoder and decoder parts, specifically) https://github.com/openai/DALL-E/ that I used to generate the featured image of this blog post.
SEO automation is the process of using software to optimize a website’s performance programmatically. This article focuses on what you can do with the help of artificial intelligence to improve the SEO of your website.
Let’s first remove the elephant in the room: SEO is not a solved problem (yet), and while we, as toolmakers, struggle to alleviate the work of web editors on one side while facilitating the job of search engines on the other, SEO automation is still a continually evolving field, and yes, a consistent amount of tasks can be fully automated, but no, the entire SEO workflow is still way too complicated to be entirely automated. There is more to this: Google is a giant AI, and adding AI to our workflow can help us interact at a deeper level with Google’s giant brain. We see this a lot with structured data; the more we publish structured information about our content, the more Google can improve its results and connect with our audience.
When it comes to search engine optimization, we are typically overwhelmed by the amount of manual work that we need to do to ensure that our website ranks well in search engines. So, let’s have a closer look at the workflow to see where SEO automation can be a good fit.
Technical SEO: Analysis of the website’s technical factors that impact its rankings, focusing on website speed, UX (Web Vitals), mobile response, and structured data.
Automation: Here, automation kicks in well already with the various SEO suites like MOZ, SEMRUSH, and WooRank, website crawling software like ScreamingFrog, Sitebulb, etc., and a growing community of SEO professionals (myself included) using Python and JavaScript that are continually sharing their insights and code. If you are on the geeky side and use Python, my favorite library is advertools by @eliasdabbas ? .
On-Page SEO: Title Tag, Meta Descriptions, and Headings.
Automation: Here is where AI/deep learning brings value. We can train language models specifically designed for any content optimization task (i.e., creating meta descriptions or, as shown here by @hamletBatista, title tag optimization). We can also use natural language processing (like we do with WordLift) to improve our pages’ structured data markup ?.
Off-page SEO: Here, the typical task would be creating and improving backlinks.
Automation: Ahrefs backlink checker is probably among the top solutions available for this task. Alternatively, you can write your Python or Javascript script to help you claim old links using the Wayback machine (here is the Python Package that you want to use).
Automation: Here we can create and train a custom Knowledge Graph that makes your on-site search smarter. So, when a user enters a query, the results will be more consistent and respond to the user’s search needs. Also, through Knowledge Graph, you will be able to build landing page-like results pages that include FAQs and related content. In this way, the user will have relevant content, and their search experience will be more satisfying. By answering users’ top search queries and including information relevant to your audience, these pages can be indexed on Google, also increasing organic traffic to your website.
SEO strategy: Traffic pattern analysis, A/B testing, and future predictions.
Automation: here also we can use machine learning for time series forecasting. A good starting point is this blog post by @JR Oaks. We can use machine learning models to predict future trends and highlight the topics for which a website is most likely to succeed. Here we would typically see a good fit with Facebook’s library Prophet or Google’s Causal Impact analysis.
Will Artificial Intelligence Solve SEO?
AI effectively can help us across the entire SEO optimization workflow. Some areas are, though, based on my personal experience, more rewarding than others. Still, again – there is no one size fits all and, depending on the characteristics of your website, the success recipe might be different. Here is what I see most rewarding across various verticals.
Automating Structured Data Markup
Finding new untapped content ideas with the help of AI
Automating Content Creation
Creating SEO-Driven Article Outlines
Crafting good page titles for SEO
Improving an existing title by providing a target keyword
Generating meta descriptions that work
Creating FAQ content on scale
Data To Text in German
Automating SEO Image Resolution
AI-powered Image Upscaler
Automating Product Description Creation
GPT-3 for e-commerce
How to create product description with GPT-3
Automating Structured Data Markup
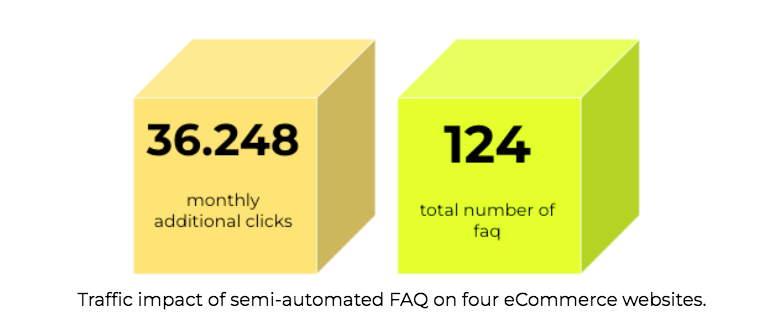
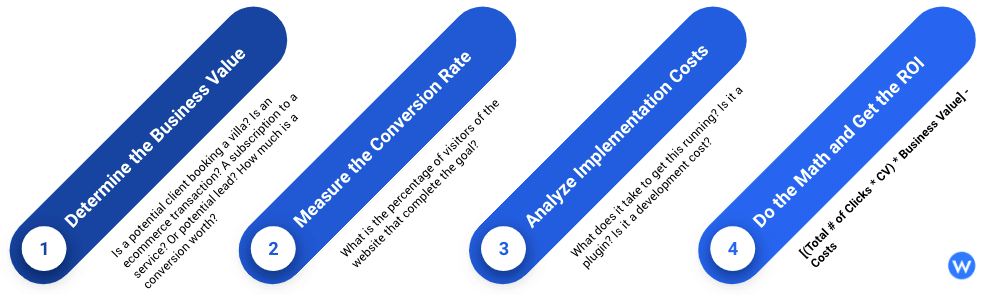
Structured data is one of these areas in SEO where automation realistically delivers a scalable and measurable impact on your website’s traffic. Google is also focusing more and more on structured data to drive new features on its result pages. Thanks to this, it is getting simpler to drive additional organic traffic and calculate the investment return.
