
Generative AI For SEO: An Overview
AI researchers have made tremendous strides in building language models that generate coherent text. A seminal paper introduced in 2017 by the Google Research team (“Attention is All You Need”) introduced a new neural network architecture for natural language understanding called transformers that can generate high quality language models with significantly less time for training.
| I worked on a presentation for Brighton SEO to get you started with Transformer-based language models: [Presentation] – SEO Automation Using GPT3 and Transformer Based Language Models Slides [Colab] – Code to understand how things work behind the scenes |
These models have been harnessed to tackle a wide range of problems, from open-ended conversations to solving math problems, from poetry to SEO tasks like writing product descriptions. Generative AI comprises, alongside text generation, other abilities that a powerful new class of large language models enables: from writing code to drawing, from creating photo-realistic marketing materials to creating 3D objects, from producing video content to synthesizing and comprehending spoken language with an unprecedented quality.
This blog post provides an overview of Generative AI and how it can potentially be used in the context of SEO.
I have been generating synthetic images for almost two years with diffusion based models. Our team here at WordLift creates thousands of AI. content snippets every month, from product descriptions to FAQs, from short summaries to introductory text. We actively collaborate with companies like OpenAI, Microsoft, and Jina AI to scale these workflows for our clients (SMEs and enterprises).

Satya Nadella and Sam Altman from Open AI during Microsoft Ignite 2022 (WordLift is there!!)
Here is the table of content, so you can skim through the article:
- Generative AI: the uncanny ability to generate…everything
- AI-Powered SEO Workflows
- Generative AI strategy
- Anatomy of the perfect prompt
- Fine-tuning the models – the cover experiment
- The feedback-loop is King (or Queen or both)
- Future work
- Credits and special thanks
Introducing Generative AI for SEO
One way to look at the evolution of Generative AI is to map key innovations in the field of LLMs and see how they can be potentially used in specific SEO workflows.
Below, I highlighted the foundational models that can have an impact in the different areas of SEO (from entity SEO to programmatic, from Google Lens to 3D Serps) and the potential workflows that we can build on top.

AI-Powered SEO Workflows
Text Models
This is where the state of art is the most advanced, and the adoption is increasing faster. Models are incredibly diverse, and each one has its characteristics, but generally speaking, depending on the workflow, you can either start with a simple prompt (also called zero-shot), provide a more elaborate set of instructions (few-shots training), or fine-tune your model. Here is how you can use generative models that work with text.
Internal Links
In SEO, internal links remain a valuable asset as they help search engines understand the structure of a website and the relationships between different pages. They also help to improve the user experience by providing a way for users to navigate between the different pages. We can take into account semantic similarity, entities and what people are searching on our website to make these links effective. Here is a blog post about automating internal links for eCommerce websites using LLM.
FAQ Generation
Adding content in the form of questions and answers has become a great tactic in SEO. As Google becomes more conversational, questions and answers marked up with structured data provide searchers with more relevant content in various contexts: from the people also ask block to FAQ-rich results, featured snippets, and even the Google Assistant.
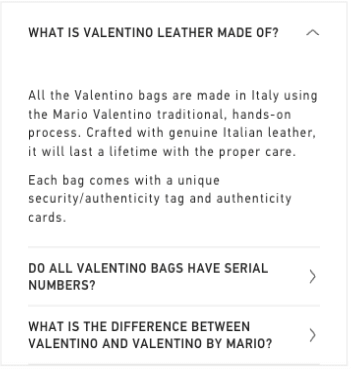
An example of automated FAQ for a luxury brand.
Workflows here have become highly sophisticated and take advantage of multiple AI models to help editors in the different areas of the work: from researching the topic to planning, from writing the answer to reviewing it, adding internal links, and validating the tone of voice.
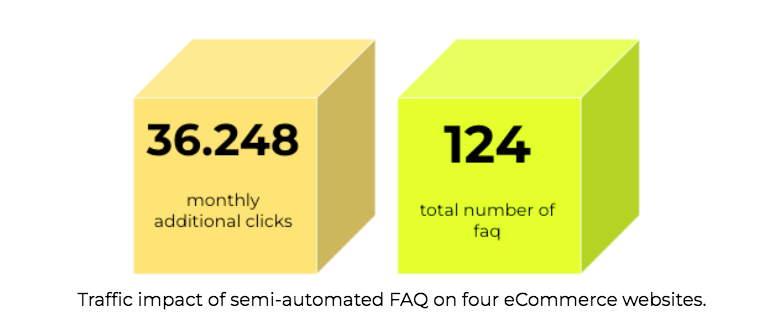
Product Descriptions
Language models are perfect for creating high-quality product descriptions for eCommerce websites to fuel sales. The short form and stylized nature of product descriptions are an ideal fit when combined with the time and cost pressures on editorial teams working on thousands of products daily. The game-changer when creating product descriptions using models like GPT-3 by OpenAI or J1 by AI21 is the vertical integration of product data and the ability to craft UX patterns for fast feedback loops.
