
If you are confused about meta descriptions in SEO, why they are important and how to nail it with the help of artificial intelligence, this article is for you.
If you are eager to start experimenting with an AI-writer, read the full article. At the end, I will give you a script to help you write meta descriptions on scale using BERT: Google’s pre-trained, unsupervised language model that has recently gained great momentum in the SEO community after both, Google and BING announced that they use it for providing more useful results.
I used to underestimate the importance of meta descriptions myself: after all Google will use it only on 35.9% of the cases (according to a Moz analysis from last year by the illustrious @dr_pete). In reality, these brief snippets of text, greatly help to entice more users to your website and, indirectly, might even influence your ranking thanks to higher click-through-rate (CTR).
While Google can overrule the meta descriptions added in the HTML of your pages, if you properly align:
 Here’s an example of what a meta description usually looks like (from that same article):
Here’s an example of what a meta description usually looks like (from that same article):

 “Extractive summarization methods work by identifying important sections of the text and generating them verbatim; […] abstractive summarization methods aim at producing important material in a new way. In other words, they interpret and examine the text using advanced natural language techniques in order to generate a new shorter text that conveys the most critical information from the original text”
— Text Summarization Techniques: A Brief Survey, 2017.
With simple words with extractive summarization we will use an algorithm to select and combine the most relevant sentences in a document. Using abstractive summarization methods, we will use sophisticated NLP techniques (i.e. deep neural networks) to read and understand a document in order to generate novel sentences.
In extractive methods a document can be seen as a graph where each sentence is a node and the relationships between these sentences are weighted edges. These edges can be computed by analyzing the similarity between the word-sets from each sentence. We can then use an algorithm like Page Rank (we will call it Text Rank in this context) to extract the most central sentences in our document-graph.
“Extractive summarization methods work by identifying important sections of the text and generating them verbatim; […] abstractive summarization methods aim at producing important material in a new way. In other words, they interpret and examine the text using advanced natural language techniques in order to generate a new shorter text that conveys the most critical information from the original text”
— Text Summarization Techniques: A Brief Survey, 2017.
With simple words with extractive summarization we will use an algorithm to select and combine the most relevant sentences in a document. Using abstractive summarization methods, we will use sophisticated NLP techniques (i.e. deep neural networks) to read and understand a document in order to generate novel sentences.
In extractive methods a document can be seen as a graph where each sentence is a node and the relationships between these sentences are weighted edges. These edges can be computed by analyzing the similarity between the word-sets from each sentence. We can then use an algorithm like Page Rank (we will call it Text Rank in this context) to extract the most central sentences in our document-graph.

 I have also to admit that It has been quite some time since I entertained myself with automatic text-summarization of online content and I have experimented with a lot of different methods before getting into BERT.
BERT is a pre-trained unsupervised natural language processing model created by Google and released as an open source program (yay!) that does magic on 11 of the most common NLP tasks.
BERTSUM, is a variant of BERT, designed for extractive summarization that is now state-of-the-art (here you can find the paper behind it).
Derek Miller, leveraging on these progresses, has done a terrific work for bringing this technology to the masses (myself included) by creating a super sleek and easy-to-use Python library that we can use to experiment BERT-powered extractive text summarization at scale. A big thank you also goes to the HuggingFace team since Derek’s tool uses their Pytorch transformers library ?.
I have also to admit that It has been quite some time since I entertained myself with automatic text-summarization of online content and I have experimented with a lot of different methods before getting into BERT.
BERT is a pre-trained unsupervised natural language processing model created by Google and released as an open source program (yay!) that does magic on 11 of the most common NLP tasks.
BERTSUM, is a variant of BERT, designed for extractive summarization that is now state-of-the-art (here you can find the paper behind it).
Derek Miller, leveraging on these progresses, has done a terrific work for bringing this technology to the masses (myself included) by creating a super sleek and easy-to-use Python library that we can use to experiment BERT-powered extractive text summarization at scale. A big thank you also goes to the HuggingFace team since Derek’s tool uses their Pytorch transformers library ?.

- the main intent of the user (the query you are targeting),
- the title of the page and
- the meta description
What are meta descriptions?
