
This article is about putting to use Machine-Readable Entity IDs to gain back control of the data that matters for you or your business and to help others find you unambiguously and… yes, this does lead to better SEO. ?
While considered an advanced SEO strategy by some, creating and managing Machine-Readable Entity, is a new way to do content curation and to revitalize traditional backlinking. It is indeed also about taking back control of the data but, let’s start from the beginning.
The web is a matrix really, an intricate maze made of convoluted patterns that for many years search engines have helped us solve by proposing us the best pathways to learn more about a topic, to help us find the very best sushi restaurant in our neighborhood and…let’s be frank, to watch endless videos of kittens jumping around.

What are Machine-Readable Entity IDs?
An entity IDs is a unique identifier for a single thing, person, place, or object that a machine can understand. In the field of information extraction entity IDs or named entities can be abstract concepts like compassion or have a physical existence like WordLift, our startup.
Check your website’s machine readability with our free AI audit tool.
Let’s make a step backward. How is knowledge organized in libraries?
In the physical world knowledge for centuries has been condensed into books and books have been organized in libraries. Every book inside a library use a code like 615.1 INT and this code follows a scheme called the Dewey Decimal Classification system. This system uses numbers from 000 to 999 to describe a specific subject area (ie. 300 for Social Science and 700 for Arts and Recreation and so on). Decimal points are used to drill down into a specific knowledge domain, for example, Pharmacology is characterized by the code 615.1. The three letters following this number, are usually taken from either the title of the book or from its author. The shelfmark that we usually find in a library on the spine of a book is the equivalent of an Entity ID in the World Wide Web.
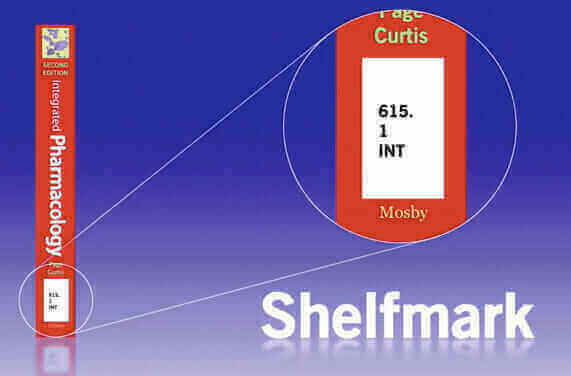
Wikidata 101 for SEO
The equivalent of a library for books, in the realm of structured data, is Wikidata. “A free, linked database that can be read and edited by both humans and machines” (so we read on the main page). Wikidata is a focal point for all Wikimedia projects including Wikipedia, Wikivoyage, Wikisource but most importantly it can be interlinked with other open datasets on the linked data web.
Why is Wikidata important for SEO?
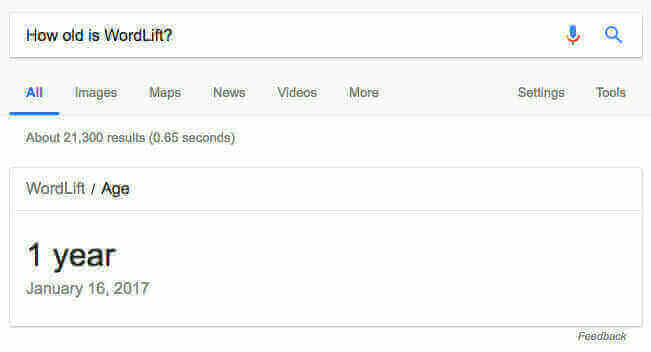
Search Engines like Google, Bing , and Yandex use Wikidata as one of their sources to answer to users queries like “how old is WordLift?”
Wikidata structures information in a semantic network of entities, attributes , and relationships that allow a machine to tap into a vast knowledge base of facts. It is a very broad knowledge base entirely built on the principles of linked data with both machine-extracted information from wikipedia, contributions from the crowd and automated data curation.
It also provides a public, accessible and super fast SPARQL 1.1 end-point that can be used to develop linked data application.
