Natural Language Generation (NLG) is the use of artificial intelligence (AI) to generate written or spoken narratives from a set of data. NLG is related to human-computer and machine-human interaction, including computational linguistics, natural language processing (NLP), and natural language understanding (NLU).Sophisticated NLG software can be trained on large amounts of data, large amounts of numerical data, recognize patterns, and information in a way that is easy for humans to understand.
What is the difference between Natural Language Processing (NLP) and Natural Language Generation (NLG)?
NLP (Natural Language Processing) uses methods from various disciplines, such as computer science, artificial intelligence, linguistics, and data science, to enable computers to understand human language in both written and verbal forms. NLG (Natural Language Generation) is the process of producing a human language text response based on some data input. So, NLP accurately converts what you say into machine-readable data so that NLG can use that data to generate a response.
Originally, NLG systems used templates to generate text. Based on certain data or a query, an NLG system filled in the blank text. Over time, however, natural language generation systems have evolved to allow more dynamic, real-time text generation through the use of neural networks and transformers.
How can NLG help improve SEO?
Natural language generation has some incredible implications for your SEO strategy.
By using NLG systems, more content can be created faster. Not only does this save time, but it allows website owners, especially in e-commerce, to create content on a large scale.
However, when working with AI text generation for SEO, we need to be even smarter and more critical than usual. To create tangible and sustainable business value, we need to create workflows where humans collaborate with machines.
This means that we should not (yet) use GPT-3 or other transformer-based language models by letting them run free. We need to keep “control” over content quality and semantic accuracy to avoid unwanted biases and prejudices. Within this workflow, humans have the main task of nurturing semantically rich data in Knowledge Graphs.
The human side can be encoded in a knowledge graph. When we look at embedding the Knowledge Graph behind our blog for an entity like AI, the closest relationship in our small world leads us to SEO. Editors over the years have established this relationship between AI and SEO on our blog, and we can now use it to “control” content creation around one of these concepts.
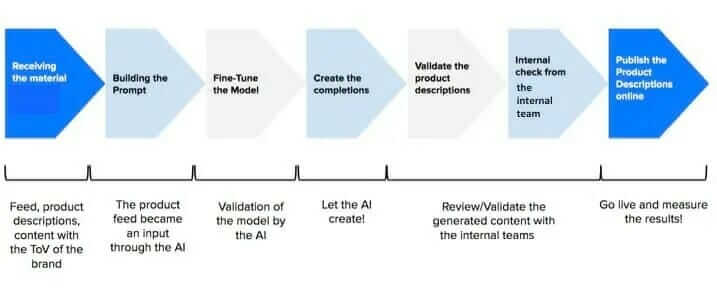
In WordLift, we have developed a sophisticated approach to AI-generated content where we move from initial data collection and enrichment to active learning where the model is improved and the validation pipeline is also improved. The workflow consists of 4 steps as shown in the figure below.
What Google says about AI-generated content
Google’s Helpful Content Update, released in August of this year, has reignited the discussion around AI-generated content and how Google is addressing it.
Although not explicit, in the update Google confirms its aversion to AI-generated content and talks about content that is high quality and meets the needs of users, content that is written by people for people. Google wants to avoid low-quality content written for search engines and not for users.
The reasons for Google’s aversion to AI-generated content may be many, but the fact is that there are some truths to consider. The first is that AI-generated content performs well in search if it is of high quality. The second is that AI-generated content is still not easy to scale. Training the models is very tedious and there is still not complete confidence in the results obtained.
So what makes the difference? What makes high-quality AI-generated content that does not risk Google (and user) penalties? The answer is simple: data. As Kevin Indig also said: The biggest differentiator will be what inputs (data) companies can use to create content. And that’s where structured data comes in.
Data-to-Text Generation
The key is to build a large dataset that you can keep adding to and that can provide potential insights. GPT-3 will help you extract valuable insights from it.
Daniel Ericksson, CEO at Viable.
The crucial part of using NLG for AI-generated content in SEO is semantically rich data (that might also be beneficial for structured data). Language models trained on billions of sentences learn common language patterns and can generate natural-sounding sentences by predicting likely word sequences. However, when generating data in text, we want to produce language that is not only fluent, but also accurately reflects the content.
