Image SEO: optimizing images using machine learning
Images contribute to improve SEO and the user experience on a website. Learn how we used neural networks to describe the content of images.

In this article, I will share my findings while evolving how we use neural networks to describe the content of images. Images greatly contribute to a website’s SEO and improve the user experience. Fully optimizing images is about helping users, and search engines, better understand an article’s content or the product’s characteristics.
The SEO community has always been keen on recommending publishers and shop owners invest in visual elements. This has become even more important in 2023 as Google announced that over 10 billion people already use Lens.
With our next generation of AI-powered technology, we’re making it more visual, natural and intuitive to explore information.
Elizabeth Reid VP, Search at Google
Table of content:
- Google’s Image SEO best practices in 2023
- What is Agentive SEO
- How to enrich image alt text on your website using AI.
- Evaluating language-vision models
- Introducing LAVIS (short for LAnguage-VISion)
- Evaluating language-vision models
- Running the workflow for automatic image captioning
- Content moderation
- Get Comfortable with experiments
- Don’t settle for less than the best model
- Visual Question Answering (VQA)
- Conclusions
- How I worked a few years ago
- Report from the first experiments using CNN and LSTM
- Last but not least: Image SEO Resolution

There are several aspects that Google mentions in its list of best practices for images that have been recently updated, but the work I’ve been focusing on, for this article, is about providing alt text and captions in a semi-automated way. Alt text and captions, in general, improve accessibility for people that use screen readers or have limited connectivity and help search engines understand what the content of an article is about or what product we are trying to sell.
We simply know that media search is way too ignored for what it’s capable doing for publishers so we’re throwing more engineers at it as well as more outreach.
Gary Illyes, Google’s Chief of Sunshine and Happiness & trends analyst
Let’s start with the basic of Image SEO with this historical video from Matt Cutts that, back in 2007, explained to webmasters worldwide the importance of descriptive alt text in images.
Google’s Image SEO Best Practices In 2023
If you want to understand how images work on Google, I would suggest also watching John Mueller’s latest video on SEO for Google Images.
To summarize, here are the key issues highlighted in Google’s recent update of its documentation for image SEO:
- Addition of “When possible, use filenames that are short, but descriptive.“, more emphasis on avoiding generic filenames and removing the need to translate filenames – in line with John Mueller’s advice.
- From “choosing” to “writing” ALT text – a small change that could be referring to having human-curated ALTs for web accessibility rather than automated and “chosen” ALTs for the benefit of search engines (one of the reasons we are focusing on this area).
- Replaced the example.jpg with a descriptive filename example maine-coon-nap-800w.jpg.
The credit for spotting this update fully goes to @roxanastingu (head of SEO in Alamy).
There have been some *slight* changes to Google's Image SEO best practices. https://t.co/YUYDWfSOPR
— Roxana Stingu (@RoxanaStingu) February 1, 2023
New version on the left, old on the right with commentary in the🧵 pic.twitter.com/CDe8eWrdxm
What is Agentive SEO
In WordLift we build agentive technologies for digital marketers. I had the pleasure of meeting Christopher Noessel in San Francisco and learned from him the principles of agentive technology (Chris has written a terrific book that I recommend you to read called Designing Agentive Technologies).
One of the most critical aspects of designing agentive tech is to focus on efficient workflows to augment human intelligence with the power of machines by considering the strengths and limitations of today’s AI.
I have been working on this specific task for several years now. I have seen the evolution of deep learning models, vision APIs, and procedures dealing with image and natural language processing. I started in 2020 using a pre-trained convolutional neural network (CNN) that extracted the features of the input image. This feature vector was sent to an RNN/LSTM network for language generation.
In 2023 with the advent of Generative AI technology, we can introduce completely new workflows that leverage the power of transformer-based models trained on multimodal content. The technology we use has dramatically improved.
How To Enrich Image Alt Text On Your Website Using AI
Evaluating language-vision models
Evaluating automatic image captioning systems is not a trivial task. Still, it remains an exciting area of research, as human judgments might only sometimes correlate well with automated metrics.
To find the best system, I worked on a small batch of images (50) and used my judgment (as I worked on a domain I was familiar with) to rank the different models. Below is an example of the output provided by a selection of models when analyzing the image on the right.

I am generally less interested in the model and more interested in finding the proper framework to work on the different tasks using different models. While running these analyses, I found a modular and extensible library by Salesforce called LAVIS for language-vision AI.
Introducing LAVIS (short for LAnguage-VISion)
LAVIS is a library for language-vision intelligence written in Python to help AI practitioners create and compare models for multimodal scenarios, such as image captioning and visual inferencing.
LAVIS is easy to use and provides access to over 30 pre-trained and task-specific fine-tuned model checkpoints of four popular foundation models: ALBEF, BLIP, CLIP, and ALPRO.
While testing different models in LAVIS, I decided to focus on BLIP2, a contrastive model pre-trained for visual question answering (VQA).

