In a quest to redefine the landscape of Search Engine Optimization (SEO), Artificial Intelligence (AI), and knowledge graphs, WordLift embarked on a transformative journey known as the WordLift NG project, funded by the European Union. The project sought to surpass the constraints of the conventional WordPress ecosystem, ushering in a new era of digital intelligence.
Collaborative Endeavors
The project was operated by a Consortium consisting of WordLift and three esteemed Austrian partners: the Computer Science department of the University of Innsbruck, Salzburgerland Tourismus (the Salzburg tourism board), and long-time technology partner, Redlink.
At the center of the project was a fundamental commitment to advance the WordLift plugin beyond the WordPress platform. This strategic move broadened its horizons and exemplified a bold leap into new frontiers. This initiative was perfectly intertwined with the overall objective of enriching the range of offerings provided by WordLift, resulting in a series of product innovations and increased accessibility, all meticulously designed to meet its user community’s diverse needs and preferences.
The work carried on by the four partners resulted in attaining key objectives and establishing a robust foundation for future developments.
Project Summary and Key Achievements
The creation of the WordLift NG platform stands as a remarkable achievement, offering advanced service management and scalability. The shift from a monolithic to a microservices architecture has empowered the platform to efficiently handle high-traffic websites, making it an invaluable asset for both WordPress and non-WordPress users.
WordLift’s dedication to customer migration has yielded impressive results, ensuring seamless transitions for a diverse global clientele. This significant endeavor highlights the company’s unwavering commitment to maintaining operations and ensuring customer satisfaction.
Some of the functionalities developed within the project have significantly impacted the effectiveness of the final WordLift NG outcome, such as an improved GraphQL integration for enhanced scalability of query complexity. This was extremely important to the development of the upcoming content generation module.
The innovation of solutions for websites beyond WordPress has further solidified WordLift’s position as a frontrunner in Italy’s AI landscape.
WordLift achieved the more prominent results within the scope of the project, such as:
Improvement of the backend performances by enabling and querying graphs
Implementation of semantic search and content recommendations for users
Successful integration with digital assistants.
WordLift delivered a solid platform based on a B2B2C model that enables brand recognition, effective distribution, and network building.
Furtherly, within the scope of the project, WordLift developed tools and functionalities, beyond the product, such as an SEO add-on for Google Sheets, the introduction of a connector for Google Looker Studio, and the establishment of a versatile content generation tool.
Ongoing and Future Objectives
While the project’s central objectives have been achieved, the WordLift NG consortium acknowledges that innovation is an ever-evolving journey. Several goals, which serve as beacons for future endeavors, require further development activities to realize their potential fully.
Ongoing experimentation on semantic search remains a dynamic pursuit as WordLift explores the use of generative AI and structured data to develop new workflows.Similarly, the quest to create conversational interfaces powered by the knowledge graph signifies a commitment to stay at the forefront of AI advancements. The initial prototypes exhibit promise, but continued refinement is essential to ensure scalability and compliance with emerging European regulations.
The combination of large language models (LLM) and knowledge graphs, in what we are callingNeuro-symbolic AI, represents a promising avenue to explore, requiring rigorous experimentation and systematic investigation to discover synergies and maximize the potential of these domains.
Impact and Future Prospects
The WordLift NG project marks a significant milestone in the company’s pursuit of excellence in AI-driven semantic search and content generation. The achieved objectives underscore WordLift’s commitment to innovation and ability to adapt to the ever-changing technological landscape.
The pioneering spirit demonstrated throughout the project promises cutting-edge advancements, continued collaboration, and a steadfast commitment to reshaping the semantic search and knowledge representation world.
In the spirit of European innovation, WordLift stands ready to inspire, disrupt, and drive transformative change, propelling the company, its partners, and the industry toward new horizons of possibility.
When we think of bots, we either think of Star-Wars-like robots or humanoid androids communicating with us.
What are chatbots? Chatbots are computer programs built to communicate with humans using natural language. Usually, they handle customer service tasks, such as answering questions and booking appointments.