Here is how we can calculate the ROI of structured data.
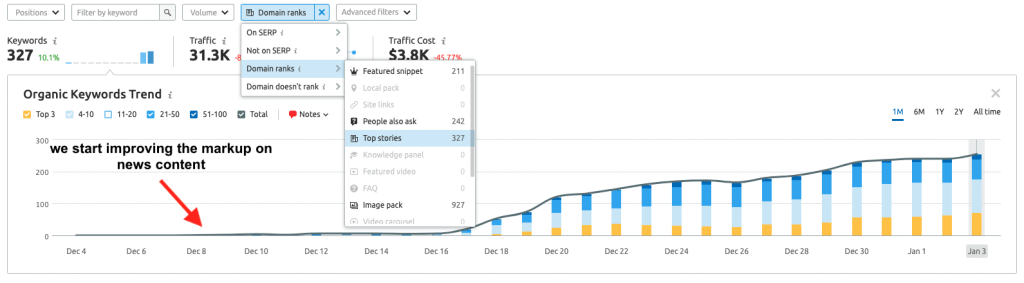
Here is a concrete example of a website where, by improving the quality of structured data markup (on scale, meaning by updating thousands of blog posts), we could trigger Google’s Top stories, to create a newflow of traffic for a news publisher.
Finding new untapped content ideas with the help of AI
There are 3.5 billion searches done every day on Google, and finding the right opportunity is a daunting task that can be alleviated with natural language processing and automation. You can read Hamlet Batista’s blog post on how to classify search intents using Deep Learning or try out Streamsuggest by @DataChaz to get an idea.
Here at WordLift, we have developed our tool for intent discovery that helps our clients gather ideas using Google’s suggestions. The tool ranks queries by combining search volume, keyword competitiveness, and if you are already using WordLift, your knowledge graph. This comes in handy as it helps you understand if you are already covering that specific topic with your existing content or not. Having existing content on a given topic might help you create a more engaging experience for your readers.
Here is where I expect to see the broadest adoption of AI by marketers and content writers worldwide. With a rapidly growing community of enthusiasts, it is evident that AI will be a vital part of content generation. New tools are coming up to make life easier for content writers, and here are a few examples to help you understand how AI can improve your publishing workflow.
Creating SEO-Driven Article Outlines
We can train autoregressive language models such as GPT-3 that use deep learning to produce human-like text. Creating a full article is possible, but the results might not be what you would expect. Here is an excellent overview by Ben Dickson that demystifies AI in the context of content writing and helps us understand its limitations.