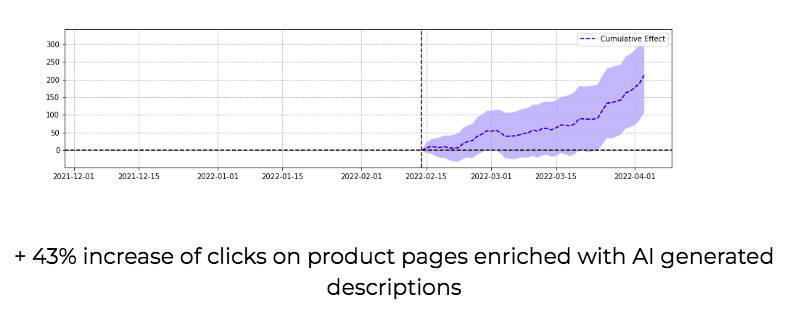
Summarization
Starting in 2019, I began using BERT-like models for automating the creation of meta descriptions. We can quickly summarize a lengthy blog post. Can we help editors accelerate their research by summarizing the top search results? The impact of text summarization in SEO is enormous.

How WordLift uses extractive summarization to improve the UX on blog posts.
Introductory Text
Can we describe the content of a category page using a fine-tuned LLM? Is it possible to personalize content to make it more likely to be of interest to a specific target audience? Generating short form content is a great way to use foundational models.
Structured Data Automation
Graph enrichment is becoming essential to gain new features in the SERP and to help search engines understand the content and the relationship between entities. From named entity recognition to topic extraction, we can turbocharge schema markup with the help of RoBERTA, spaCY, and the WordLift NLP stack.
Chatbot
LLMs are becoming strategic in conversational AI or chatbots. They have the potential to provide a better understanding of conversations and context awareness. One of Google’s engineers was even (wrongly) convinced that an LLM like Google LaMDA could be considered conscious. SEO is an important aspect when creating a conversational experience. Why? As we work extensively to train Google with question-answer pairs, we can re-use the same data (and the same methodology) to train our own AI system.
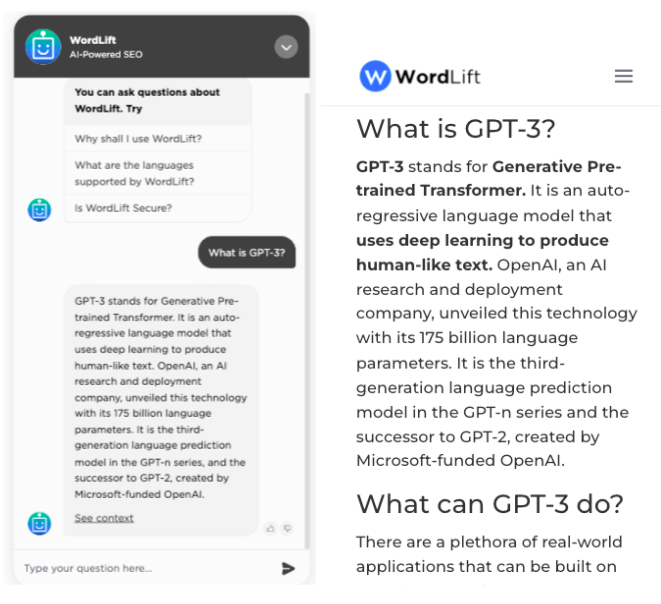
The chatbot on our documentation website (on the left) extracts answers from the blog post (on the right) and helps users find the right information. It works like a search engine and like every search engine, SEO is a blessing.
One way to provide contextual information when constructing an AI-powered conversational agent, such as a shopping assistant, is to combine the structured world of knowledge graphs with the fluent, context-aware capabilities of language models (LMs). This fusion, which we call neurosymbolic AI, makes it possible to transform the user experience by creating personalized conversations that were previously unthinkable.
We have developed a new connector, WordLift Reader, for LlamaIndex and LangChain to transform static and structured data into dynamic and interactive conversations.
With only a few lines of code, we can specify exactly what data we need by extracting from our KG the sub-graphs we want. We do this by using specific properties of the schema.org vocabulary (or any custom ontology we use).
The connector uses GraphQL to load data from the KG, this ensures conversations are always up-to-date with the latest changes to the website, without the need for crawling.
