SEO In The Metaverse: What We Can Learn From Computer Vision And Video
Discover how you can use your knowledge from computer vision and video optimization to make the metaverse world SEO-friendly.

Table of contents:
- The Metaverse Era
- Overview of advancements in visual search
- What are the top video ranking factors? What do other SEO professionals think?
- The need for open, actionable, scientific research in the SEO industry
- Connecting computer vision, images and video – the Swiss raclette experiment
- You only look once (YOLO) algorithm – an experiment with Google’s Martin Splitt SEO mythbusting series
- The need for the 3DModel schema markup
- Advanced Custom Fields
- The connection to the Metaverse
Online marketers spent the last 2, 3 decades optimizing readers’ content and enhancing the appropriate mix of keywords and entities so that online audiences can find them whenever they are offering products, services or informational content to educate their readers on their business. Every year, there are plenty of Google update algorithms that are raising the SEO bar and they are making it harder to meet the constantly evolving demanding standards that online searchers have.
However, if we are carefully looking at what is ahead of us and what will be trending in the future, we can see that the online marketing world is slowly changing. We are definitely witnessing the rise of web3 and going more towards creating in the universe of interconnected metaverses. It seems that the new goal will be to focus on “getting found in the metaverse world” – a bet that Facebook also did by rebranding their whole company to Meta. Seoul’s government also proceeded with a plan to develop a national metaverse platform in order to raise the city’s global competitiveness and Dubai also announced similar plans.
Therefore, the question is: how can we use our knowledge from computer vision and video optimization to make the metaverse world SEO-friendly? How to make a successful blend of synergies in order to develop new advanced strategies that will solve the need to be understood by users and search engines in this newly created metaverse world?
Current Advancements On The Topic Of Visual Search
Generative AI has definitely revolutionized computer vision but current models are still facing multiple challenges: typical vision datasets are costly because they require teaching the model of a narrow set of visual concepts, so this will pose a challenge in optimizing for the metaverse world too. In addition, standard vision models are good at performing one task but only one and require a lot of effort to develop new learnings.
One of the most advanced solutions there is the neural network called CLIP. CLIP (Contrastive Language Image Pre-training) is trained on a wide spectrum of images and natural language supervision that is available on the Internet. Another advancement is the model DALL-E, a neural network which creates images from text captions for a wide range of concepts that are expressible in natural language. As it’s noted on DALL-E’s website, it “represents a 12-billion parameter version of GPT3 trained to generate images from text descriptions using a dataset of text-image pairs”.
We performed some experiments with DALL-E in the past – here’s an image we created by using this neural network:

What Are The Top Video Ranking Factors? What Do Other SEO Professionals Think?
I spoke at SMX Munich 2023 a few days ago and asked the audience to tell me the most important factors for video ranking. We agreed on the following things:
- The length of the video (this is useful because we need to classify whether it is a longer video or a video that belongs to YouTube Shorts);
- The description of the video (to determine if it is worth watching before you actually invest time in it);
- The design (because home screens help users move from the general product listing page – the list of videos for a particular search term – to a specific video
- And so on.
If you already know me, you know that I am a very research-oriented person and a business-oriented computer engineer specializing in content engineering and end-to-end SEO. With that in mind, it makes sense to see what Google patents are hinting at on this topic.
I managed to find 2 patents related to video ranking optimization:
- “Popular media items dataset with exponential decay” by Google Research/Inc.
- “Page ranking system employing user sharing data” – a combined work by Google researchers/employees and the University of Maryland.
The first patent suggests that more engagement means better ranking and we can observe this from the following evidence excerpts:
- “…means for determining a user engagement value for the media item based on at least one user shares of the media item, user indications of interest in the media item, user comments on the media item…”
- “…A score for a media item is computed by determining a plurality of positive user actions associated with the media, combining a plurality of score contributions from the plurality of positive user actions to determine a value for the score, and applying an exponential decay to the value for the score. The media items are ranked based on the scores…”.
While the second patent does not explicitly cover the topic of videos, it does provide some interesting insights for us. For example, we can see from the following excerpt that embedding videos can lead to better rankings: “…A user can thereby be presented with relevant search results ranked by or incorporating content sharing data, such as how often the content has been shared, and possibly in conjunction with other ranking data (internal and/or external reference).“
But what if I decide to IGNORE all the known SEO video ranking tips that the world knows about? How will I rank my video then?