The primary purpose of chatbot systems is to retrieve valuable and relevant information from one or multiple knowledge bases by using natural language understanding (NLU) and semantic web technologies.
The problem
The web is packed with the most disparate information; it’s often hard for humans to classify and judge the quality of a source at first sight, so, in order to save time, which is our most valuable asset, we turn to machines to do the searching for us.
Technically speaking
Many chatbot systems are designed to require a lot of training data, which is unavailable and expensive to create. Recently, with the growth development of linked data, increasing progress on chatbots has been seen in research and industry. However, they face many challenges, including user query understanding, intent classification, multilingual aspect, multiple knowledge bases, and analytical queries interpretation.
Knowledge graphs are becoming more and more a standard technology for Companies, people, and publishers. A Knowledge-Graph-based bot is scalable, flexible, and dynamic.
Why Knowledge Graphs
A Knowledge Graph is a structure that portrays information as relationships and concepts connected to each other. Google was the first to mention Knowledge Graphs and the technology behind them back in 2012. You can find out more about why you need a Knowledge Graph, read our blog post.
Back to us now!
So we know that a chatbot needs a domain model in order to understand and answer user questions. In machine learning, we would generate a huge knowledge base of sentences and use cases, wasting time and resulting in a static chatbot, which the web is full of already.
Since a domain model collects information about a particular topic or subject, we can use a Knowledge Graph to store and retrieve information easily.
In this way, our chatbot would be dynamic and always up to date without manually adding and editing the knowledge base.
Advantages of Knowledge Graph-Based Chatbots
A chatbot based on a Knowledge Graph knows how to interpret requests from the users delivering meaningful answers straight away. Moreover, there won’t be a need for lengthy training.
Knowledge Graphs can be updated more efficiently simply by adding data and relationships to other entities.
How To Develop A Knowledge-Based Chatbot
First of all, there is the preparatory work for the Knowledge Graph, in which there should be a clear structure of concepts, entities, and relationships between them.
Then, the chatbot needs to “study” those rules, entities, and relations to answer questions.
These are three main flows that describe how to develop a conversational interface based on a Knowledge Graph:
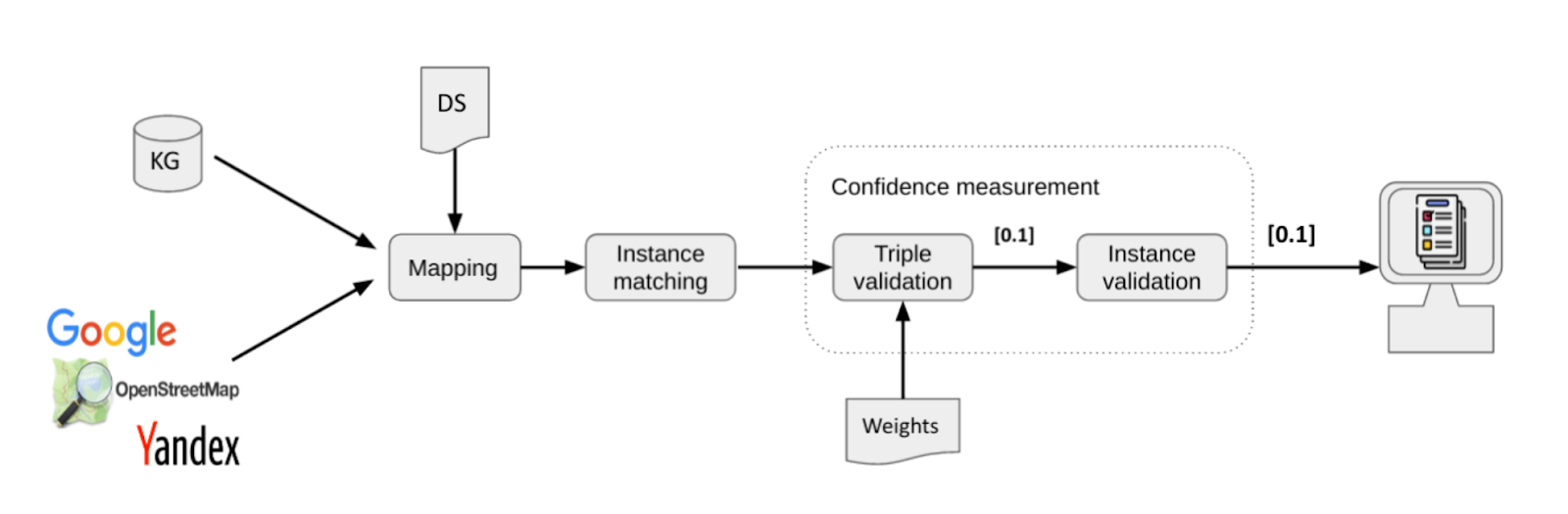
Pushing contents from the Knowledge Graph (KG) to the website/backend (via GraphQL interface) – the data present in the KG are made available through targeted queries.