How is Wikidata organized?
Wikidata’s somehow obscure and criticized data model (read Paul Wilton’s article if you want to dig deeper into the bad and the ugly parts of Wikidata ? it is very instructive) starts with entities (or Items as they are called in Wikidata). Every entity has its own unique identifier that starts with a Q like Q149 for the world famous meme of Nyan Cat ?. For each entity that are individual statements (or facts) made of claims that are composed of properties and values with qualifiers that are, hopefully, sustained by at least one reference. Nyan Cat has an official website for instance Property:P856 in Wikidata) accessible at the url http://www.nyan.cat/ (and no references nor qualifiers in this specific example).
Everyone can contribute and there is a broad selection of properties in the Wikidata ontology that can help us describe concepts we’re familiar with. My very personal advice is to start by looking at existing items, carefully review the interactive tutorials or play the Wikidata Game but above all always remember that Wikidata is a community-driven initiative (and you need to be very respectful of others) and that data quality is crucial!
How can I backlink my data from Wikidata? Does it really matter?
Backlinking is still extremely valuable in today’s SEO. The quantity, the quality and the relevance of backlinks are among the factors search engines use to evaluate a page.
When it comes to data published in large graphs like Wikidata or DBpedia things are somehow similar. An entity can be linked to an equivalent entity in another knowledge graph as long as it is published following the Linked Data principles. This is important for two reasons:
- a machine (a crawler, an application or a smart agent) can disambiguate the entity and get a clear evidence that we’re referring to the same concept, person, thing or organization
- a machine can gather more information (in the form of statements) for that same entity
Let’s have a look at an example. Here I am, this is my entity on Wikidata.
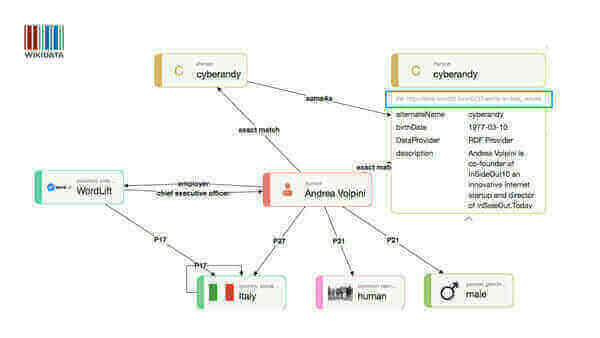
You can see in the visualisation that I am using Wikidata Property:P2888 exact_match to create a link between my instance on Wikidata Q28085380 and the entity created with WordLift and published as linked data on http://data.wordlift.io/wl0216/entity/andrea_volpini.html
This way it becomes possible for a machine:
- to easily disambiguate me from my esteemed homonyms,
- to understand from Wikidata that I work for WordLift (
Property:P108in Wikidata) and that I am friend with Teodora Petkova (schema:knowslink’s Teodora’s entity onhttp://data.wordlift.io/wl0216/entity/teodora_petkova).
Two different statements, in this example, are inferred from two knowledge bases that have been interlinked in both directions using Wikidata’s exact_match property and owl:sameAs (to connect Wikidata’s entity from the entity on data.wordlift.io).
The impact of Machine-Readable IDs on Google Search
Google is using Machine-Readable IDs (MREIDs) across multiple services including Google Trends, Google Maps, Google Lens and Google Reverse Image Search but above the user experience on Google Search is deeply influenced by MREIDs and the semantic networks behind it. As noted by Mike Arnesen in his latest articles on Leveraging Machine-Readable Entity IDs for SEO Google now uses two different classes of entities:
- Freebase Machine-Readable IDs for entities being discovered and created while Freebase was still available. They use the format
/m/[a-z0-9]+(Here is my entity created a long time ago/m/0djtw2hthat is behind my knowledge graph. - New Machine-Readable IDs for entities created after Freebase was terminated. They use the format
/g/[a-z0-9]+(here is the entity for Gennaro Cuofano/g/11f3sj8_tw
6 steps to master your own SEO-friendly Machine-Readable Entity IDs
We use and test different approaches on a regular basis and here is the ultimate list to boost your MREIDs.