These systems combine the ability to extract features from images provided by BLIP2 with frozen large language models such as Google’s T5 or Meta’s OPT. A frozen language model is a pre-trained language model with its parameters fixed and can no longer be updated.
In NLP, this term is commonly used to refer to models used for specific tasks such as text classification, named entity recognition, question answering, etc. These models can be fine-tuned by adding a few layers to the top of the pre-trained network and training these layers on a task-specific dataset. Still, the underlying parameters remain frozen and do not change during training. The idea behind this approach is to leverage the knowledge and understanding of language learning by the pre-trained model rather than starting from scratch for each new task.
Running The Workflow For Automatic Image Captioning

In this experiment, we proceed by analyzing a selection of the editorial images taken from the homepage of fila.com (not a client of ours, I used it already in the past for the e-commerce internal linking analysis).
These images are particularly challenging as they don’t belong to a specific product or category of products but help communicate the brand’s feelings. By improving the alt text, we want to make the homepage of fila.com more accessible to people with visual disabilities. Web accessibility deeply interconnects with SEO.
The code is accessible and described in a Colab Notebook.
We proceed as follows:
- We start with Google Sheets (here), where we store information on the media files we want to analyze. We use the gspread library to read and write back to Google Sheets.
- We run the Colab (you will need Colab Pro+ if you want to run the tests on the different options, otherwise, use the simpler model, and you might be able to run it also on a CPU)
- We run a validation of the data and some minimal data cleaning (the work here is brief, but in production, you will need to get more into the details).
- To ensure the text doesn’t contain any inappropriate content, we use the OpenAI moderation end-point. You will need to add your OpenAI key.
- We also work on rewriting the brand name (from “fila” to “FILA”). This is purely an example to show you that once you have the caption, more can be done by leveraging, for example, the information on the page, such as the title and the meta description or any other editorial rule.
- We can now add back the descriptions in Google Sheets, and from there, we will add them to the content management system.
Content moderation
When dealing with brands, we must protect the customer’s relationship. Automating SEO using ChatGPT is fascinating and highly accessible. Still, when starting a project like setting up a model for automating image captioning, I usually receive the following question “is it safe to use AI?”.
We must be cautious and protect the client’s website against possible misuse of the language. The minimum we can do is work with a moderation endpoint like the one provided by OpenAI for free. It uses a GPT-based classifier, is constantly updated, and helps us detect and filter undesired content.

As we can see from the code snippet below, if we send the first caption being generated, we expect the moderation endpoint to return “False”; when trying instead with a violent sentence like the one below, we expect to receive “True.”

Keep on reading if you are interested in Visual Question Answering experiments or simply access to the code developed while working for one of the clients of our SEO management services.
Get Comfortable With Experiments
Machine learning requires a new mindset different from our traditional programming approach. You tend to write less code and focus most of the attention on the data for training the model and the validation pipeline. Validation is essential to ensure that the AI content is aligned with the brand’s tone of voice and compliant with SEO and content guidelines.
Don’t Settle For Less Than The Best Model
Rarely in our industry can we safely opt for the trendiest model or the most popular API. Setting up your own pipeline for training an ML model, if you are building a product that thousands of people will benefit from is always the recommended path. I could quickly evaluate the results from BLIP, BLI2-OPT, and BLIP2-T5 out of the box using LAVIS. Here below, you can find the percentage of accurate captions generated by each model.
As you can see, based on the human judgment of our SEO team, we generated a suitable caption 71.6% of the time. This percentage dramatically increased as we introduced some basic validation rules (like the rewriting of the brand name from “fila” to “FILA”). These simple adjustments and the fine-tuning of the model typically help us bring the percentage of success above 90%.

Visual Question Answering (VQA)
Using LAVIS, we can also experiment with more advanced use cases like VQA: a computer vision task where given a text-based question about an image, the system infers the answer. Let’s review it in action using one of the sample images.

As we can see, the model recognizes and highlights the FILA logo (at least one of the two) in the image.
Conclusions
Experimenting in ML is essential in today’s SEO automation workflows. Many resources, including pre-trained machine learning models and frameworks like LAVIS, can encode knowledge to help us in SEO tasks.
Below we can appreciate the evolution of the technology and how an image of Bill Slawski (whom I miss a lot 🌹) alongside a young Neil Patel is captioned now and how it was captioned a few years back.