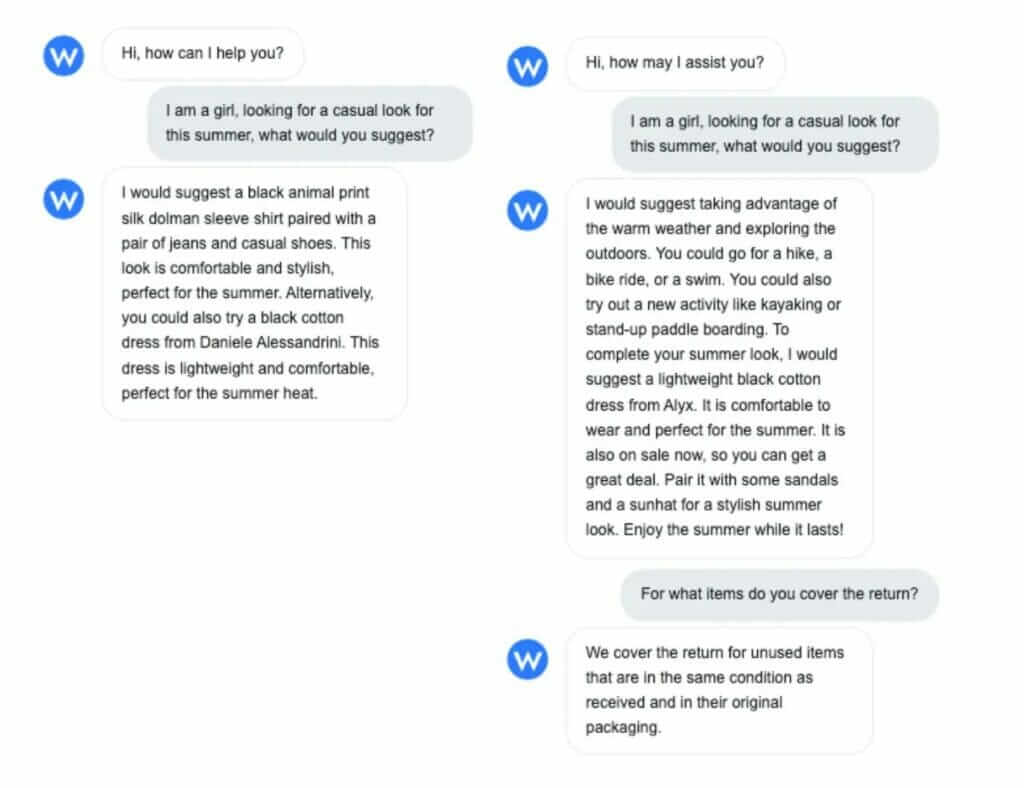
The following example is a shopping assistant built using this approach. As can be seen, the combination of multiple schema classes helps the AI to respond to multiple intents:
- schema:Product to recommend products
- schema:FAQPage (on this site) to answer questions about the store’s return policy
Code Models
They are already having a significant impact on developers’ productivity, as demonstrated by a recent study by GitHub. Developers feel more fulfilled when they use AI in pair-programming mode. There are still several concerns about IP violations that models like GitHub Copilot introduce, and too little has been done to address these problems. Nevertheless, also in the SEO industry, they are starting to play a role.
Text to Regex
One very simple use case is to convert plain english to regex to help you filter data in Google Search Console. Danny Richman got you covered and if you want to learn more here is his recipe.
Text to Structured Data
I trained the first model a couple of years ago using GPT-2 and right now using Codepilot things are getting a lot simpler. These solutions are very helpful to sketch the JSON-LD that you would like to get.
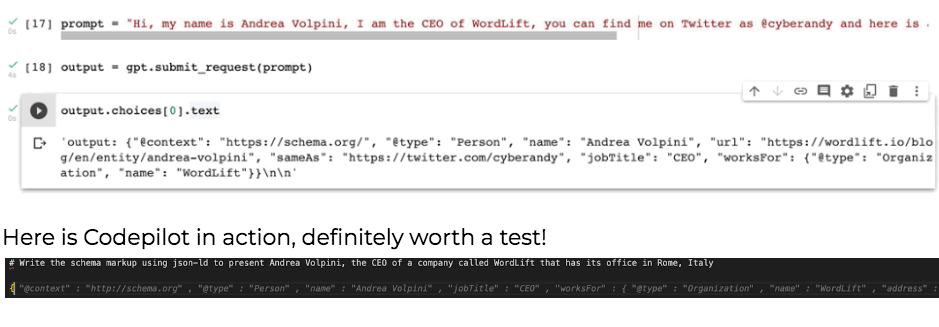
Image Models
Generative AI models for image generation are revolutionizing the content industry. We have seen AI-generated images going viral in only a few months and even winning fine art competitions. Each model has its unique touch; you will get more fantasy-like images from Midjourney and more realistic results from DALL·E 2 or Stable Diffusion. All models share the same understanding of the world, and this is encoded into CLIP, a Contrastive Language-Image Pre-Training by Open AI trained on a vast amount of (image, text) pairs. CLIP can be instructed to analyze the semantic similarity between an image and a text. If you genuinely want to understand how AI models for generating images work, CLIP is where to start.
| Here is an introductory Colab that you can use to see how CLIP works (powered by Jina AI): [Colab] – Code to experiment with CLIP |
Super Resolution
One very simple thing to do, in the context of SEO, is to use AI models to increase the resolution of images associated with blog posts or products.