Structured data makes this possible. They are semantically enriched so that they provide the model with the information and attributes that can make content generation more accurate. In the case of GPT-3, for example, any data is converted to text to make it more usable, but without the structured data and the information it contains, GPT-3 would confuse even the best prompts. If you use structured data instead, you can achieve better results and outperform the competition, which is very large in this area, considering how many open automated content writing tools are available online.
Building a Knowledge Graph is essential for the effective use of NLG systems such as GPT-3. The Knowledge Graph is the dynamic infrastructure behind a website. It represents a network of entities – i.e., objects, events, situations, or concepts – and illustrates the relationships between them. Structured data is used to describe these entities. This way, your content is more easily understood by search engines and ranks better on Google.
With the Knowledge Graph, you then have the semantically enriched dataset you need to train models and create unique and original AI-generated content that respects brand identity and tone of voice.
AI-generated Content For SEO: A Real-World Case
How We Used NLG For E-Commerce
Here we would like to show you a real world case of how we used AI to create content that had a positive impact on SEO. In this case, we are talking about what we did for a corporation that includes some of the biggest international brands for accessories. So let us talk about AI-generated content for e-commerce.
This experiment proves that customized AI Product Descriptions can bring measurable SEO value to product detail pages (PDP). With AI-generated content, each variant of the same product gets a personalized description, whereas with standard workflow, all variants share the same description.
The experiment began a year and a half ago. In the first step of the workflow, we collected all the data we needed to better train and enrich the model. Thus:
Product feeds to describe.
Actual product descriptions or examples of product descriptions with the brand’s ToV;
Other content with the brand’s tone of voice (e.g., social feeds).
Brand kits and other materials related to the brand.
Then we selected the attributes. These must be available in the dataset provided and relevant to the product. The list of selected attributes was used to create the prompt.
To customize the model, fine-tuning is the way to go. We use the provided examples with product descriptions. This way, the content generated by the AI matches the products, brands, and tone of voice of the client. Once the prompt is ready, we can start creating the product description. The completion is renewed until we reach our goal that the product description is correct and validated in terms of number of characters (between 190 and 350). We will check the output with a native English speaker who will correct the generated text.
The validation process is an important step in automating the verification of the attributes described in the compilations. This way we can check the product description to see if all attributes are correct or missing. Once the compilation is validated, we share the output with the internal teams involved in the project, who approve and possibly integrate the descriptions before they go online.
An important step was to involve the internal editorial team from the beginning. Our goal is to improve their work, but they are the ones who have the rudder and need to be able to steer the boat in the right direction with the necessary adjustments.
After some testing:
We determined that we could have a consistent model across the group of sites, with TOV customized for each brand.
We have improved the level of validation and are becoming more flexible in handling the content rules we receive from the editorial and SEO teams.
Two key components are improving the quality of the data used to train the model and interacting with the content team.
As for validation, experiments with StableDiffusion and DALL-E 2 can help validate the overall quality of the final description.
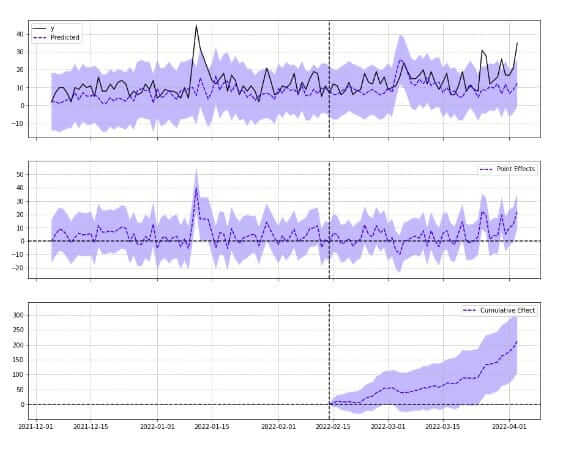
With the first test conducted on one of the group’s websites, we achieved a 43.73% increase in clicks. By looking at the increase in the sales, the team estimated a potential double digit growth of the annual revenues.
Another test was performed on another site with a variant group compared to a control group. In this context, we saw a +6.19% increase in clicks. In this experiment, AI content was added to canonical URLs (which already contained a description).
How To Use NLG To Create SEO-Friendly Content
NLG applications use structured data and turn it into written narratives, writing like a human but at the speed of thousands of pages per second. NLG makes data universally understandable and aims to automate the writing of data-driven narratives, such as product descriptions for e-commerce.