The Need For Open, Actionable, Scientific Research In The SEO Industry
When we talk about case studies and research in the SEO industry, we really need to think about how we want to conduct research in a scientific framework:
- Point out previous efforts
- Use a scientific methodology to set up the exploration and the opportunity to gain new insights
- Share the exact processes, tools, and algorithms that were used in the experiment
- Show the results, show their statistical significance
- Discuss findings and future work
I practice what I preach, and so I published my dissertation “Content Engineering for SEO Digital Strategies by using NLP and ML“ in IEEE, one of the most prestigious journals for computer science and engineering. I will use this knowledge from my previous research activities and my knowledge of computer vision for this experiment to better explain my current work.
Where Is Computer Vision Headed?
When comparing the NLP field with the computer vision field, we can notice that we already established the foundational models for NLP: we have models trained on tons of parameters like BERT, transformers, GPT2 or GPT3, so that people can adapt them for their specific applications and domain. However, it is worth noting that these NLP models can be unsatisfactory because they don’t possess domain knowledge.
Making foundational computer vision models is a priority for computer vision scientists, just like in the NLP field. Andrew Ng says that “he believes we will see something similar in computer vision. “Many people have been pre-training on ImageNet for many years now,” he said. “I think the gradual trend will be to pre-train on larger and larger data sets, increasingly on unlabeled data sets rather than just labeled datasets, and increasingly a little bit more on video rather than just images.” ”
Connecting Computer Vision, Images And Video – Swiss Raclette Experiment
Computers are able to perform object detection and image recognition in both images and videos. By using computer vision, we can break things in visuals down into pixels and then perform matching based on this information.
At WordLift, we believe that marketing is a generous act that helps others achieve their goals and an opportunity to serve. For this reason, we are sharing this experiment with you. We used this knowledge about object detection, speech recognition and knowledge about Google’s abilities to even understand certain environments (like restaurants) and movements in video to create a half-a-minute long video sequence of Swiss raclettes, a satisfying collection of different servings found on Instagram. All of the videos were carefully handpicked by using the hashtag #swissraclette. Some of the criteria used to pick them are considering the following factors:
- Having a clear picture of the ingredients;
- Showing different ingredients from multiple angles;
- “Restaurant sounds” like knives, forks and so on;
- Different sizes of the meal servings shown together.
Once we created the whole video, it was uploaded directly on YouTube, having the following title “Swiss Raclette – Satisfying compilation of Melting Cheese (Potatoes, Bread, Onions, Cucumbers, Meat)”. In order to eliminate the effect of other types of video and image optimization, we decided to leave them aside and just post the video, hoping that the algorithm will pick up all the cues that we’ve architected in the video sequence and use this knowledge to recommend videos further. Therefore, we have the following situation:
- No tags;
- No synonyms for swiss raclette
- Never had a history of channel advertising in any way
- No embeds
- No schema markup
- No links
- The URL and the slug were defined by Google
- No link depth
- My channel and personal region did not overlap with Switzerland
- No comments;
- No shares;
- No description;
- No campaign;
- No likes or other user signals;
- No language setting;
- No captions;
- No start or end screens;
- Undefined location;
- Not having an established youtube fan base that cares about swiss raclette;
- The video is not even in a playlist.
We implemented the following things: Architected video frames, set up a OK filename (swiss-raclette.mp4), verified the host, defined a quality title with thematic entities – lemmas, was nearby in Germany during the run of the video, and mainly focused on using my knowledge of computer vision to create the video.
Basically, the general approach is to apply computer science and engineering knowledge to video. Cross-functional work, or applying an idea from one field (in this case computer science) to another (marketing) is key to gaining new insights for SEO purposes (new video ranking factors). So I discovered another paper by Google researchers titled “DOPS: learning to detect 3D objects and predict their 3D shapes” that pointed me in a new direction. Interesting, I said to myself, this is something I can work with and explore further! The main logic now is to evaluate videos using only 3D object optimization.