SEO image optimization, especially when combined with structured data, helps increase click through rate.
| Here is a blog post and the code to get you started with image upscaling: [Blog Post] – AI-powered Image Upscaler [Colab] – Code to upscale images in batches |
Visual Inference
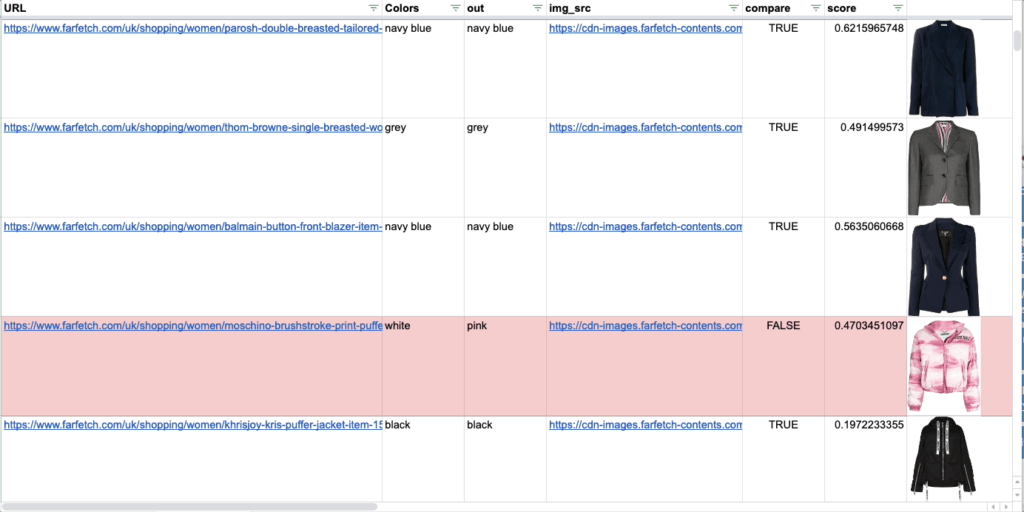
Imagine the potential to automate extensive evaluation on large product catalogs by training a model that can analyze images and verify that there is a correspondence with the text that describes each product. This is what we are doing using pre-trained CLIP models.
Generating Product Images
Investing on image quality for retail stores is usually an easy win for SEOs. The technology is not yet there but there are some interesting startups like vue.ai focusing on this use case and I expect we will have something ready for our clients within a few months. Typically you will focus on:
- Generating images in different context (changing the background, changing the style)
- Generating on-model product imagery
- Creating images from different angles

Video Models
Progress made on the text-to-image generation field paved the way to text-to-video generation. There are models already in this field by Microsoft, Meta and recently also Google. Make-a-video by Meta AI is an interesting experiment that present the state of the art in this sector.
Speech Models
As CLIP has been revolutionary for images, Whisper, a general-purpose speech recognition model by OpenAI, is impactful for audio and audio video. Whisper has been trained on 680,000 hours of multilingual and multitask supervised data, bringing automatic speech recognition (ASR) to a new level. You can, as in the example below, automatically add subtitles in English to a video in German or summarize it in a few sentences.

| Here is the code to get you started with Whisper and YouTube optimization: [Colab] – Code to transcribe a YouTube video, produce subtitles, generate a summary and extract questions and answers. |
3D Models
Google and NVIDIA have introduced foundational models to populate virtual worlds and enrich AR/VR experiences. A notable example is GET3D which can generate diverse shapes with arbitrary topology, high-quality geometry, and texture. This area will expand as 3D results on Google will increase. Just recently, Google introduced support for 3D shows models. Google’s senior director of product, shopping Lilian Rincon, has also confirmed that Google is actively working on a technology to facilitate the creation of 3D models more straightforwardly.