Two points: (1) it isn’t very good, and (2) that’s *after* editing by professionals. GPT3 is genuinely impressive but not general AI, and any meaning associated with it is *attributed* to it by *us*. https://t.co/AfNG1HpZ8q
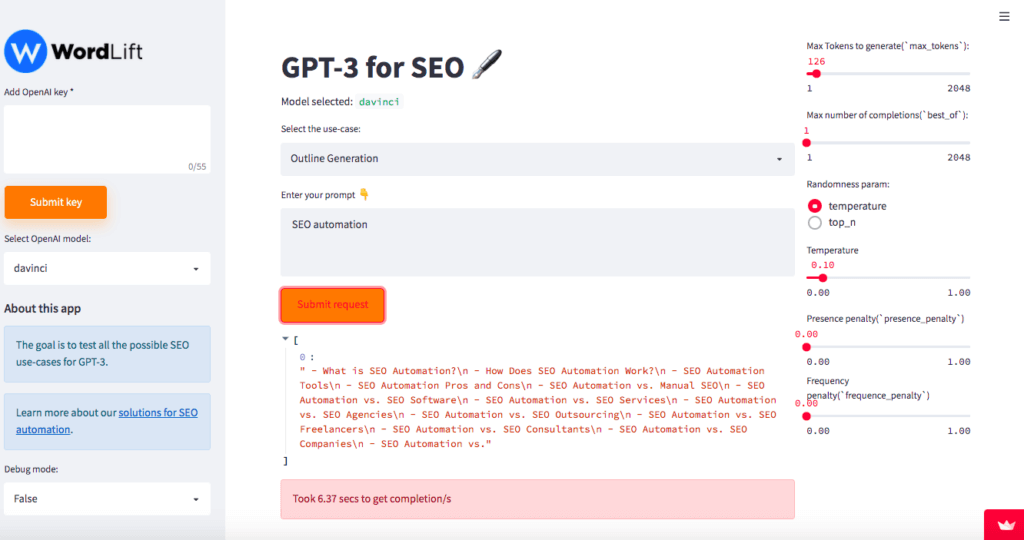
There is still so much that we can do to help writing be more playful and cost-effective. One of the areas where we’re currently experimenting is content outlining. Writing useful outlines helps us structure our thoughts, dictates our articles’ flow, and is crucial in SEO (a good structure will help readers and search engines understand what you are trying to say). Here is an example of what you can actually do in this area.
I provide a topic such as “SEO automation” and I get the following outline proposals:
What is automation in SEO?
How it is used?
How it is different from other commonly used SEO techniques?
You still have to write the best content piece on the Internet to rank, but using a similar approach can help you structure ideas faster.
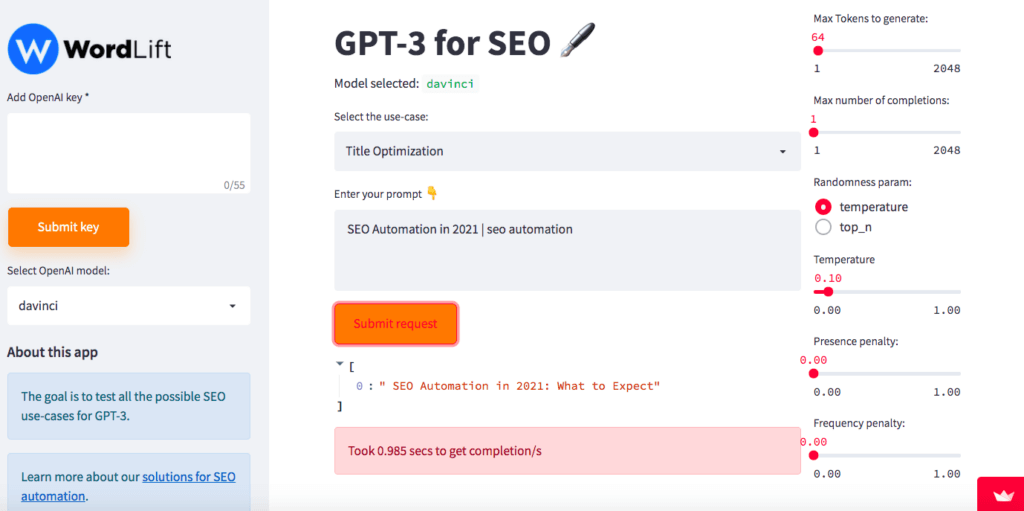
Crafting good page titles for SEO
Creating a great title for SEO boils down to:
helping you rank for a query (or search intent);
entice the user to click through to your page from the search results.