As usual I tend to “ask” “experts” online a definition to get started, and with a simple query on Google, we can get this definition from our friends at WooRank: Meta descriptions are HTML tags that appear in the head section of a web page. The content within the tag provides a description of what the page and its content are about. In the context of SEO, meta descriptions should be around 160 characters long.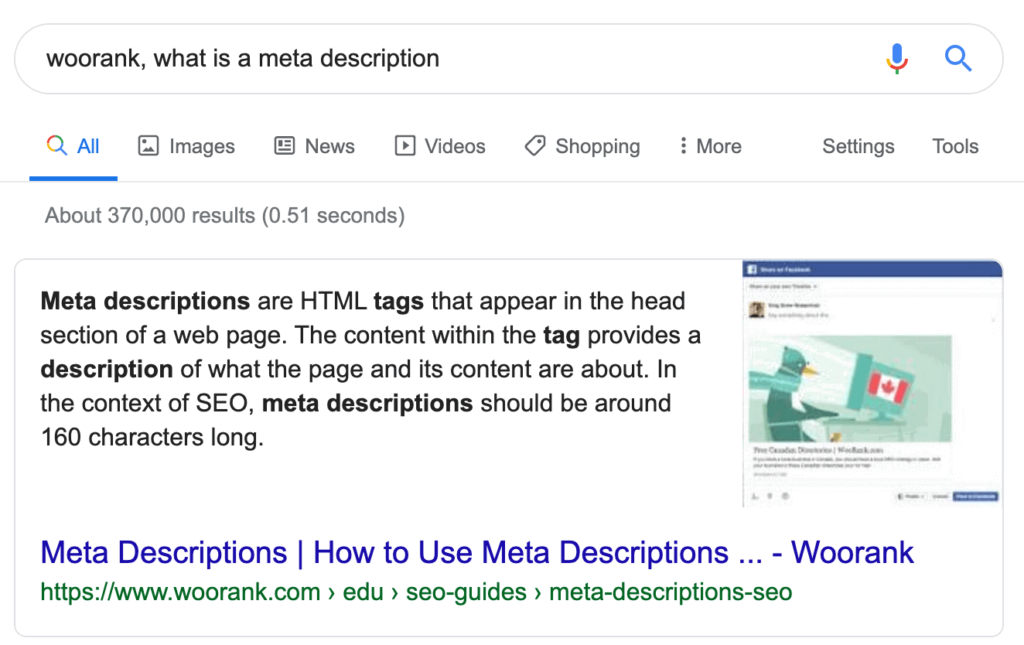 Here’s an example of what a meta description usually looks like (from that same article):
Here’s an example of what a meta description usually looks like (from that same article):

How long should your meta description be?
We want to be, as with any other content on our site, authentic, conversational and user-friendly. Having said that, in 2020, you will want to stick to the 155-160 characters limit (this corresponds to 920 pixels). We also want to keep in mind that the “optimal” length might change based on the query of the user. This means that you should really do your best in the first 120 characters and think in terms of creating a meaningful chain by linking the query, the title tag and the meta description. In some cases, within this chain it is also very important to consider the role of the breadcrumbs. As in the example above from WooRank I can quickly see that the definition is coming from an educational page of their site: this fits very well with my information request.What meta descriptions should we focus on?
SEO is a process: we need to set our goals, analyze the data we’re starting with, improve our content, and measure the results. There is no point in looking at a large website and saying, I need to write a gazillion of meta descriptions since they are all missing. It would simply be a waste of time. Besides the fact that in some cases – we might decide not to add a meta description at all. For example, when a page covers different queries and the text is already well structured we might leave it to Google to craft the best snippet for each super query (they are super good at it ?). We need to look at the critical pages we have – let’s not forget that writing a good meta description is just like writing an ad copy — driving clicks is not a trivial game. As a rule of thumb I prefer to focus my attention on:- Pages that are already ranking on Google (position > 0); adding a meta description to a page that is not ranking will not make a difference.
- Pages that are not in the top 3 positions: if they are already highly ranked, unless I can see some real opportunities – I prefer to leave them as they are.
- Pages that have a business value: on the wordlift website (the company I work for), there is no point in adding meta descriptions to landing pages that have no organic potential. I would rather prefer to focus on content from our blog. This varies of course but is very important to understand what type of pages I want to focus on.
A quick introduction to single-document text summarization
Automatic text summarization is a challenging NLP task to provide a short and possibly accurate summary of a long text. While, with the growing amount of online content, the need for understanding and summarizing content is very high. In pure technological terms, the challenge for creating well formed summaries is huge and results are, most of the time, still far from being perfect (or human-level). The first research work on automatic text summarization goes back to 50 years ago and various techniques. Since then, they have been used to extract relevant content from unstructured text. “The different dimensions of text summarization can be generally categorized based on its input type (single or multi document), purpose (generic, domain specific, or query-based) and output type (extractive or abstractive).” — A Review on Automatic Text Summarization Approaches, 2016.Extractive vs Abstractrive
Let’s have a quick look at the different methods we have for compressing a web page. “Extractive summarization methods work by identifying important sections of the text and generating them verbatim; […] abstractive summarization methods aim at producing important material in a new way. In other words, they interpret and examine the text using advanced natural language techniques in order to generate a new shorter text that conveys the most critical information from the original text”
— Text Summarization Techniques: A Brief Survey, 2017.
With simple words with extractive summarization we will use an algorithm to select and combine the most relevant sentences in a document. Using abstractive summarization methods, we will use sophisticated NLP techniques (i.e. deep neural networks) to read and understand a document in order to generate novel sentences.
In extractive methods a document can be seen as a graph where each sentence is a node and the relationships between these sentences are weighted edges. These edges can be computed by analyzing the similarity between the word-sets from each sentence. We can then use an algorithm like Page Rank (we will call it Text Rank in this context) to extract the most central sentences in our document-graph.
“Extractive summarization methods work by identifying important sections of the text and generating them verbatim; […] abstractive summarization methods aim at producing important material in a new way. In other words, they interpret and examine the text using advanced natural language techniques in order to generate a new shorter text that conveys the most critical information from the original text”
— Text Summarization Techniques: A Brief Survey, 2017.