- Use structured data in your web pages and reference back (or interlink) linked data entities, Wikidata Items or existing MREIDs from Google using the schema:sameAs property. Do the same with any Social Media presence you might have. Search Engines are well aware of Social Profiles and can infer more information from there as long as you are giving them the confidence that this is the right entity. See the example below ?
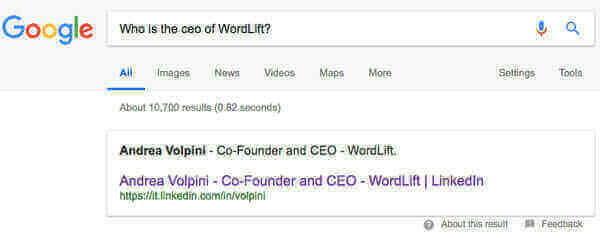
This is a featured snippet that Google created from my LinkedIn account whose statement is “confirmed” by the data published on data.wordlift.io and Wikidata. Featured snippets are extremely volatile because they tend to be error-prone. On the contrary, when enough data is provided on other well-known data sources, it gets easier for a search engine to trust the validity of the statement and to display. There is an interesting patent that Bill Slawski discovered a while ago on how Google might use a Knowledge Base Trust to asses the validity of a statement being scraped from a website.
- If you are dealing with a Business or an Organisation make sure the Google My Business has been created and it is well managed.
- Publish metadata in linked data using WordLift or any tool you might like. It is the most accessible and standard way to speak to machines. Linked data and Semantic Technologies provide a formal way to publish entities, terms, and relationships within a given knowledge domain. Search engines, more and more are depending on innovative artificial intelligence features like Google’s Featured Snippets and do require semantically rich data.
- Curate entities that matter for you and your business on Wikipedia and Wikidata. Use for Wikidata the
exact_matchProperty:P2888property to interlink entities that you have published as linked data and mentioned with the structured data on your website. - Verify your Entity on Google. Since few weeks Google introduced the possibility for any person, organization, sports team, event and media property with an existing Knowledge Panel, to get verified and to suggest edits to the information presented in the SERP (read it all here from the Google’s blog). It is a super simple process and the most direct way to suggest edits that will be added to the Google Knowledge Graph. You can start by clicking on the phrase that starts with “Do you manage the online presence for xyz?”. You will receive an email from The Google Search Team that will allow you to keep the data on Google always up to date.

 The email from The Google Search Team after being verified
The email from The Google Search Team after being verified- Pay attention to the multiple sources that a search engine might use to infer its knowledge and do your best to curate the entities you care about. Local directories like Yelp, for instance, are extremely valuable as they are considered trustworthy by search engines and personal digital assistant like Apple Siri. To let a machine properly match an entity available on a third party directory like 9 Yelp make sure that the Name, the Address, and the Phone number are always consistent with the data published on your website.
How can I link an entity in the Google Knowledge Graph with the same entity in Wikidata?
If you are dealing with an entity that has already a MREIDs in the Google Knowledge Graph and you want to link the entity with the equivalent entity in Wikidata you have two options:
- For FreebaseMachine-Readable IDs of entities created in the Freebase era you can use the property
Freebase ID (Property:P646) - For New Machine-Readable IDs of entities created after Freebase that use the format
/g/[a-z0-9]+you can use theGoogle Knowledge Graph ID (Property:P2671)
Conclusions
Taking control of your data is vital, it is true for SEO but it is also true to keep the web an open and democratic platform as recently said by Tim Berners-Lee on Vanity Fair.
Handling consciously the data that machines use for delivering services to billions of connected people is the first step to a more decentralized web infrastructure.
Creating your own Machine-Readable Entity with linked data means that you can choose where your data is stored and what applications can use this data. Imagine the difference between having your own website for promoting your business or using a Facebook Page.
Letting crawlers, search engines and social networks access our data using unique identifiers that we can control is different from having them entirely manage our own content and digital identities.