The results are the following:

To this day, we gathered 750+ views and 20+ likes for the video. As you can see from the picture, over 87% of the visits came as a result of search features, like suggested videos, search, browse features and YouTube shorts. It is clear that architecting visual frames works and smart environment setup is the content optimization for videos and metaverse worlds in future.
This is important to understand because we have full control on our content creation process. You cannot re-optimize video or 3D environments once you create it or write a better description for ranking – Google will ignore them right away or will over time.
Ideally, everyone should tend to build stuff that will last. It is cheaper to architect the 3D environment beforehand v.s. bringing the whole team to produce a new video or platform and advertise it all over from scratch.
You Only Look Once (YOLO) Algorithm – An Experiment With Google’s Martin Splitt SEO Mythbusting Series
One of the main challenges in computer vision is to pick the right model for experimenting. Having achieved solid results in the previous experiment, just by carefully architecting handpicked videos for visual sequence creation, we decided to pick another video which is full of objects and perform object detection by using the YOLO algorithm.
You only look once (YOLO) is a state-of-the-art, real-time object detection system. The pre-trained model of the convolutional neural network is able to detect pre-trained classes including the data set from VOC and COCO, or you can also create a network with your own detection objects. We chose this model because it’s fairly simple to experiment with and it is relatively easy to develop the script for the experiment.
Using the COCO dataset (large-scale detection of Common Objects in Context), YOLO can detect the 80 COCO object classes like person, dining table, cell phone, laptop, TV, chair, sofa, bed, clock, book and so on. When processing multiple visual frames, it is useful to use an algorithm which will detect duplicate frames and remove them from the frames that need to be analyzed. A good solution for this is the Image Deduplicator algorithm developed by the engineering team at Idealo GmbH – a python package that easies the task of finding exact or near duplicate images in an image dataset.
The image recognition script is fairly simple: you need to download the pre-trained model yoloh5 (Hierarchical Data Format) and upload it to your Google Drive and set the path to the model. You will need to upload the video that you want to analyze before running the analysis. We decided to analyze 20 frames per second – please note that even a 3 minute video can contain many video frames and require some processing time in order to be done. In our case, it took us around 1 hour to tag the object in the video and produce the final output. Here’s how the script looks like:
!pip install imageai
!sudo add-apt-repository ppa:deadsnakes/ppa
!sudo apt-get update
!sudo apt-get install python3.8
!sudo apt install python3.8-distutils
!sudo apt install python3.8-venv python3.8-dev
!sudo apt-get install python3-pip
!python3.8 -m pip install -U pip setuptools
!pip install tensorflow==2.4.1
!pip install keras==2.4
from imageai.Detection import VideoObjectDetection
import os
def forFrame(frame_number, output_array, output_count, detected_frame):
print("FOR FRAME ", frame_number)
print("Output for each object : ", output_array)
print("Output count for unique objects : ", output_count)
print("Returned Objects is : ", type(detected_frame))
print("------------END OF A FRAME --------------")
execution_path = os.getcwd()
print(execution_path)
detector = VideoObjectDetection()
detector.setModelTypeAsYOLOv3()
detector.setModelPath(os.path.join(execution_path, "/content/drive/MyDrive/yolo.h5"))
detector.loadModel()
video_path = detector.detectObjectsFromVideo(
input_file_path="/content/drive/MyDrive/video_name.mp4", # enter the full path here
output_file_path="/content/drive/MyDrive/result.mp4"
, frames_per_second=20, log_progress=True, return_detected_frame=True, minimum_percentage_probability=50,
per_frame_function=forFrame)
print(video_path)
The link to the script can be found here. It is important to understand that this is not what Google’s algorithms look like exactly but still, we are trying to mimic its strategy for object recognition by using existing state-of-the-art techniques that are well-known in the computer vision world.
Phase 2
We chose the video of Google’s Developer Advocate Martin Split, speaking at “SEO Mythbusting Is Back – Official Trailer (Season 2)” because it’s object rich and a perfect candidate to test the video Instance segmentation procedure.
As we can see from the screenshots, the YOLO algorithm classifies Martin’s hair as an apple and some of the objects are incorrectly marked up to represent a car or a person. The confidence score that the object detection process is performed correctly is over 50%. Manual observation shows that this is certainly not true when observing the video.