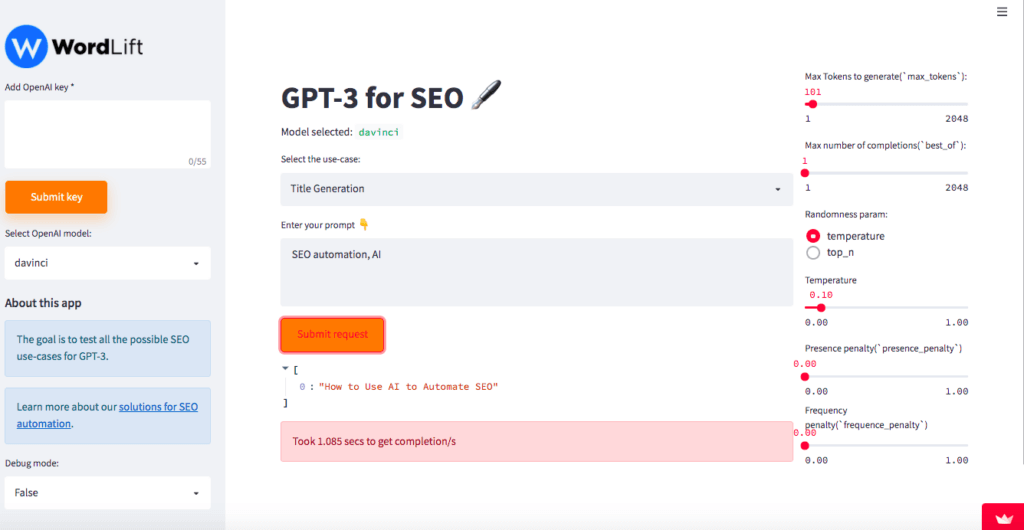
It’s a magical skill that marketers acquire with time and experience. And yes, this is the right task for SEO automation as we can infuse the machine with learning samples by looking at the best titles on our website. Here is one more example of what you can do with this app. Let’s try it out. Here I am adding two topics: SEO automation and AI (quite obviously).
The result is valuable, and most importantly, the model is stochastic, so if we try the same combination of topics multiple times each time, the model generates a new title.
Improving an existing title by providing a target keyword
You can optimize the titles of your existing content by providing a target keyword in order to rank on Google and search engines based on it. For example, suppose I take “SEO automation” as my target keyword for this article and I want to optimize my current content title. Here is the result.
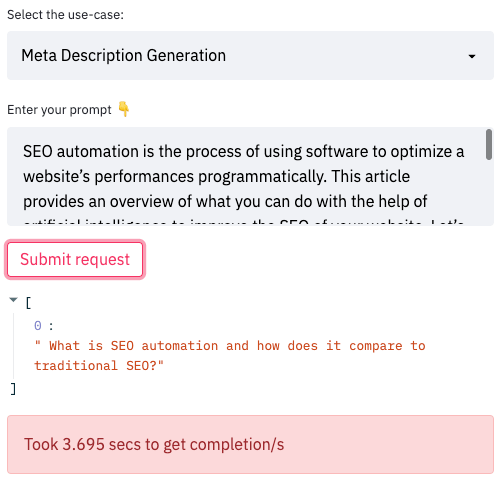
Generating meta descriptions that work
Also, we can unleash deep learning and craft the right snippet for our pages or at least provide the editor with a first draft to start with for meta description. Here is an example of an abstractive summary for this blog post.
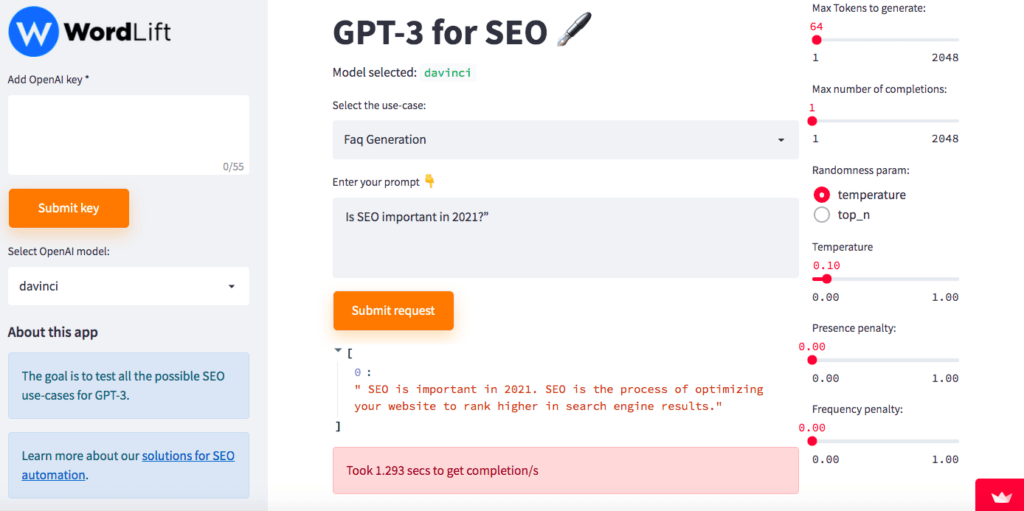
Creating FAQ content on scale
The creation of FAQ content can be partially automated by analyzing popular questions from Google and Bing and providing a first draft response using deep learning techniques. Here is the answer that I can generate for “Is SEO important in 2021?”