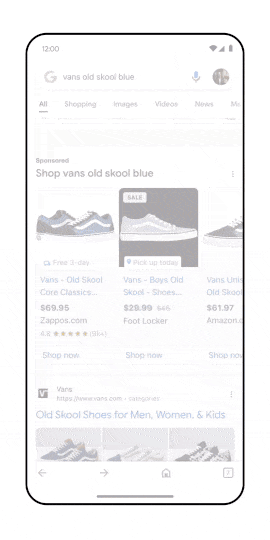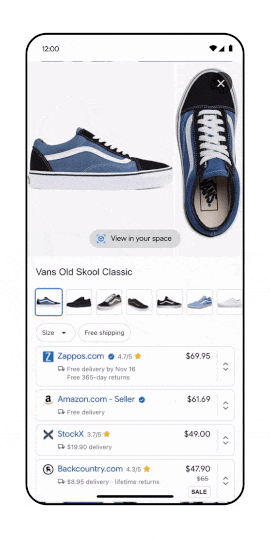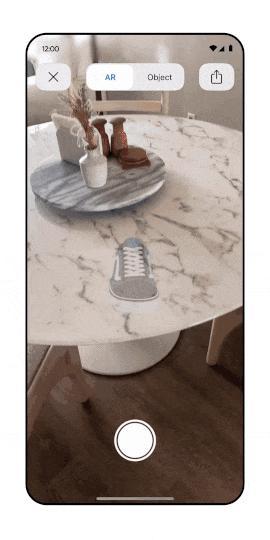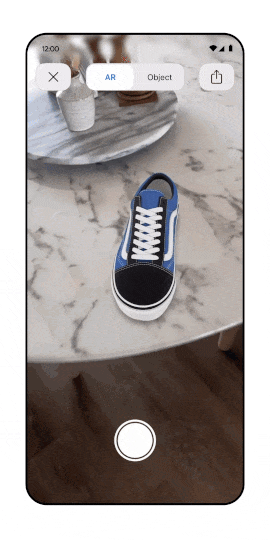
Is it already time to talk about Metaverse SEO? For sure AR/VR is becoming an important acquisition channel.
Generative AI Strategy
The flywheel of SEO success
Generative AI is still in its early stages. The model layer is becoming effective thanks to open-source (think of the impact of Stable Diffusion, CLIP, Whisper, and many other freely available models) and well-invested startups like OpenAI, JinaAI, and Hugging Face. However, even when we look at the SEO industry, the application space has barely scratched the surface of what is possible.
Some of the applications that we are building look like the first mobile applications for the iPhone or how websites looked in the nineties. It’s a pioneering phase and an exciting time to live.
To create a sustainable competitive advantage, we are focusing on our niche: AI-native workflows for SEO. As much as the potentials are broad, we don’t see value in doing everything for everyone. We must focus on marketers, content editors, and SEOs to make a real impact. To win, based on the experience we did so far, organizations shall focus on the following:
- An exceptional data fabric. Value is extracted when we can fine-tune models and iterate at the speed of light. If we have a knowledge graph, we have a starting point. The chatbot on our website is trained in minutes, with data ingested using a simple query that gets all FAQ content from our blog and all pages inside Read the Docs. When working on an eCommerce website, to validate AI-generated product descriptions, you need a data repository to verify the information quickly. If your data is still in silos, build a data layer first. Integrate this data in an enterprise knowledge graph. Prompting without semantically curated data does not scale.
- Continuous prompt improvements and user engagement. You need a magic loop to unleash human creativity and blend it with Generative AI. When people talk to me about AI today, I am primarily interested in two aspects:
- What is their interaction paradigm (how humans are involved in the process), and
- How is content evaluated? What does the validation pipeline look like?
- Ethical values. Potentials are impressive and so are the threats behind these large language models. We need to take great care in planning how to use generative AI. We need to be strong. There are many uncertainties on copyright issues, toxicity, cultural biases and more. We have to be conscious and make sure that users are informed when they read or interact with synthetic content (watermarks for images are a good practice that could be introduced, we might also need to add something specific in schema markup etc.).
Anatomy Of The Perfect Prompt
Every model is a snapshot of the Web (or the chunk of the Web used for its training). Prompting (or prompt engineering), in its very essence, is a reverse-engineered version of the Internet. In a way it reminds us of search engines in the early 2000 where only with the right keyword you could get to the desired results. In prompting, we need to understand what keywords characterize a given expression or an artistic style that we want to reproduce.

This is an early preview elaborated by David McClure of the corpus of data used for the training of BLOOM – an open source LLM created with the help of EU fundings and HuggingFace. This is a sample of 10 million chunks from the English-language corpus that represent only 1.25% of the information behind BLOOM!As models become larger their ability to provide accurate answers with simple prompts increases.
GPT-3 has revolutionized NLP by introducing the concept of few-shot settings. From the original paper by OpenAI we read:
“We train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting.”