With simple words with extractive summarization we will use an algorithm to select and combine the most relevant sentences in a document. Using abstractive summarization methods, we will use sophisticated NLP techniques (i.e. deep neural networks) to read and understand a document in order to generate novel sentences.
In extractive methods a document can be seen as a graph where each sentence is a node and the relationships between these sentences are weighted edges. These edges can be computed by analyzing the similarity between the word-sets from each sentence. We can then use an algorithm like Page Rank (we will call it Text Rank in this context) to extract the most central sentences in our document-graph.
The carbon footprint of NLP and why I prefer extractive methods to create meta descriptions
In a recent study, researchers at the University of Massachusetts, Amherst, performed a life cycle assessment for training several common large AI models with focus on language models and NLP tasks. They found that training a complex language model can emit five times the lifetime emissions of the average American car (including whatever is required to manufacture the car itself!). While automation is key we don’t want to contribute to the pollution of our planet by misusing the technology we have. In principle, using abstract methods and deep learning techniques offers a higher degree of control when compressing articles into 30-60 word paragraphs but, considering our end goal (enticing more clicks from organic search), we can probably find a good compromise without spending too many computational (and environmental) resources. I know it sounds a bit naïve but…it is not and we want to be sustainable and efficient in everything we do.What is BERT?
BERT: The Mighty Transformer
Now, provided the fact that a significant amount of energy has been already spent to train BERT (1,507 kWh according to the paper mentioned above), I decided it was worth testing it for running extractive summarization. I have also to admit that It has been quite some time since I entertained myself with automatic text-summarization of online content and I have experimented with a lot of different methods before getting into BERT.
BERT is a pre-trained unsupervised natural language processing model created by Google and released as an open source program (yay!) that does magic on 11 of the most common NLP tasks.
BERTSUM, is a variant of BERT, designed for extractive summarization that is now state-of-the-art (here you can find the paper behind it).
Derek Miller, leveraging on these progresses, has done a terrific work for bringing this technology to the masses (myself included) by creating a super sleek and easy-to-use Python library that we can use to experiment BERT-powered extractive text summarization at scale. A big thank you also goes to the HuggingFace team since Derek’s tool uses their Pytorch transformers library ?.
I have also to admit that It has been quite some time since I entertained myself with automatic text-summarization of online content and I have experimented with a lot of different methods before getting into BERT.
BERT is a pre-trained unsupervised natural language processing model created by Google and released as an open source program (yay!) that does magic on 11 of the most common NLP tasks.
BERTSUM, is a variant of BERT, designed for extractive summarization that is now state-of-the-art (here you can find the paper behind it).
Derek Miller, leveraging on these progresses, has done a terrific work for bringing this technology to the masses (myself included) by creating a super sleek and easy-to-use Python library that we can use to experiment BERT-powered extractive text summarization at scale. A big thank you also goes to the HuggingFace team since Derek’s tool uses their Pytorch transformers library ?.
Long live AI, let’s scale the generation of meta descriptions with our adorable robot [CODE IS HERE]
So here is how everything works in the code linked to this article.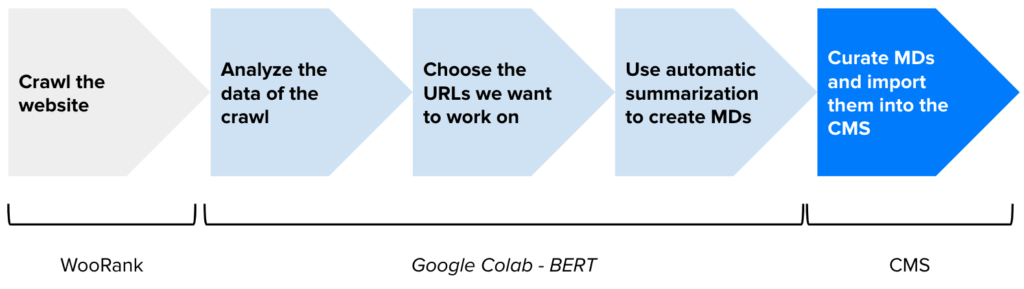
- We start with a CSV that I generated using the WooRank’s crawler (here you can tweak the code and use any CSV that helps you detect where on the site MDs are missing and where it can be useful to add them); the file provided in the code has been made available on Google Drive (this way we can always look at the data before running the script).
- We analyze the data from the crawler and build a dataframe using Pandas.
- We then choose what URLs are more critical: in the code provided I basically work on the analysis of the wordlift.io website and focus only on content from the English blog that has already a ranking position. Feel free to play with the Pandas filters and to infuse your own SEO knowledge and experience to the script.
- We then crawl each page (and here you might want to define the CSS class that the site uses in the HTML to detect the body of the article – hence preventing you from analyzing menus and other unnecessary elements in the page).
- We ask BERT (with a vanilla configuration that you can fine-tune) to generate a summary for each page and to write it on a csv file.
- With the resulting CSV we can head back to our beloved CMS and find the best way to import the data (you might want to curate BERT’s suggestions before actually going live with it – once again – most of the cases we can do better then the machine).