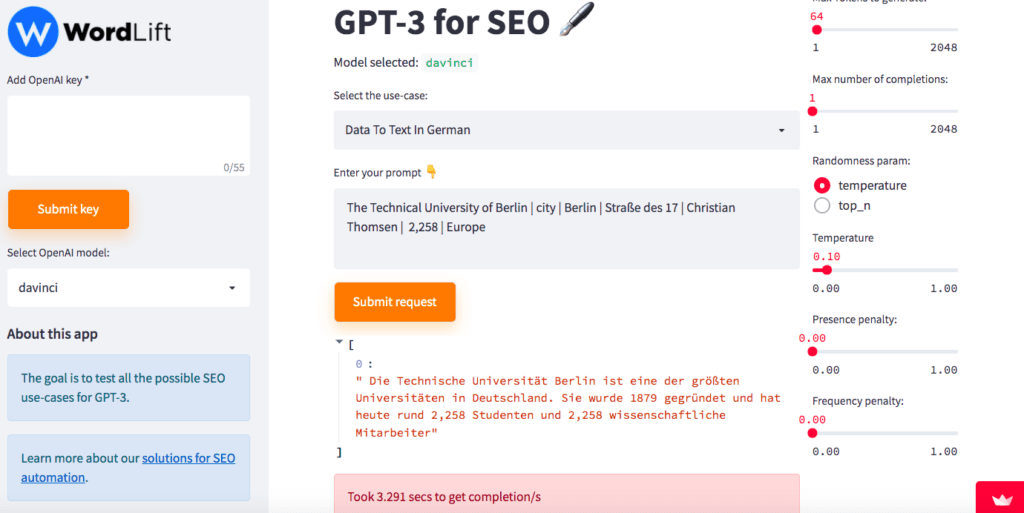
Data To Text in German
By entering a list of attributes, you can generate content in German. For example, in this case, I’m talking about The Technical University of Berlin, and I’ve included a number of attributes that relate to it and this is the result.
DISCLAIMER: Access to the model has been recently opened to anyone via an easy-to-use API and now any SEO can find new creative ways to apply AI to a large number of useful content marketing tasks. Remember to grab your key from OpenAI.
Images that accompany the content, whether news articles, recipes, or products, are a strategic element in SEO that is often overlooked.
In multiple formats (1:1, 4:3 and 16:9), large images are needed by Google to present content in carousels, tabs (rich results across multiple devices) and Google Discover. This is done using structured data and following some essential recommendations:
Make sure you have at least one image for each piece of content.
Make sure the images can be crawled and indexed by Google (sounds obvious but it’s not).
Ensure the images represent the tagged content (you don’t want to submit a picture of roast pork for a vegetarian recipe ?).
Use a supported file format (here’s a list of Google Images supported file formats).
Provide multiple high-resolution images that have a minimum amount of pixels in total (when multiplying one size with the other) of:
50,000 pixels for Products and Recipes
80,000 pixels for News Articles
Add the same image in the structured data in the following proportions: 16×9, 4×3, and 1×1.
AI-powered Image Upscaler
With Super-Resolution for Images, you can enlarge in and enhance images from your website using a state-of-the-art deep learning model.
WordLift automatically creates the required version of each image in the structure data markup in the proportions 16×9, 4×3 and 1×1. The only requirement is that the image is on the smaller side by at least 1,200 pixels.
Since this isn’t always possible, I came up with a workflow and show you how it works here.
The code is fairly straightforward so I will explain how to use it and a few important details. You can simply run the steps 1 and 2 and start processing your images.
Prior to doing that you might want to choose if to compress the produced images and what level of compression to apply. Since we’re working with PNG and JPG formats we will use the optimize=True argument of PIL to decrease the weight of images after their upscaling. This option is configurable as you might have already in place on your website an extension, a CDN or a plugin that automatically compresses any uploaded image.