Content Creation
Content creation is something that almost all e-commerce store and blog owners need to constantly invest in to produce fresh, high-quality content. Content can take many forms, including blog articles, product descriptions, knowledge bases, landing pages, and many other formats. Creating good content requires planning and a lot of effort.With the help of AI and natural language generation models, it is possible to produce good content while dramatically reducing the time it takes to create it.Remember that human monitoring, refinement, and validation remain critical to delivering excellent AI-generated content with current technology.
Generate E-Commerce Product Descriptions
You can use GPT-3 to generate product descriptions for e-commerce. Based on data provided to it during training, GPT-3 can predict which words are most likely to be used after an initial prompt and produce good human-like sentences and paragraphs. However, this is not an out of the box solution. To adapt GPT-3 to your specific needs and produce good product descriptions for your online store, you will need to go the fine-tuning route.
Make your e-commerce 404 pages “smart”
You can create a recommendation engine for your e-commerce that suggests products on the 404 error page. You can design the layout of the page using DALL-E 2 and create the error message using GPT-3. This way, your ecommerce 404 pages, which are among the most visited pages on your website, will help provide a relevant and optimal user experience.
Conversational AI has been part of the enterprise landscape since 2016, but it has entered the scene in pandemic times. It has supported customer service and provided content suggestions to help businesses and people through difficult times.
In this scenario, it has become increasingly necessary for enterprises to invest in developing conversational AI to cope with changing user behavior. Conversational AI is therefore among the top 5 categories in AI software spending and its evolution from simple rule-based bots to intuitive chatbots that can accurately mimic human responses by providing assistance to customers and company employees.
So the evolution of user behavior has also led to a change in how search engines work. Google search is increasingly becoming a dialog. The advancement of conversational search inevitably affects SEO. In this article, I’ll show you how you can build a Conversational AI by using SEO to provide users with an optimal experience that increases the number of visits and the time users spend on your site.
The Future Of Search
Search could be reimagined as a two-way conversation with question answering systems synthesizing and answering users’ questions much as a human expert.
Metzler, Donald, et al. “Rethinking search: making domain experts out of dilettantes.” ACM SIGIR Forum. Vol. 55. No. 1. New York, NY, USA: ACM, 2021.
Today, when you do a Google search, you get results appearing in different Google rankings and features: SERP, top stories, People Also Ask, Google Knowledge Panel, etc.
Thanks to conversational AI, search will take the form of a dialog between the user and the search engine, which is not only able to answer a query, but also to anticipate the user’s wishes.
If you own a website or are an SEO, then you need to be able to fit into this workflow. In “traditional” search, SEO was required to:
Rank at the top of Google’s search results for target queries, e.g., “GPT-3”.
Earn a knowledge panel in Google’s Knowledge Graph for your business, people, products, etc.
Rank relevant video content on the first page for target queries.
Answer specific questions to be featured in the People also ask (PAA) section.
With conversational AI, the plan of action changes, and to make this happen, it is necessary:
Win the SERP competition for target keywords.
Provide a great user experience on your website.
Make it easy for users to find the right content (UI, navigation, search functionality, chatbot, ..).
Optimize for user retention whenever the information is available on your website.
For this to be possible and for you to get into conversational search, you can use your content. By storing your data in the Knowledge Graph, you can make your content accessible and reusable for developing a conversational channel such as a chatbot.
Building a conversational AI channel on your website is crucial in taking advantage of the opportunities and benefits of interacting with your customers. This will allow you to leap ahead and gain a significant competitive advantage over your competitors.
But let’s go through the concrete steps that will help you build a successful conversational AI starting from SEO.
Conversational AI and SEO: Concrete Steps
In this scenario, SEO plays a crucial role. How can you build a successful conversational AI ? To do so, you need to follow the steps below.
Build your Knowledge Graph. In this way, you can leverage the power of entities and the relationships between them to provide Google with all the information it needs to understand your site content and to provide users with results relevant to their search queries.
Earn a Knowledge Panel. Through it, Google provides quick and reliable information about people and brands. Getting a Knowledge Panel on Google depends on the data. The more accurate and consistent they are, the more accessible Google will put the information together and return a perfect Knowledge Panel.
Use the VideoObject.Adding Schema Markup’s VideoObject feature, you can use video as a magnet to attract traffic to your content by building irresistible, clickable snippets.