Semantic content search on questions-answers (via search API) – the FAQ content is made available through targeted queries that can be consulted performing semantic search, which allows you to manage, if present, the intent associated with specific questions.
Natural language understanding and dialogue management (via NLU for intent management) – the KG data and the semantic search functions are operated by an external dialogue manager application that intercepts the user’s intent and retrieves the answers (accessing content either in the KG or from semantic search).
Knowledge Graph and GraphQL
The Knowledge Graph is fed with content flows from the CMS and through the NLP end-point, which analyzes the unstructured contents and organizes them semantically using the Company’s vocabulary containing the key concepts (entities).
The graph may contain different content types: FAQpages, NewsArticles, Articles, Offers… all useful to sustain a conversation flow that includes different nuances on the same topic, as a user might want to know a definition of a term or articles related to this term.
GraphQL is a query language and execution engine designed to implement API-based solutions that access information in the Knowledge Graph.
We use GraphQL as a query service, and its functions are available for data consultation only. Reading takes place through a different end-point.
GraphQL is used when users want to see all articles related to a topic.
Requests towards GraphQL are executed in the Knowledge Graph via authentication.
Semantic Search
This module integrates the API for semantic search to the knowledge base. A first usage scenario is based on the FAQ content present on the site today.
Later, it will be possible to extend the scope of use of this feature to all web content in the KG through the use of models for open-domain question answering (ODQA).
The search for answers (/ ask)
The answers to user questions are extracted through a semantic content search system.
This way, we can enable a classification algorithm that uses a transformer-based neural network to classify questions based on how “significant” they are in relation to the user’s query.
The use case is based on the following application flow:
The dialogue manager (NLU) identifies an intent that can be satisfied by FAQ content
The user’s question is delivered to the Search API
The Search API identifies the closest question-answer
The result is sent to the dialogue manager (NLU)
The dialogue manager via ECSS sends the response to the end-user
Understanding of natural language and dialogue management
We use a scalable architecture: the two main components are natural language understanding (NLU – Natural Language Understanding) and a dialogue management platform.
NLU deals with managing the classification of intentions, the extraction of entities, and the recovery of responses. In the diagram, it is represented as an NLU pipeline because it processes user expressions using an NLU model generated by the trained pipeline.
The dialogue management component determines the following action in a conversation based on context (the Dialogue Policies indicated in the diagram).
Conclusions
Knowledge Graphs are very powerful databases to develop a conversational marketing strategy, and when it comes to building a conversational interface, they stand out from other technologies in terms of:
Speed
Powerful interrelationships between concepts
Flexibility
Possibility to easily update the graph
Embed potentially unlimited knowledge
The goal of any bot is to provide valuable and relevant information to users, adapting to each context and request. And that’s what Knowledge Graphs do: they move and adjust.
In a world of infinite information, be the KG-powered bot!
On July 5th and 6th the team at WordLift reached Salzburg to meet the Consortium partners for the WordLift Next Generation project. As you may know, WordLift received a grant from the EU to bring its tools to any website and to perfect anyone’s semantic SEO strategy [link].
WordLift Next Generation is made up of WordLift, Redlink GmbH, SalzburgerLand Tourismus GmbH and the Department of Computer Science of the University of Innsbruck.The aim is to develop a new platform to deliver Agentive SEO technology to any website, despite its CMS, and to concretely extend the possibilities of semantic SEO in a digital strategy. The work started in January 2019 and is being developed in a 3-year timeframe.