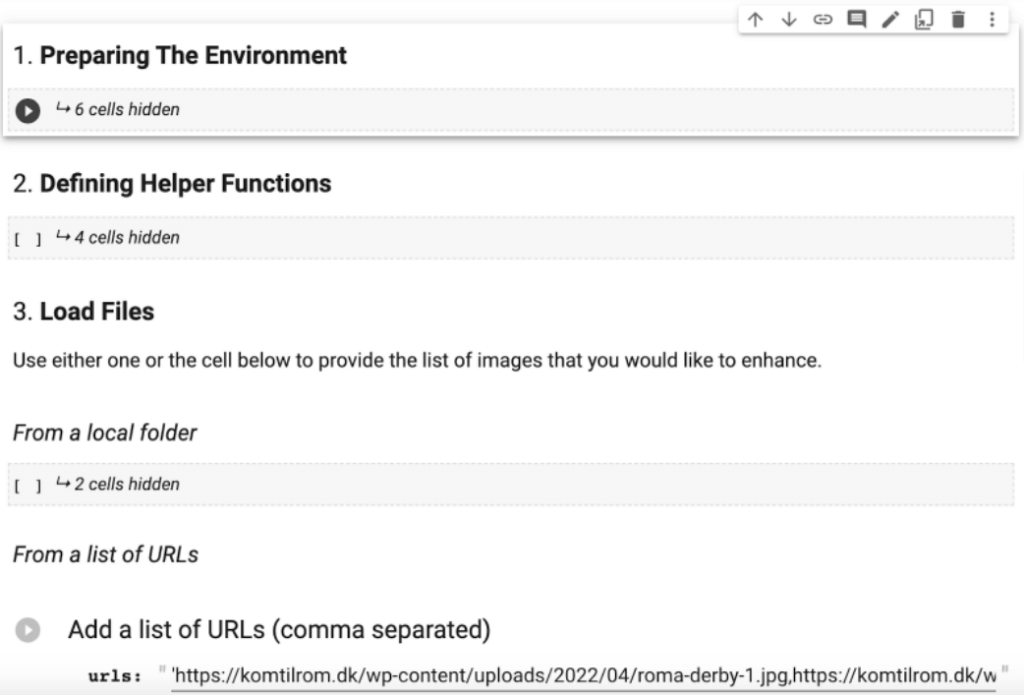
You can choose to disable (the default is set to True) the compression or change the compression level using the form inside the first code block of the Colab (1. Preparing the Environment).
2. Loading the files
You can upload the files that you would like to optimize by either:
A folder on your local computer
A list of comma separated image URLs
In both cases you are able to load multiple files and the procedure will keep the original file name so that you can simply push them back on the web server via SFTP.
When providing a list of URLs the script will first download all the images in a folder, previously created and called input.
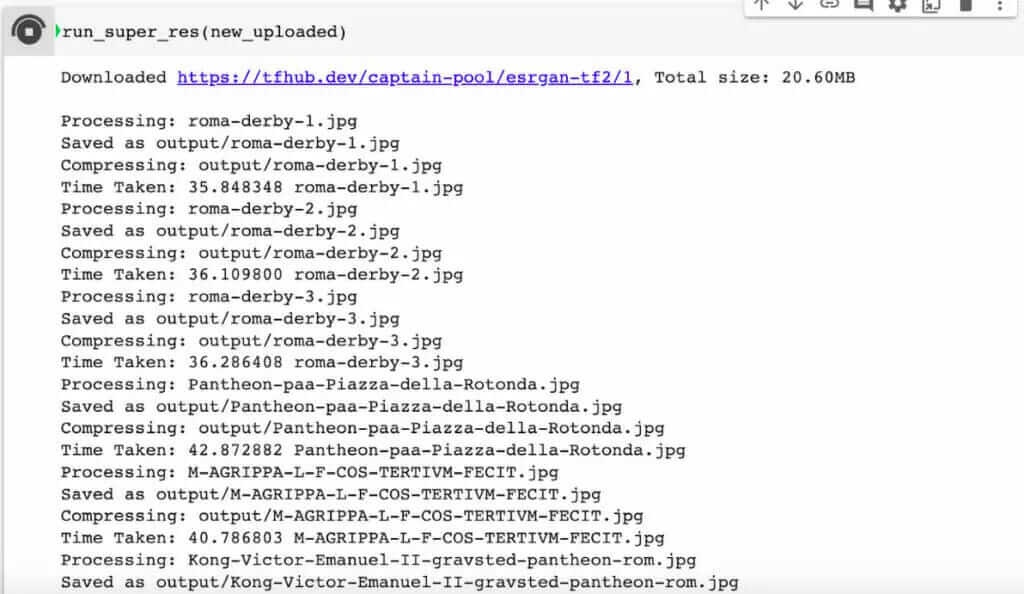
Once all images have been downloaded you can run the run_super_res() function on the following block. The function will first download the model from TF Hub and then will start increasing the resolution of all the images x4. The resulting images will be stored (and compressed if the option for compression has been kept to True) in a folder called output.
Once completed you can zip all the produced files contained in the output folder by executing the following code block. You can also change the name of the zipped file and eventually remove the output folder (in case you want to run it again).
To discover the results achieved in our first test of this AI-powered Image Upscaler, we recommend reading our article on how to use the Super-Resolution technique to enlarge and enhance images from your website to improve structured data markup by using AI and machine learning.