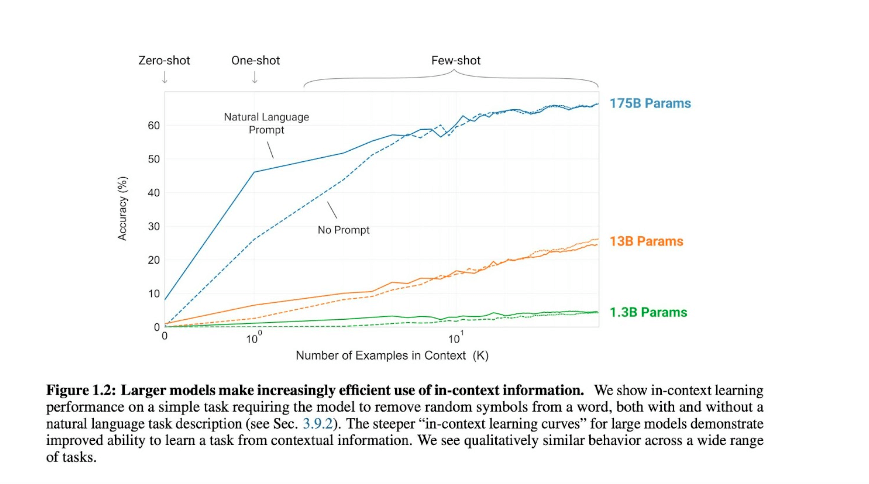
Since then a lot has changed but few principles remain valid across the different models. These principles are applicable for the generation of text as well as images. Let’s review them:
- Meta instructions: these are particularly important when using text-to-text models. Things like “Summarize this for a second-grade student” or “write the following text as if you were an expert SEO”. By doing this we can help the model understand the expected output. These initial instructions are becoming more relevant as models evolve. We now have models like FLAN-T5 by Google that are solely trained on instructions and the performances are impressive. Research done on LLM has also exposed the emergent features of these models that can be best expressed by using expressions like “A step by step recipe to make bolognese pasta” or sentences like “Let’s think step by step, what is the meaning of life”.
- Content type: these modifiers are very helpful when dealing with CLIP or other models trained with both images and text. For example if I want CLIP to extract features from the image of a product, I will start with “a photograph of”. This will help CLIP understand the type of content I am expecting to analyze or to generate.
- Description of the subject: here we want to be as descriptive as possible. This is where we need the Knowledge Graph the most. I need a robust taxonomy with all of its attributes to create a solid description of let’s say a product.
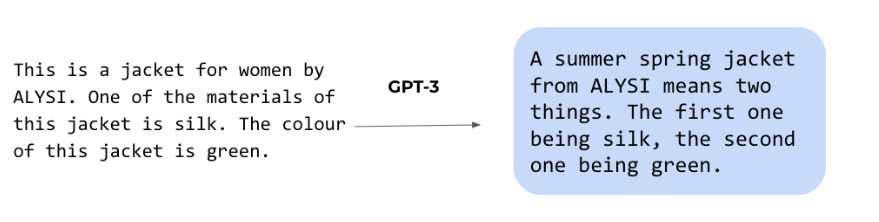
- Style: when writing text the style of the writing will be part of the meta instructions. “I want to write [a,b,c] with the style of Allen Ginsberg” would be a good example. When generating images we can refer to the style of a famous painter or a photographer.
- When dealing with the generation of images it is also a good practice to injecting materials and techniques using the same language used on well known imagery websites:
Digital art, digital painting, color page, featured on pixiv, trending on deviantart, line-art, tarot card, character design, concept art, symmetry, golden ratio, evocative, award winning, shiny, smooth, surreal, divine, celestial, elegant, oil painting, soft, fascinating, fine art.
- When dealing with the generation of images it is also a good practice to injecting materials and techniques using the same language used on well known imagery websites:
- Format: are we composing poetry or are we generating the cover of a magazine like the digital artist Karen X. Cheng did for the Cosmopolitan? What is the expected format for the generated content? One important part of the prompt would do just that. Helping us define the composition. If we deal with an image this will include aspects like image ratio, camera angle, resolution and even type of lenses or rendering details:
ultra wide-angle, wide-angle, aerial view, high-res, depth of field, massive scale, panoramic, fisheye, low angle, extreme close-up, tilt and shift, 4k, 8k, octane rendering. Here is an example of format when dealing with poetry. I just made it up but if you need a rabbit hole, dive into AI poetry generation by the brilliant Gwern.

- Additional parameters and weights: every system has its own set of arguments that can be attached at the end of the prompt. To give you a simple example when using Midjourney we can specify the version of it by adding —v 4 or we can typically change the starting point by applying –seed. Also we can define weights for each word inside our prompt. In Stable Diffusion for example anything after ### will be interpreted as a negative prompt (something that we don’t want to see). In GPT-3we can use a function called logit biases to prevent or to incentivize the use of a set of tokens. As models evolve it is interesting to exploit these new areas of opportunity. With the latest version of Midjourney or DALL·E 2 for example we have now the support for image prompts or even multiple prompts at the same time.