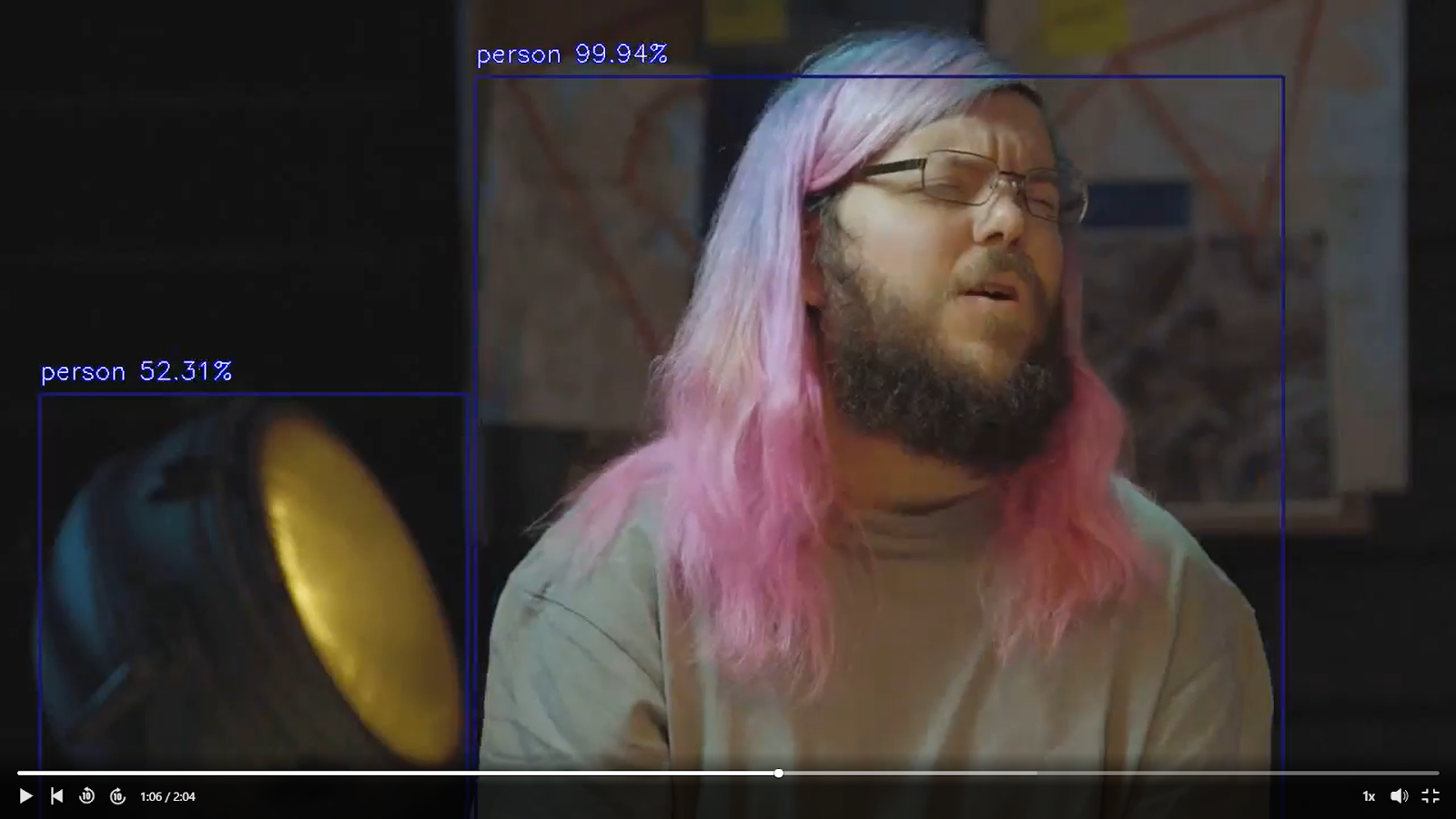
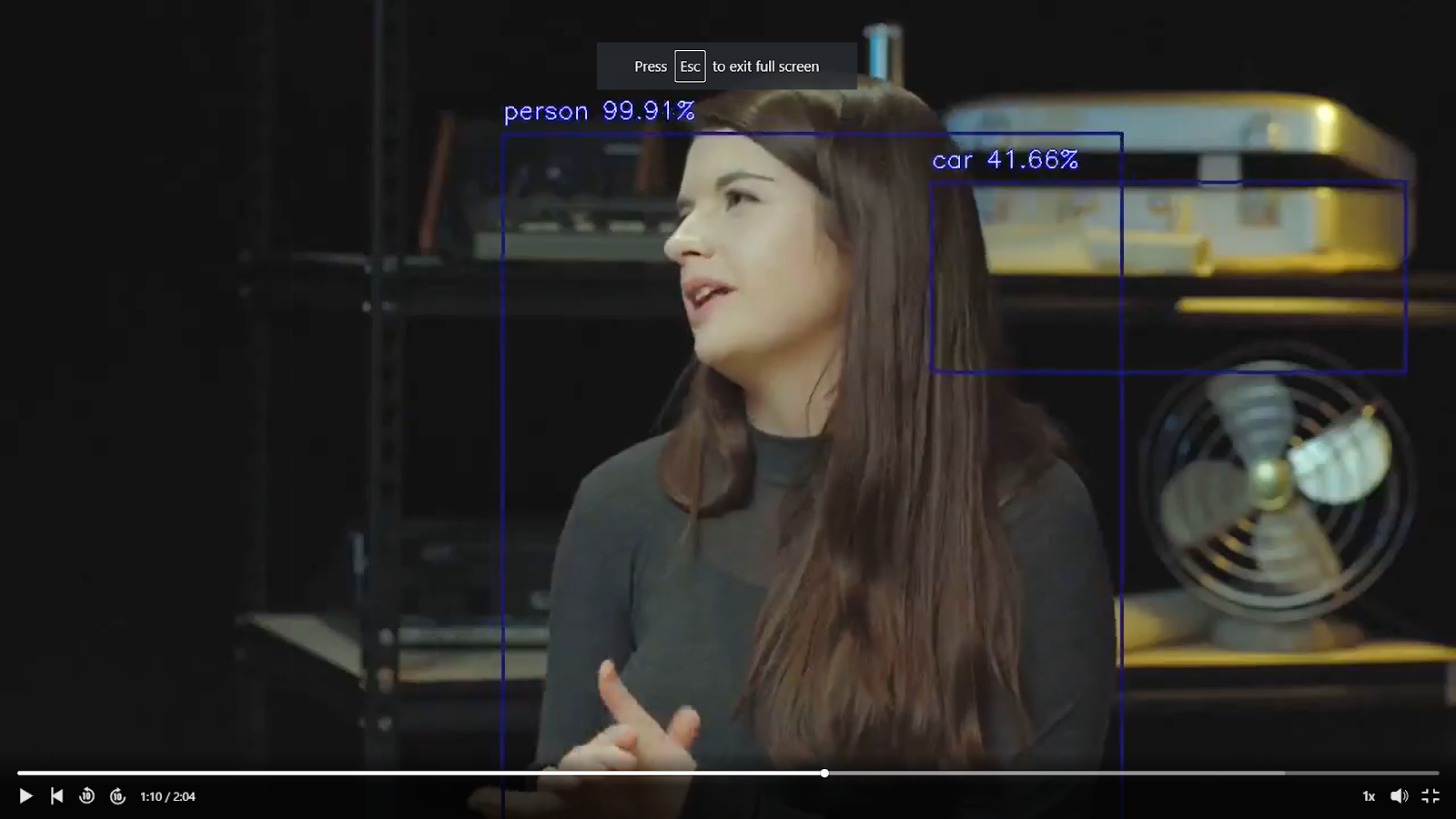
Conclusion: object detection is challenging, especially if the computer vision model is not trained on a diverse image dataset that represents the same objects but from different angles, postures and positions.

We can also try to take a similar approach using the Google Vision API and their Vision Intelligence API. If we take an example image from our Youtube video for Swiss Raclette, we can observe that the algorithm is able to detect that we have food, ingredients and Gruyere cheese, which is wrong (this is a different cheese compared to Raclette cheese). However, we are still on a good path, because Google “understands” that we are dealing with the topic of Swiss cheese in general.