Automating product description creation
AI writing technology has made great strides, especially in recent years, dramatically reducing the time it takes to create good content. But human supervision, refinements, and validations remain crucial to delivering relevant content. The human in the loop is necessary and corresponds to Google’s position on machine learning-generated content, as mentioned by Gary Illyes and reported in our web story on machine-generated content in SEO.Right now our stance on machine-generated content is that if it’s without human supervision, then we don’t want it in search. If someone reviews it before putting it up for the public then it’s fine.
GPT-3 for e-commerce
GPT-3 stands for Generative Pre-trained Transformer. It is an auto-regressive language model that uses deep learning to produce human-like text. OpenAI, an AI research and deployment company, unveiled this technology with 175 billion language parameters. It is the third-generation language prediction model in the GPT-n series and the successor to GPT-2, created by Microsoft-funded OpenAI.
You can use GPT-3 for many uses, including creating product descriptions for your e-commerce store.
How to create product description with GPT-3
GPT-3 can predict which words are most likely to be used next, given an initial suggestion. This allows GPT-3 to produce good sentences and write human-like paragraphs. However, this is not an out-of-the-box solution to perfectly drafting product descriptions for an online store.When it comes to customizing GPT-3’s output, fine-tuning is the way to go. There is no need to train it from scratch. Fine-tuning allows you to customize GPT-3 to fit specific needs. You can read more about customizing GPT-3 (fine-tuning) and learn more about how customization improves accuracy over immediate design (learning a few strokes). Fine-tuning GPT-3 means providing relevant examples to the pre-trained model. These examples are the ideal descriptions that simultaneously describe the product, characterize the brand, and set the desired tone of voice. Only then could companies begin to see real value when using AI-powered applications to generate product descriptions. Examples of the power of GPT-3 for e-commerce product descriptions are in this article, where we show you two different cases:
Using the pre-trained model of GPT-3 without fine-tuning itFine-tuning the pre-trained model with relevant data
Here is how you can proceed when approaching SEO automation. It is always about finding the right data, identifying the strategy, and running A/B tests to prove your hypothesis before going live on thousands of web pages.
It is also essential to distinguish between:
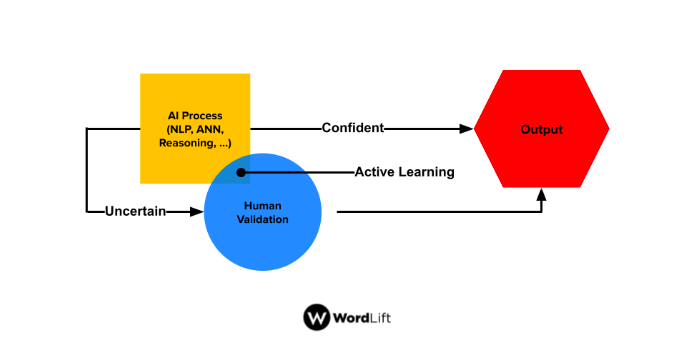
Deterministic output – where I know what to expect and
Stochastic output – where the machine might generate a different variation every time, and we will need to keep a final human validation step.
I believe that the future of SEO automation and the contribution of machine/deep learning to digital marketing is now. SEOs have been automating their tasks for a while now, but SEO automation tools using AI are just starting to take off and significantly improve traffic and revenues.
The image we used in this blog post is a series of fantastical objects generated by OpenAI’s DALL·E new model by combining two unrelated ideas (clock and mango).
How can we organize the taxonomy of a website to make it easier to find in search engines? What can we do with entities and what can we expect when we annotate content with them? This is the story of William Green, who founded Poem Analysis in 2016 with the goal of giving poetry a home online. William had noticed that there were not enough online resources about poetry and that people were still struggling to understand and appreciate it because they were not being helped to study it in depth.
The first important step was to create a well-organized website. But, as we know, a website without visibility is like an empty house. So, the biggest challenge at that time was to gain more and more visibility on Google and the search engines. So while a website must be designed for the user, the content that fills it must also be understandable to search engines. In this way, Google can index it and the website can get a good ranking that will bring it more visitors.
When William came across WordLift, he knew there was untapped potential here. He knew Schema.org and had already tried solutions that allowed him to annotate content and add structured data to the website, but he had not yet found the solution that could really make a difference. Let’s see closer this SEO case study.
WordLift brought its innovation, both in approach and technology.
“The ability to add entities on a scale like no other is something that every website owner should get excited about. Helping Google understand content better, and make the links, will only benefit the website, where schema is becoming a more dominant force for search engines, and into the future.
It was and is a pleasure to work with WordLift on cutting-edge SEO, particularly with such a quick thinking an Agile team. In doing so, we are able to test and create experiments that produce incredible results before most have even read new SEO schemas”.