How I Worked A Few Years Ago
Here follows how this workflow was originally implemented back in 2019. I left the text untouched as a form of AI-powered SEO archeology to help us study the evolution of the techniques.
Report from the first experiments on automatic image captioning using CNN and LSTM
Armed with passion and enthusiasm I set up a model for image captioning roughly following the architecture outlined in the article “Automatic Image Captioning using Deep Learning (CNN and LSTM) in PyTorch“ that is based on the results published in the “Show and Tell: A Neural Image Caption Generator” paper by Vinyals et al., 2014.
The implementation is based on a combination of two different networks:
- A pre-trained resnet-152 model that acts as an encoder. It transforms the image into a vector of features that is sent to the decoder
- A decoder that uses an LSTM network (LSTM stands for Long short-term memory, and it is a Recurrent Neural Network) to compose the phrase that describes the featured vector received from the encoder. LSTM, I learned along the way, is used by Google and Alexa for speech recognition. Google also uses it in Google Assistant and in Google Translate.

One of the main datasets used for training in image captioning is called COCO and is made of a vast number of images; each image has 5 different captions that describe it. I quickly realized that training the model on my laptop would have required almost 17 days of non-stop with the CPU running at full throttle. I had to be realistic and downloaded the available pre-trained model.
RNNs for sure, are not hardware friendly and use enormous resources for training.
Needless to say, I remained speechless as soon as everything was in place, and I was ready to make the model talk for the first time. By providing the image below, the result was encouraging.

![]()
Unfortunately, as I moved forward with the experiments and from the giraffes moved into a more mundane scenery (the team in the office) the results were bizarre, to use a euphemism, and far from being usable in our competitive SEO landscape.
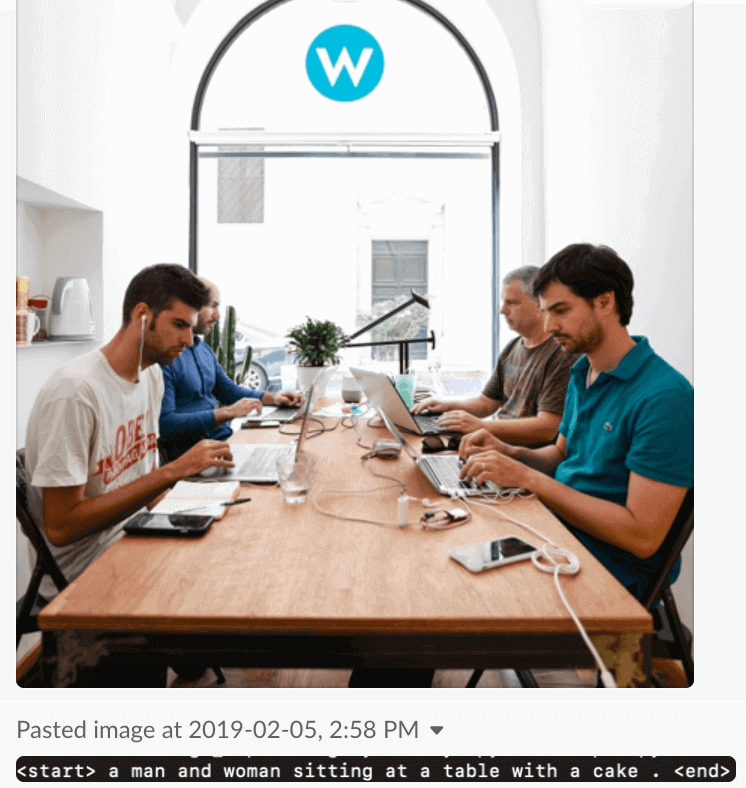

![]()
Last but not least: Image SEO Resolution
Another important aspect of images in SEO is resolution. Large images, in multiple formats (1:1, 4:3 and 16:9) are needed by Google to present content in carousels, tabs (rich results on multiple devices) and Google Discover. This is done using structured data and following some important recommendations.
WordLift automatically creates the three versions required by Google for each image, as long as you have at least 1,200 pixels on the smaller side of the image. Since this isn’t always possible, we’ve trained a model that can enlarge and enhance the images on your website using the Super-Resolution technique for images.
This is the AI-powered Image Upscaler and if you want to learn more about it, how to use it for your image and what results you can get, you can read our article.
References
- Google image SEO best practices
- Designing Agentive Technology – Christopher Noessel
- Meet LAVIS: A One-stop Library for Language-Vision AI Research and Applications – Dongxu Li, Junnan Li, Steven Hoi, Donald Rose
- Automatic Image Captioning using Deep Learning (CNN and LSTM) in PyTorch – JalFaizy Shaikh
- Show and Tell: A Neural Image Caption Generator – Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan – Cornell University
- Deep Residual Learning for Image Recognition – Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun – Cornell University
- Learning to Evaluate Image Captioning – Yin Cui, Guandao Yang, Andreas Veit, Xun Huang, Serge Belongie – Cornell University
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models – Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi – Cornell University
Learn more about SEO image optimization, see our last web story.