Text Summarization in SEO with the Help of AI
In the last two decades, text summarization has played an essential role in search engine optimization (SEO). While our existing BERT-based summarization API performs well in German, we wanted to create unique content instead of only shrinking the existing text.

In the last two decades, text summarization has played an essential role in search engine optimization (SEO). There are, indeed, a lot of different marketing techniques that require a summary of the content, and that can improve ranking in search engines. Meta descriptions are probably among the most notable examples (here is a video tutorial that Andrea did on generating meta descriptions).
These text snippets provide search engines with a brief description of the page content and are still an important ranking factor and one of the most common use cases for text summarization.
Thanks to the latest NLP technologies, SEO specialists can finally summarize the content of entire webpages using algorithms that craft easy-to-read summaries.
In this article, we will discuss the importance of using text summarization in the context of SEO and digital marketing.
Summaries help create and structure the metadata that describes web pages. Text summarization also comes in handy when we want to add descriptive text to category pages for magazines and eCommerce websites or when we need to prepare the copy for promoting our latest article to Facebook or Twitter. Much like search engines use meta descriptions, social networks rely on their meta descriptors like the Facebook Open Graph meta tag (a.k.a. OG tag) to distribute content to their users. Facebook for instance, uses the summary provided in OG tags to create the card that promotes a blog post on mobile and desktop devices.
Extractive vs Abstractive
There are many different text summarization approaches, and they vary depending on the number of input documents, purpose, and output. But, they all fall into one of two categories: extractive or abstractive.
Extractive Text Summarization
Extractive summarization algorithms identify essential sections of a text and generate verbatim to produce a subset of the sentences from the original input.
Extractive summaries are reliable because they will not change the meaning of any sentence. They are generally easier to program. It’s very logical, and in the most straightforward implementations, the most common words in the source text are the words that represent the main topic. Using today’s pre-trained Transformer models with their ground-breaking performance, we can achieve excellent results with the extractive approach.
In WordLift, for instance, we use generative AI to quickly summarize a lengthy blog post. In particular, BERT is used to boost the performance of extractive summarization across different languages. Here is the summary that WordLift creates for me for this article that you are reading.
In the last two decades, text summarization has played an essential role in search engine optimization (SEO). While our existing BERT-based summarization API performs well in German, we wanted to create unique content instead of only shrinking the existing text.

It is quite useful in summarizing, using the most important sentences, the content that I am writing here, and it is formally correct (or at least as valid as my writing) but not unique.
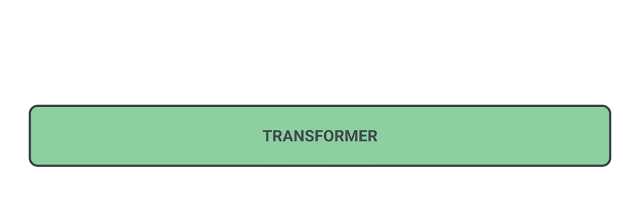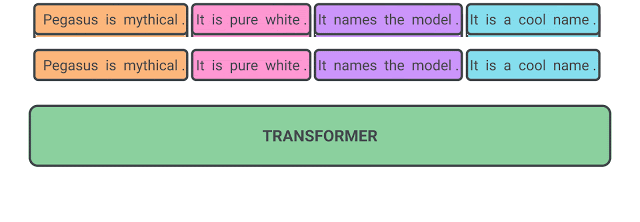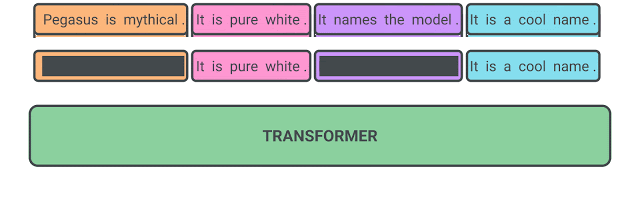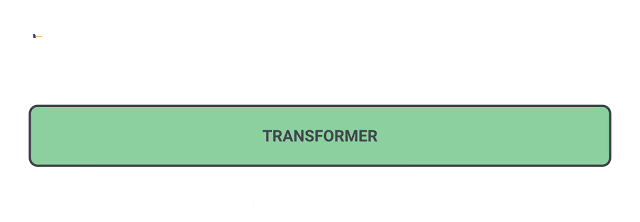
Abstractive Text Summarization
Abstractive methodologies summarize texts differently, using deep neural networks to interpret, examine, and generate new content (summary), including essential concepts from the source.
Abstractive approaches are more complicated: you will need to train a neural network that understands the content and rewrites it.
In general, training a language model to build abstract summaries is challenging and tends to be more complicated than using the extractive approach. Abstractive summarization might fail to preserve the meaning of the original text and generalizes less than extractive summarization.
As humans, when we try to summarize a lengthy document, we first read it entirely very carefully to develop a better understanding; secondly, we write highlights for its main points. As computers lack most of our human knowledge, they still struggle to generate summaries’ human-level quality.
Moreover, using abstractive approaches also poses the challenge of supporting multilingualism. The model needs to be trained for each language separately.
Training our new model for German using Google’s T5

As part of the WordLift NG project and, on behalf of one of our German-speaking clients, we ventured into creating a new pre-trained language model for automatic text summarization in German. While our existing BERT-based summarization API performs well in German, we wanted to create unique content instead of only shrinking the existing text.
T5 “the Text-To-Text Transfer Transformer Model” is Google’s state of the art LM, which was proposed earlier this year in the paper, “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.”
This new language model is revolutionary as we can re-use the same model for different NLP tasks, including summarization. T5 is also language-agnostic, and we can use it with any language.
We successfully trained the new summarizer on a dataset of 100,000 texts together with reference summaries extracted from the German Wikipedia. Here is a result where we see the input summary that was provided along with the full text of the Wikipedia page on Leopold Wilhelm and the predicted summary generated by the model.

Conclusions and future work
We are very excited about this new line of work and we will continue experimenting new ways to help editors, SEOs and website owners improve their publishing workflows with the help of NLP, knowledge graphs and deep learning!
WordLift provides websites with all the AI you need to grow your traffic — whether you want to increase leads, accelerate sales on your e-commerce or build a powerful website. Let’s talk with our experts to find out more!