William Green – Poem Analysis
The challenge
The goal of Poem Analysis was to achieve better ranking on Google and search engines and get more organic traffic to the website. The real challenge was to find a solution that would scale quickly and systematically given the large amount of content on the site.
It was also about increasing relevancy, making sure that Google was able to capture the right queries. It seems obvious at the beginning but, really, it is not when you look at each individual poem. Google might know who Allen Ginsberg is but might struggle to connect ‘Howl’ (one of Allen’s poems) to him.
The solution
For PoemAnalysis.com we used a version of WordLift specifically created for publishers in the CafeMedia/AdThrivenetwork.
The solution proposed by the WordLift team started from the idea of using the pre-existing taxonomyand tointegrate and inject structured data through “match terms”. This means that you can enrich your site by using categories and tags without having to use WordLift’s content classification panel to add markup. This way, a tag or category is treated like a recognized entity in the content classification box.
For PoemAnalysis.com we created a custom solution to achieve this goal and in this way, we used the well organized taxonomy of the websites to associate the entity correspondent to the category of the poet (e.i. The category of William Shakespeare has been associated with the Wikidata correspondent entity). Specifically, this was done here with Authors.
In a second testing phase, we decided to add the SameAs of the poem to the page of the poem (e.i. Shakespeare’s Sonnet 19 associated with the correspondent wikidata and DBPedia). The items we marked in the SameAs field are converted by WordLift into meaningful links to Wikidata and DBpedia. Subsequently, the Poem Analysis editorial team added SameAs to all entities on the site.
We are now working to add “Quiz” markup for Education Q&A, a format that helps students better find answers to educational questions. With structured data, the content is eligible to appear in the Education Q&A carousel in Google Search, Google Assistant, and Google Lens results. Stay tuned!
The results
As we saw in the previous section, the WordLift team worked on two actions that had a positive and measurable impact on Poem Analysis’ SEO strategy.
In the first case, the existing, well-organized taxonomy was used with the “Match Terms” feature to convert categories into entities, which were then annotated in the site content. To measure the impact of this first experiment, a control group was created that included a set of unannotated Poets with WordLift markup.
The semantic annotation brought +13% of clicks and +29.3% of impressions when comparing this year to last year. In this case, we did not include the control group, because after we did follow-ups for these URLs as well, the data is not statistically relevant at the moment (in the expansion of the experiment we moved most of the URLs of the control group into the variant group, so to date, only 5 URLs remain within the control group).
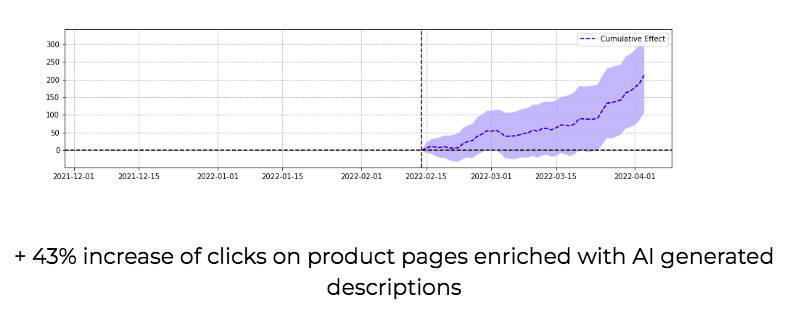
In the second case, the WordLift team worked on SameAs of the poem to the page of the Poem. Again, to measure impact, we created a control group containing a set of Poems not annotated. Using SameAS brought +59.3% of clicks and +82.9% of impressions.
The semantic annotation of the content also allowed another result: if you type the whole poem in Google, the first result that appears is poem analysis🤩
Example: William Shakespeare’s Sonnet 19
Conclusion
The story of William shows the impact of semantic annotation and how building a well-organized taxonomy helps semantic annotation of content have a positive impact on a website’s impressions and traffic.
In this case, we used the well-structured and indexed tags and categories as entities to annotate the website content. Generally, it is important that the entities are relevant and indexed by search engines to create the right sidewalk that moves both Google and the user.
Let us not forget that semantic content annotations add value to the user by providing them with information and insights that they would otherwise have to look for elsewhere. And, of course, it also creates a semantic path for Google, which can thus more easily assemble the concepts surrounding a piece of content and rank it by reinforcing the topical authority on that topic.
![From Strings to Things: SEO Add-On for Google Sheets by WordLift [New Release]](https://wordlift.io/ng/wp-content/uploads/sites/2/2023/08/seo-addon-for-google-sheets-by-wordlift-980x551_11zon.jpg)



















Recent Comments