Some other interesting algorithms to try out:
- Object Detection: YOLO, Faster R-CNN, RetinaNet.
- Image Segmentation: Mask R-CNN, U-Net, DeepLabv3+.
- Optical Flow: Farneback, Lucas-Kanade.
- Action Recognition: Two-Stream Convolutional Networks, Temporal Segment Networks (TSN), 3D Convolutional Neural Networks (3D-CNN).
- General Video Analysis: Keyframe Extraction, Video Summarization.
- Object Tracking: KCF, Deep SORT, GOTURN.
The Need For The 3DModel Schema Markup
The experiments we performed are clearly indicating that even when we use advanced algorithms like YOLO, there’s still a space for the objects to be incorrectly labeled in visual environments like videos and metaverse spaces (virtual reality and augmented reality platforms). Having this in mind, we need to find a more structured way of providing 3D information to search engines.
That is where structured data markup like the 3DModel schema comes into play. When using structured data like this, you help Google understand the content of your site and enable specific search result features for your webpages. 3DModel schema requires the following properties:
- @type: 3DModel
- name: the name of your item.
- encoding: this property is a list and must contain your 3D assets (or MediaObject)
In addition, the required properties for each 3D object or MediaObject are the following:
- @type: MediaObject
- contentUrl: The URL to your 3D object
- encodingFormat: the encoding format
An example of 3DModel schema markup can look like this:
<script type="application/ld+json"> { "@context":"http://schema.org/", "@type":"3DModel", "image":"", "name":"Muscle", "encoding":[ { "@type":"MediaObject", "contentUrl":"https://link_to_your_content_no1", "encodingFormat":"model/gltf-binary" }, { "@type":"MediaObject", "contentUrl":"https:/link_to_your_content_no1", "encodingFormat":"model/vnd.usdz+zip" } ] } </script>We can use this information to create an automated way for you to apply this schema on multiple pages on your website by using WordLift’s mappings and advanced custom fields.
Advanced Custom Fields
When dealing with multiple schemas, it is good to have a tool which can do the initial mapping and then use the newly created schema to apply it to new use cases. This is exactly what our tool does – identify your schema markup type (Course, LocalBusiness, Location, Store, Service, whatever it is, in our case it’s the 3DModel schema markup), define its attributes, markup the optional and required fields, confirm the mapping and then apply this created schema with the defined rules to upcoming specific use cases that follow the same schema type that you created before.
Ideally, you would like to use properties that are general to most use cases and not overly specific to a particular use-case in order to make the specific schema markup reusable.
By using schema markup, we’re communicating to the search engines about what type of content we are using in a machine-readable way. This is an important step in the process since dealing with unstructured data like text, images or video is sometimes hard to debunk, as we saw in our previous experiments.
It’s beneficial to have a JSON-alike object to explain what is happening out there in a more structured way. The final creation can be tested by using the Google Structured Data Testing tool.
The Connection To The Metaverse
3D is the key component for search, but also a solid foundation for future generative AI apps and the metaverse. “The things you create, grow and earn in the Metaverse will be yours. And more importantly, you will be able to monetize them. There will be a huge incentive for creators to be present and create in this space”.
When we talk about the metaverse, the first thing we have to think about is the objectverse: you’ll be able to define a 3D object that you want to use, pull it from some kind of database, expand it or shrink it, and throw it into the room to start creating it. “We can now use generative AI for images. We can do it for videos. At the rate it’s going, you’ll be able to create entire villages, 3D villages, landscapes, cities and so on. You’ll be able to put together a sample image and create an entire 3D world”. It has never been more exciting to be part of the Metaverse and 3D SEO as a whole!
The key takeaway is that we can rank videos just by using a 3D optimization approach. What I also like about this strategy is that it is:
- Scaleable: you do it once but it is applicable to all 3D understanding platforms like video platforms and multiverses that employ algorithms to understand what 3D content is about;
- Harder to reverse engineer: because we don’t have dedicated SEO software to help us figure out how to outrank our competition;
- Harder to replicate: we need creative storytelling and enough resources to be able to do it on our side properly;
- Usually overlooked and lacking strategy from the management: nobody speaks about 3D optimization or video optimization in an advanced way.
Take a look at the presentation I gave at SMX Munich 2023 👇