The project started with a clear definition of the roles and responsibilities of each partner in the scope to improve WordLift’s backend to enrich RDF/XML graphs with semantic similarity indices, full-text search and conversational UIs. The main goals for the project are: being able to add semantic search capabilities to WordLift, improved content recommendations on users’ websites and the integrations with personal digital assistants.
Here is an example of the initial testing done with Google’s team on a mini-app inside Google Search and the Google Assistant that we developed to experiment with conversational user interfaces.
Artificial Intelligence is leading big companies’ investments, and WordLift NG aims at bringing these technologies to small/mid sized business owners worldwide.
In order to accomplish these ambitions goals the consortium is working on various fronts:
Development of new functionalities and prototypes
Research activities
Community engagement
What is WordLift NG?
The study for the new platform for WordLift’s clients started with a whole new user journey, including an improved UX. New features, developed with content analysis, include automatic content detection, specific web page markup, and knowledge graph curation.
The main benefit of this development is to exploit long tail queries to be featured as speakable (voice) tagging for search helpers. The new backend lets users create dedicated landing pages and applications with direct queries in GraphQL.
The new platform also provides users with useful information about data shared in the Knowledge Graph, including traffic stats, Structured Data reports.
The development of NG involves features to bring WordLift’s technology to any CMS, the new on-boarding WebApp is part of that.
Envisioning a brand new customer journey, built to help publishers get their SEO done with a few easy steps, the new on-boarding web app guides the setup for users not running their websites on WordPress.
The workshop held various demos for applications developed by partners.
WordLift showcased a demo for semantic search, a custom search engine that uses deep learning models while providing relevant results when queried. With semantic search one can immediately understand the intent behind customers and provide significantly improved search results that can drive deeper customer engagement.
This feature would have a major impact on e-commerces.
WordLift applied semantic search to the tourism sector and to e-commerce.
The backend of the platform is being developed by RedLink, on state-of-the-art technologies.
The services are issued within a cloud microservice architecture which makes the platform scalable, and the data that today are published with WordLift is hosted on Microsoft Azure.
It will provide specific services and endpoints for the text analysis (Named Entity Recognition and Linking) data management (public and private knowledge graphs and schema, data publication), search (full text indexing) and conversation (natural language understanding, question answering, voice conversation) for its users.
GraphQL was selected to facilitate access to data in the Knowledge Graph by developers. Tools for interoperability between GraphQL and SPARQL were also tested and developed.
Data curation and Validation
An essential phase of the project is the collection of requirements and state of the art analysis in order to guarantee a perfectly functioning and functional product.
The requirements for WordLift NG were developed by SLT, the partner network and STI.
The results of the research activities are aimed at:
enhancement of content analysis – read more about this here
analysis of the methodologies for the identification of similar entities (in order to allow, on the basis of the analysis of the pages in the SERP, the creation or optimization of relevant content already present in the Knowledge Graph)
the algorithms for data enrichment in the Knowledge Graph and reconciliation with data from different sources
On this front, the Consortium is currently working on the definition for SD verification and validation of Schema markup.
This phase will ensure all statements are:
Semantically correct
Corresponding to real world entities (annotations must comply with content present and validated on the web)
and that annotations are compliant with given Schema definitions (correct usage of schema.org vocabulary).
Community Engagement
Part of the project is the beta testing and the presentation of the platform to WordLift’s existing customers.
We’d be thrilled to share our findings on structured data with the SEO community and very happy to support open sharing of the best practices also from Google and Bing (both seem to be willing to share in machine-readable format the guidelines for structured data markup).
WordLift is an official member of the DBPedia community and will actively contribute to DBpedia Global. Find out more.
If you’re willing to know more about it, and to be included in the testing of the new features contact us or subscribe to our newsletter!
If you work in SEO, you have been reading about Google and Bing becoming semantic search engines but, what does Semantic Search really mean for users, and how things work under the hood?
