
GraphSPARQL: A GraphQL interface for Linked Data
If you are a developer, you probably have already worked with or heard about SEO (Search Engine Optimization).
Nowadays, when optimizing websites for search engines, the focus is on annotating websites’ content so that search engines can easily extract and “understand” the content.
Annotating, in this case, is the representation of information presented on a website in a machine-understandable way by using a specific predefined structure.
Noteworthy, the structure must be understood by the search engines.
Therefore, in 2011 the four most prominent search engine providers Google, Microsoft, Yahoo!, and Yandex, founded Schema.org.
Schema.org provides patterns for the information you might want to annotate on your websites, including some examples.
Those examples allow web developers to get an idea of making the information on their website understandable by search engines.
Knowledge Graphs
Besides using the websites’ annotations to provide more precise results to the users, search engines use them to build so-called Knowledge Graphs.
Knowledge Graphs are huge semantic nets describing “things” and their connections between each other.
Consider three “things”, i.e. three hiking trails “Auf dem Jakobsweg”, “Lofer – Auer Wiesen – Maybergklamm” and “Wandergolfrunde St. Martin” which are located in the region “Salzburger Saalachtal” (another “thing”). “Salzburger Saalachtal” is located in the state “Salzburg,” which is part of “Austria.” If we drew those connections on a sheet, we would end up with something that looks like the following.

This is just a small extract of a Knowledge Graph, but it shows pretty well how things are connected with each other. Search engine providers collect data from a vast amount of websites and connect the data with each other. Not only search engine providers are doing so but even more companies are building Knowledge Graphs. Also, you can build a Knowledge Graph based on your annotations, as they are a good starting point. Now you might think that the amount of data is not sufficient for a Knowledge Graph. It is essential to mention that you can connect your data with other data sources, i.e., link your data or import data from external sources. There exists a vast Linked Open Data Cloud providing linked data sets of different categories. Linked in this case means that the different data sets are connected via certain relationships. Open implies that everyone can use it and import it into its own Knowledge Graph.
An excellent use case for including data from the Linked Open Data Cloud is to integrate geodata. For example, as mentioned earlier, the Knowledge Graph should be built based on the annotations of hiking trails. Still, you don’t have concrete data on the cities, regions, and countries. Then, you could integrate geodata from the Linked Open Data Cloud, providing detailed information on cities, regions, and countries.
Over time, your Knowledge Graph will grow and become quite huge and even more powerful due to all the connections between the different “things.”
Sounds great, but how can I use the data in the Knowledge Graph?
Unfortunately, this is where a huge problem arises. For querying the Knowledge Graph, it is necessary to write so-called SPARQL queries, a standard for querying Knowledge Graphs.
SPARQL is challenging to use if you are not familiar with the syntax and has a steep learning curve. Especially, if you are not into the particular area of Semantic Web Technologies.
In that case, you may not want to learn such a complex query language that is not used anywhere else in your daily developer life.
However, SPARQL is necessary for publishing and accessing Linked Data on the Web.
But there is hope. We would not write this blog post if we did not have a solution to overcome this gap. We want to give you the possibility, on the one hand, to use the strength of Knowledge Graphs for storing and linking your data, including the integration of external data, and on the other hand, a simple query language for accessing the “knowledge” stored. The “knowledge” can then be used to power different kinds of applications, e.g., intelligent personal assistants. Now you have been tortured long enough. We will describe a simple middleware that allows you to query Knowledge Graphs by using the simple syntax of GraphQL queries.
What is GraphQL?
GraphQL is an open standard published in 2015, initially invented by Facebook. Its primary purpose is to be a flexible and developer-friendly alternative to REST APIs. Before GraphQL, developers had to use API results as predefined by the API provider even if only one value was required by the user of the API. GraphQL allows specifying a GraphQL query in a way that only the relevant data is fetched. Additionally, the JSON syntax of GraphQL makes it easy to use. Nearly every programming language has a JSON parser, and developers are familiar with representing data using JSON syntax. The simplicity and ease of use also gained interest in the Semantic Web Community as an alternative for querying RDF data. Graph database (used to store Knowledge Graphs) providers like Ontotex (GraphDB) and Stardog introduced GraphQL as an alternative query language for their databases. Unfortunately, those databases can not be exchanged easily due to the different kinds of GraphQL schemas they require. The GraphQL schema defines which information can be queried. Each of the database providers has its own way of providing this schema.
Additionally, the syntax of the GraphQL queries supported by the database providers differs due to special optimizations and extensions. Another problem is that there are still many services available on the Web that are only accessible via SPARQL. How can we overcome all this hassle and reach a simple solution applicable to arbitrary SPARQL endpoints?
GraphSPARQL
All those problems led to a conceptualization and implementation of a middleware transforming GraphQL into SPARQL queries called GraphSPARQL. As part of the R&D work that we are doing, in the context of the EU-cofounded project called WordLift Next Generation , three students from the University Innsbruck developed GraphSPARQL in the course of a Semantic Web Seminar
Let us consider the example of a query that results in a list of persons’ names to illustrate the functionality of GraphSPARQL. First, the user needs to provide an Enriched GraphQL Schema, in principle defining the information that should be queryable by GraphSPARQL. This schema is essential for the mapping between the GraphQL query and the SPARQL query.