- Images or other files: we can also add in the prompt a set of images and blend images with text. The model will bring embeddings from both images and text within the same vector space. This opens tremendous opportunities as we can work with multiple modalities. As long as we can compute the embeddings of a file we can use it in a prompt.
Getting Started With Prompt Engineering
Crafting the perfect prompt is becoming an art form and a meaningful way to boost productivity across many fields, from programming to SEO, from content writing to digital art. In the last two years, I have been doing all I could to learn and share the craftsmanship of using prompting. It is a skill for literally anyone. These days, things are evolving fast, and there are new and emerging capabilities in these models that are yet to be discovered, but we also have better tooling to get us started. Here is my list:
- Here is an amazing 82-pages long free eBook on prompt for DALL·E
- Builders to help you with modifiers and parameters like https://promptomania.com/ or https://promptdeck.io/
- Apps like the CLIP Interrogator that helps you extract (using CLIP by OpenAI) the description of an image (and unveil how contrastive models work)
- Directory of AI-generated images and their prompts like https://prompthero.com/, https://lexica.art/, https://promptsea.io/ and even marketplaces for selling and buying prompts like https://promptbase.com/
- And models that helps us with the creation of the prompt like https://huggingface.co/spaces/doevent/prompt-generator
Fine-Tuning The Models – The Cover Experiment
Generating featured images for editorial content such as blog posts and news articles is an important part of SEO. Working professionally with foundational models means creating high-quality training datasets. These can be done, only initially manually and eventually needs to scale using semi-automatic workflows.
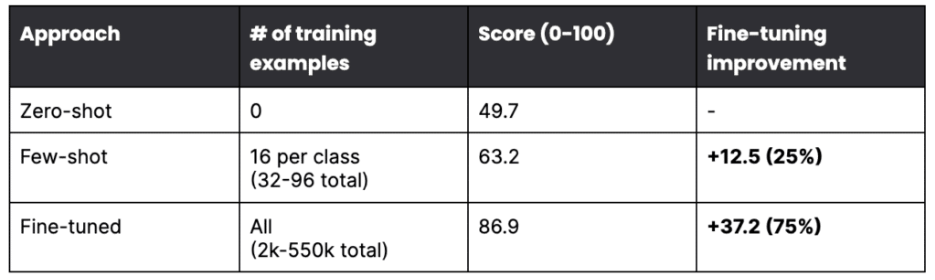
Results from research by Gao et al., 2022 on the improvement of fine-tuning for increasing accuracy of the model.
Now, suppose you have a particular type of image that you would like to generate. The best option is to fine-tune an image generation model like Stabe Diffusion to generate these types of images. Here below you can see a few examples of the work I am doing with Seppe Van den Berghe, the fantastic illustrator behind our blog covers. The model creates something similar but it is still far from being as good as Seppe. It lacks semantic compositionality in most cases.

You can replicate the same workflow using the code kindly provided as open source by TheLastBen here.The exciting result so far is that Seppe realizes the possibility of these models and how his creative workflow can change. As usual, while working with generative AI, the journey is more important than the destination. AI-powered art won’t replace illustrators anytime soon. However, illustrators like Seppe realize that technology is close enough that they can adopt some form of Ai-assisted tool to innovate their craft.
The Feedback-Loop Is King (Or Queen Or Both)
When working with Generative AI, we create things and make the work of humans more impactful. Rarely in the last months have we started a project where creators (content editors and SEOs) didn’t change their objectives during the project. We typically begin by replicating their best practices and things they learned from past experiences, and we create something entirely new.
The core of our work is not to replace humans but to expand their capabilities with the help of AI.
How Can We Help Creators Interacting With An AI Model?
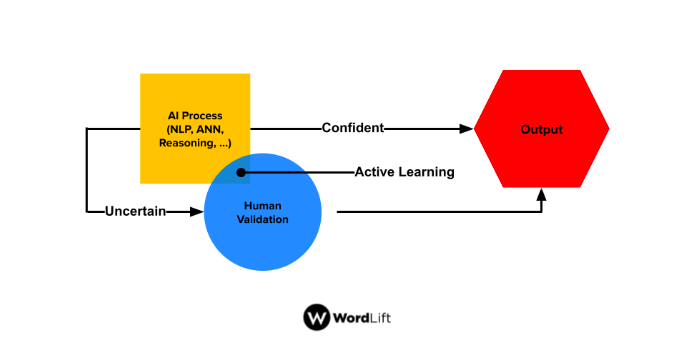
Sometimes it is as simple as summarizing search results for a query with the right tone of voice and re-training the model using the provided feedback (i.e., “this is good,” “mhmm, this is not so good,” “This is okayish but not ready for prime time”).