Having a bot and having the KG + FAQ you can deliver a better user experience to the users on the website itself (and eliminate the requirement to go back to Google to search for another info).
A Real Use Case: From Google Search To WordLift’s AI-Powered Chatbot
WordLift is replicating what Google is doing (at the scale of a single website).
Leverages the same data published on the website
Creates a chatbot on top of transformer-based models
In terms of information retrieval, a chatbot works like a search engine. So what I do for Google will improve my chatbot (and my internal search). The same content we prepare for Google can also be used to train an artificial intelligence for conversations like a chatbot. And that’s exactly what we did to develop the chatbot for our documentation.
We trained our chatbot using Jina AI DocsQA’s q-a service and we extended its knowledge by adding to the indexing flow also FAQs (question and answer pairs) from our knowledge graph. Structured data content (such as FAQPage markup) is available using WordLift GraphQL end-point.
In this example, you can see how to take ownership of the user journey with WordLift.
Case 1: Google directly provides the answer to the question/search query. It’s the top page result.
Case 2: Google returns the passage that talks about GPT-3 in the article about generation product descriptions.
Case 3: Google displays the questions/answers that are added as FAQ schema markups to the article.
Developing a chatbot like WordLift’s that can replicate Google’s responses has many benefits:
Improve the user experience by providing answers to their questions
Avoid losing a user we worked hard for by keeping them on the site once we have an answer.
From an analytical point of view, increase the number of users visiting the website and increase the time spent on the website (if this happens, it means that we serve users better).
Takeaways
Rethinking Search. Search can be reimagined as a conversation.
Two visions. Know-it-all AI vs. relevant and accurate information.
No additional effort. Same content that is created to support Google ranking and visibility can be used to train an AI to converse like a chatbot.
Multibot orchestration. Stack of bots, master bot and bot grouping.
Personalization. Era of hyper personalization for users and for businesses.
Multimodality. Enable text, image, videos, etc. in a single query.
To know more about how Conversational AI meets SEO, watch the video👇
Looker Studio is a great, free data visualization tool from Google that lets you collect data in informative dashboards and reports that are easy to read, easy to share, and fully customizable. The data comes from various sources such as proprietary databases, Google Analytics, Google Search Console and social media platforms, and you can blend them without programming.
How To Create Semantic SEO Reports with WordLift
The Semantic Web has changed the way we approach web content. As we know, Google is changing the way it crawls web pages, focusing not just on keywords (which are still important) but on concepts and then entities.
Adding structured data to your website means that you are enriching your data with information that allows Google and the search engines to better understand what the content of your website is about. This way you can get better rankings, more organic traffic and provide users with a more relevant user’s experience.
So, with structured data, you can make a difference for your business. However, it is often very difficult to show the SEO structured data value and thus a semantic SEO strategy.
If you have WordLift, we have the solution for you! You can use the Looker Studio Connector to understand and show others the results you have achieved by working with entities on your website. Let’s go and see how it can help you implement your semantic SEO strategy.
Getting Started With WordLift for Google Looker Studio
With WordLift Looker Studio Connector, you can create Semantic SEO reports by loading data from your Knowledge Graph right into Looker Studio and blend it with Search Console or any other web analytics platform.
Just click on it and enter the WordLift key. And we have a GraphQL query ready for you, so you don’t need to do anything to get started. In case you are a power user and you know the query that you want to run, just continue. For example, if you are running an e-commerce website, maybe you want to query for product attributes or prices. Then be sure to keep checking the box “use report template for new report”, so you can get a shiny new report premade for you. Then click Connect. Here you can see the fields that come from the report. Finally, click Create Report!
At this point, you are close to creating your report, but two more steps are needed:
To go to the managed data sources and add your Search Console data source: choose your website, choose URL Impressions anche choose Web Type, and then click on Create.
Check the blends to verify that the data is merged from the Knowledge Graph and GSC.
Save and enjoy the report🤩 You can filter the data for EntityType and choose the period of time you prefer.
Benefits
If you use WordLift Looker Studio Connector for your semantic SEO strategy, you can have these benefits:
Everything in one place. You can create a single source of truth about your SEO and business performance.
Learn more about your audience. You get meaningful data about your content that helps you learn more about your customers and optimize your SEO strategy.
Useful data. You’ll be able to identify new queries and search intent to optimize your content.
Improve SEO reporting and gain new insights. Take your SEO reporting to the next level and easily gain valuable insights into your keyword rankings, traffic, and more.