Semantic Search helps you surface the most relevant results for your users based on search intent and not just keywords.
Semantic (or Neural) Search uses state of the art deep learning models to provide contextual and relevant results to user queries. When we use semantic search we can immediately understand the intent behind our customers and provide significantly improved search results that can drive deeper customer engagement. This can be essential in many different sectors but – here at WordLift – we are particularly interested in applying these technologies to: travel brands, e-commerce and online publishers.
Information is often unstructured and available in different silos, using semantic search our goal is to use machine learning techniques to make sense of content and to create a context. When moving from syntax (for example how often a term appears on a webpage) to semantics, we have to create a layer of metadata that can help machines grasp the concepts behind each word. Google defines this ability to connect words to concepts as “Neural Matching” or *super synonyms* that help better match user queries with web content. Technically speaking this is achieved by using neural embeddings that transform words (or other types of content like images, video or audio clips) to fuzzier representations of the underlying concepts.
As part of the R&D work that we’re doing, in the context of the EU-cofounded project called WordLift Next Generation, I have built the prototype using an emerging open-source framework called Jina AI and the beautiful photographic material published by Salzburgerland Tourismus (also a partner in the Eurostars research project) and Österreich Werbung 🇦🇹 (Austrian National Tourist Office).
I have created this first prototype:
☝️ to understand how modern search engines work;
✌️ to re-use the same #SEO data that @wordliftit publishes as structured *linked* data for internal search.
How does Semantic Search work?
Bringing structure to information, is what WordLift does by analyzing textual information using NLP and named entity recognition, and now also images using deep learning models.
With semantic search, these capabilities are combined to let users find exactly what they need naturally.
In Jina, Flows are high-level concepts that define a sequence of steps to accomplish a task. Indexing and querying are two separate Flows; inside each flow, we run parallel Pods to analyze the content. A Pod is a basic processing unit in a Flow that can run as a dockerized application.
This is strategic as it allows us to distribute the load efficiently. In this demo, Pods are programmed to create neural embeddings: one pod to processes text and one for images. Pods can also run in parallel and the results (embeddings from the caption and embeddings from the image) are combined into one single document.
This ability to work with different content types is called multi-modality.
The user uses a text in the query to retrieve an image or vice-versa; the user uses an image, in the query, to retrieve its description.
See in the example below; I make a search using natural language at the beginning and right after, I send an image (from the results of the first search) as query to find its description 👇
Are you ready to innovate your content marketing strategy with AI? Let’s talk!
What is Jina AI?
Han Xiao, Jina AI’s CEO, calls Jina the “TensorFlow” for search 🤩. Besides the fact that I love this definition, Jina is completely open source, and designed to help you build neural (or semantic) search on the cloud. Believe me it is truly impressive. To learn more about Jina, watch Han’s latest video on YouTube “Jina 101: Basic concepts in Jina“.
How can we optimize content for Semantic Search?
Here is what I learned from this experiment:
When creating content, we shall focus on concepts (also referred to as entities) and search intents rather than keywords. An entity is a broader concept that groups different queries. The search intent (or user intent) is the user’s goal when making the query to the search engine. This intent can be expressed using different queries. The search engines interpret and disambiguate the meaning behind these queries by using the metadata that we provide.
Information Architecture shall be designed once we understand the search intent. We are used to thinking in terms of 1 page = 1 keyword, but in reality, as we transition from keywords to entities (or concepts), we can cover the same topic across multiple documents. After crawling the pages, the search engine will work with a holistic representation of our content even when it has been written across various pages (or even different media types).
Adding structured data for text, images, and videos adds precious data points that will be taken into account by the search engine. The more we provide high-quality metadata, the more we help the semantic search engine improve the matching between content and user intent.
Becoming an entity in Google’s Knowledge Graph also greatly helps Google understand who we are and what we write about. It can have an immediate impactacross multiple queries that refer to the entity. Read this post to learn more how to create an entity in Google’s graph.
Working with Semantic Search Engines like Google and Bing, require an update of your content strategy and a deep understanding of the principles of Semantic SEO and machine learning.











Recent Comments