The following figure shows the process of an incoming query and transforming it to a SPARQL query. If you want to query for persons with their names, the GraphQL query shown on the left side of the figure will be used. This query is processed inside GraphSPARQL by a so-called Parser. The Parser uses the predefined schema to transform the GraphQL query into the SPARQL query. This SPARQL query is then processed by the Query Processor. It handles the connection to the Knowledge Graph. On the right side of the figure, you see the SPARQL query generated based on the GraphQL query. It is pretty confusing compared to the simple GraphQL query. Therefore, we want to hide those queries with our middleware.
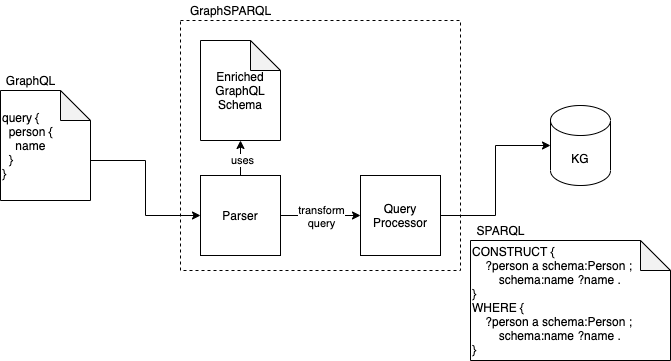
As a result of the SPARQL query, the Knowledge Graph responds with something that seems quite cryptic, if you are not familiar with the syntax. You can see an example SPARQL response on the following figure’s right side.
This cryptic response is returned to the Parser by the Query Processor. The Parser then, again with the help of the schema, transforms the response into a nice-looking GraphQL response. The result is a JSON containing the result of the initial query.
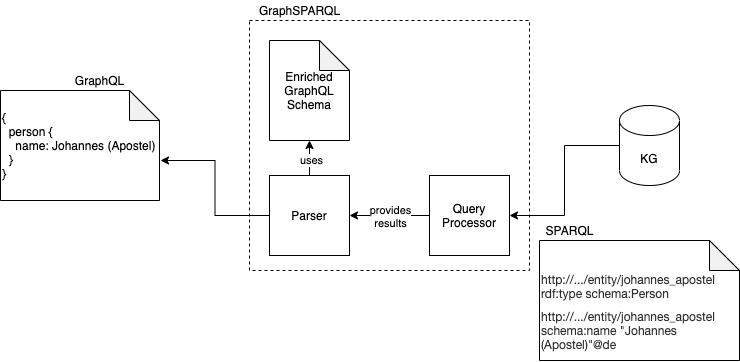
GraphSPARQL provides you easy access to the information stored in a Knowledge Graph using the simple GraphQL query language.
You have a Knowledge Graph stored in a graph database that is accessible via SPARQL endpoint only? Then GraphSPARQL is the perfect solution for you. Before you can start, you need to follow two configuration steps:
- Provide the so-called Enriched GraphQL Schema. This schema can either be created automatically based on a given ontology, e.g., schema.org provides its ontology as a download or can be defined manually. An example for both cases can be found on the GraphSPARQL Github page in the example folder:
– automatic creation of a schema based on the DBPedia ontology
– manually defined schema
- Define the SPARQL endpoint GraphSPARQL should connect to. This can be done in the configuration file (see “config.json” in the example folder).
Have you done both preparation steps? Perfect, now you are ready to use GraphSPARQL on the endpoint you defined.
Check the end of the blog post if you are interested in a concrete example.
Summary
– What are the benefits of GraphSPARQL?
– Benefit from Knowledge Graphs by using a simple query language
– Simple JSON syntax for defining queries
– Parser support for the JSON syntax of GraphQL queries in nearly all programming languages
– GraphQL query structure represents the structure of the expected result
– Restrict data access via the provided GraphQL schema
GraphSPARQL as middleware allows querying SPARQL endpoints using GraphQL as a simple query language and is an important step to open Semantic Web Technologies to a broader audience.
Example
Docker container to test GraphSPARQL:
Two options to start the docker container are supported so far:
- Use predefined configuration for DBPedia: start the GraphSPARQL docker container
docker run -d -p 80:80 kev09ang/graph_sparql - Customized configuration:
Go to https://github.com/Meitinger/GraphSPARQL
Check the example folder for config files, ontologies (dbpedia.owl) and schemas (sample1.json)
Create locally a file named `config.json` linking to an ontology or a schema
Start the docker container by mounting the folder containing your custom configuration:
docker run -d -p 80:80 -v :/App/configuration kev09ang/graph_sparqlOpen your web browser and open http://localhost/ui/graphiql
Enter the following query to retrieve information on the state of Salzburg in Austria
query
administrativeRegion(filter:"?label ='Salzburg (state)'@en"){
id
label (filter:"lang(?) ='en'")
abstract (filter:"lang(?) ='en'")
country {
label (filter:"lang(?) ='en'")
abstract (filter:"lang(?_) ='en'")
}
populationTotal
}}
If you want to know which other fields you can query, use the `_fields` command, e.g.:
JSON
query {
_fields
}
as a response you get a list of fields you can use for your GraphQL query:
{
"data": {
"_fields": [
"_fields",
"abbey",
"academicJournal",
"activity",
"actor",
"administrativeRegion",
"adultActor",
"agent",
...
]
}
}
Recent Comments