Sometimes it is about turning data into text and encoding existing editorial rules into validation workflows (i.e., “it is ok to use this expression, but we rarely use it,” “don’t mention this when you mentioned that,” etc.). As users interact with your AI model to flag inaccuracies or to check on the quality of the output, your training data becomes more robust, and the quality increases.
On the positive side, LLMs improve significantly as the quality of the training data increases. With a robust model, you can use a limited number of samples (200-400 items can be enough); as the editors provide more input, your training data grows (to thousands of examples), and smaller models can be used. As new models are trained, the validation automatically improves its ability to flag inaccuracy, and more synthetic data can be added to the training.
Future Work
Generative AI in SEO is a strategic asset for online growth. Having a Generative AI strategy in place means focusing on your data fabric and the interaction patterns that help you train small and highly specialized models. Bridging the gaps between LLMs and enterprise business problems is an SEO task.
In its inner nature, SEO is about extensive metadata curation (from nurturing knowledge graphs to publishing structured data) and content optimization. Both skills are in high demand to unlock a wide range of complex enterprise use cases.
We see LLMs evolving into agents and being able to interact with external cognitive assets such as knowledge graphs. Multi-prompt is clearing, opening a new wave of usage patterns for AI models.
What Is A Data Fabric?
A data fabric is a modern data management architecture that allows organizations to quickly use more of their data more often to fuel generative AI, digital transformation, and, last but not least, SEO. Data fabrics are a newer idea, first formally defined in 2016 by Forrester Analyst Noel Yuhanna in his report “Big Data Fabric Drives Innovation and Growth.”
How Can I Make My AI-Generated Images?
For anyone willing to test text-to-image generation or even image-to-image generation here is a list of tools that you can use:
- Dream Studio by the same team that released Stable Diffusion;
- Diffusion Bee (Mac only) brings you Stable Diffusion on your local computer, this can be helpful when dealing with private images;
- DALL·E 2 by OpenAI, the AI system to create realistic images;
- Midjourney my favorite pick for AI art generation;
- Replicate a startup simplifying the access to AI models by providing an API.
How Can I Optimize My Prompt?
Prompt engineering is a unique interface to foundational models. I don’t expect to see creators disappear, but I hope to see creators at the top of their games becoming very familiar with AI tools and the intricacies of prompt engineering. Here is my list of links to help you improve your prompting skills:
- Master modifiers and parameters using https://promptomania.com/ or https://promptdeck.io/
- Use CLIP Interrogator to extract the description of an image and to understand how CLIP works
- Experiment with https://prompthero.com/, https://lexica.art/, or https://promptsea.io/
- Access to marketplaces for selling and buying prompts like https://promptbase.com/
- Use a pre-trained model to create the prompt that you like https://huggingface.co/spaces/doevent/prompt-generator
What is your Generative AI strategy for 2023? Drop us an email or DM me on Twitter.
Credits And Special Thanks
All of this wouldn’t happen without the continuous support from our community of clients and partners experimenting with WordLift to automate their SEO. A big thank you also goes to:
- Luciano Floridi & Massimo Chiriatti for writing GPT-3: Its Nature, Scope, Limits, and Consequences, shedding light on the limitations of GPT-3
- The fantastic team working on WordLift Next Generation the R&D project that we are conducting with the financial support received from Eurostars H2020 along with Redlink GmbH, the Semantic Technology Institute at the Department of Computer Science of the University of Innsbruck and, SalzburgerLand Tourismus GmbH
- OpenAI, creators of GPT-3, for releasing CLIP and DALL-E (the encoder and decoder parts, specifically) https://github.com/openai/DALL-E/ that I used to generate the featured image of this blog post.
- Paul DelSignore for writing The Anatomy Of An AI Art Prompt
- Ben Dickson for writing BLOOM can set a new culture for AI research—but challenges remain and What is Google’s generative AI strategy? – 2022
- Thomas H. Davenport for writing How Generative AI Is Changing Creative Work – 2022
- SONYA HUANG, PAT GRADY AND GPT-3 for writing Generative AI: A Creative New World – published September 19, 2022
- Andy Coenen (PAIR), Daphne Ippolito (Brain Research), Ann Yuan (PAIR), Sehmon Burnam (Magenta) for writing the whitepaper Wordcraft Writers Workshop
- GLORIA LIU for writing The World’s Smartest Artificial Intelligence Just Made Its First Magazine Cover – Cosmopolitan, 2022
- Cornell University Researchs for writing Emergent Abilities of Large Language Models
- TheLastBen for the fast-stable-diffusion on Github
Recent Comments