Now you can focus on semantic web analytics and the advantage that you can gain in modern SEO without worrying about how to prove the benefits.
Discover more about how to create a Web Analytics Dashboard using Google Looker Studio, traffic data from Google Analytics, and WordLift, reading this article.
Learn how to create a Semantic SEO Report in 3 simple steps👇
Other Frequent Questions
Are Looker Studio connectors free?
As Google says, “You can build, deploy and distribute connectors for free. You and your users can use connectors in Data Studio for free.” In the case of WordLift’s Looker Studio connector, you can use it if you have an active subscription, because you need a key to create the reports.
Conversational AI is the set of technologies, such as virtual assistants or chatbots, that can “talk” to humans (e.g., answer questions).
Conversational AI tools use machine learning, automatic responses, and natural language processing. Their goal is to recognize and replicate speech and communication and create an experience of human interaction.
AI technology can accelerate and simplify relationships with consumers by answering their questions and relaying their requests. It can be used on websites, online stores, and social media channels, and is often used in customer service.
Components Of Conversational AI
Conversational AI systems have 4 elements that contribute to their development and operation.
Machine Learning
Machine learning consists of algorithms, functions, and data sets that systematically improve over time. Artificial Intelligence recognizes patterns with increasing input and can respond to queries with greater accuracy.
Natural Language Processing
Conversational AI uses NLP to analyze speech through machine learning. Named entity extraction (NER) is widely used to detect intents (what the user has in mind when interacting with a chatbot).
Data
The success of conversational AI depends on training data from similar conversations and contextual information about each user. Semantic rich data, in particular, can make a real difference when training an AI system as it provides contextual information.
Conversation design
Companies need to develop the content that AI will share during a conversation. Using the best data from the AI application, developers can select responses that fit the AI’s parameters. Human authors or natural language generation techniques can then fill in the gaps.
Benefits Of Conversational AI in SEO
Here are some key benefits of conversational AI.
Create a personalized user experience
The use of conversational AI makes it possible to provide users with a personalized experience that meets their needs. Whether it’s making an inquiry, completing a purchase, or providing customer service, you can ensure users get the answers they need in real time without having to engage your team.
Users who find the answers they are looking for are less likely to leave your site. This way, the time spent on the website increases and the overall performance of it benefits from the positive impact of using Conversational AI.
We have developed a chatbot that is active in our documentation, and we show you the average time spent year-over-year on the most popular pages.
Avg. Time spent year-over-year on the most popular pages.
This data is for the last 7 days, but it already shows the immense positive impact conversational AI has on our website.
Collect valuable data
Conversational AI, like an internal search engine, allows you to understand user personas. The resulting data can be used to drive your business forward and give you an edge over your competitors.
Get more conversions and new up-sell opportunities
Providing appropriate and timely information and updates to customers through conversational AI increases conversion rates. Virtual assistants help customers navigate and find the right product or service for their needs.
Conversational AI can also provide consistent and compelling up-sell opportunities that take into account consumer preferences, time, and other data to make the best possible offer.
SEO and Conversational AI: a real-world use-case
As we know, structured data allows the content of a website to be indexed more easily by Google and other search engines. The content is understandable for the machine. It has all the information it needs to understand what we are talking about and can use it to answer search queries. As a result, the results in the SERPs are more consistent, and users get more complete and relevant answers to their needs. In this way, our website gets more organic traffic and provides a better user experience that increases conversion rates.
A chatbot works like a search engine. So what I do for Google will improve my chatbot (and my internal search). The same content we prepare for Google can also be used to train an artificial intelligence for conversations like a chatbot. And that’s exactly what we did to develop the chatbot for our documentation.
We trained our chatbot using Jina AI DocsQA’s q-a service and we extended its knowledge by adding to the indexing flow also FAQs (question and answer pairs) from our knowledge graph. Structured data content (such as FAQPage markup) is available using WordLift GraphQL end-point.
Not only that, we have included the link to our blog where the user can find the answer and read the full content. In this way, traffic is directed from the documentation to the blog, increasing the number of visits and making the user experience more relevant.
Similarly, we are indexing (or trying to index) the FAQ content we have on the blog, and we plan to extend the same conversational AI to other parts of our site.
Developing this type of chatbot using structured data and Knowledge Graph, we expect to achieve:
increase time spent on the page on docs
increase number of interactions with the chatbot (not yet available)
more visits from the doc to the blog.
We will soon share our reporting!
How To Train Conversational AI
There is more that can be done with a knowledge graph in the context of chatbots. Here is our latest research paper Question Answering Over Knowledge Graphs: A Case Study in Tourism on how to use the data in a knowledge graph to automatically generate questions and answers, which in turn are used to train the chatbot. To evaluate the proposed approach, the SalzburgerLand Knowledge Graph is used, which is real and describes tourism entities in the Salzburg region in Austria. The research results show that the proposed approach improves the end-to-end user experience in terms of interactive question answering and performance.
Visual content is one of the most direct ways to improve your organic presence. Image SEO and visual search optimization are the 2 aspects you need to keep in mind.
In this article, I will instead focus on how you can optimize visual search to appear in Google Lens to get more organic traffic and more visibility for your products.
What Is Google Lens?
Google Lens offers one of the earliest platforms for visual search – trained on millions of images. In addition to recognizing objects, it is also capable of translating and transmitting text found on images.
As mobile devices have become more prevalent in everyday life, voice assistants have taken on an increasingly central role in search. The same is true for image search, as we all have a camera with us at all times. Google Lens goes one step further and allows users to search for a product they are interested in within seconds, using images and text at the same time.
Imagine a person sees a friend wearing a dress and she likes it. Google MUM (Google Multitask Unified Model) is the giant transformer AI-based model trained with images and text that led to the introduction of multimodal search or Multisearch as Google itself has defined it.
This means that users can combine information in different formats (photos, voice search, text, etc.) to find the product they are looking for. A real revolution for the search experience of users on Google, who until recently could only use text queries.
In detail, Google Lens scans the image and compares it to its huge photo index and searches for that exact dress and several similar alternatives. And you can also search for the same dress but in a different color!
This shows that it is essential for e-commerce to have products with SEO-optimized images that meet the requirements and have the necessary features to make them optimal for this search mode.
How To Activate Google Lens?
For Pixel users it is already active in the camera.
Android users can access Google Lens via Google Assistant or use the standalone Google Lens app.
For iPhone users, Google Lens can be activated via Google Photos or the Google app.
How Does Google Lens Affect SEO?
John Mueller answered answered this question in one of his Google SEO office-hours sessions:
From an SEO point of view, there’s nothing you can do manually, but if your images are indexed, we can find your images and highlight them when someone uses that type of search. So there’s no direct impact on SEO, but if you do everything right, if your content can be found in search, if your content contains images, and if those images are relevant, then we can drive visitors to those images and your content in different ways.
How To Optimize Your Images For Google Lens
Google Lens takes SEO for images to a new level thanks to Artificial Intelligence. And it’s worth seeing what we can do to optimize SEO on this basis.
The alt tags attached to a photo must contain the most important keywords, brand keywords and other information that is important in any type of SEO search. Do not forget to take care of the page titles and meta descriptions as well, which are equally important for search engine optimization.
2. Include EXIF and IPTC Photo Metadata
The EXIF (Exchangeable Image File Format) is a specification that defines data about images, sounds, and tags used in digital still cameras. The date with your EXIF data should be optimized for Google Lens to make the most of the information. This will help your image and content rank better.
The IPTC Photo Metadata Standard is the most widely accepted and used standard for describing photographs. It structures and defines metadata properties that allow users to add accurate and reliable data about images.
In 2018, Google Images introduced some new features to its image search results. Next to a selected photo, the creator of the image, the credit line, and a copyright noticeare immediately displayed. This works by reading the corresponding IPTC photo metadata fields embedded in the image file.
On August 31, 2020, this feature was enhanced to also display a licensable badge above an image and a link to the licensing information.
The EXIF (Exchangeable Image File Format) is a specification that defines data about images, sounds, and tags used in digital still cameras. The date with your EXIF data should be optimized for Google Lens to make the most of the information. This will help your image and content rank better.
The IPTC Photo Metadata Standard is the most widely accepted and used standard for describing photographs. It structures and defines metadata properties that allow users to add accurate and reliable data about images.
In 2018, Google Images introduced some new features to its image search results. Next to a selected photo, the creator of the image, the credit line, and a copyright noticeare immediately displayed. This works by reading the corresponding IPTC photo metadata fields embedded in the image file.
On August 31, 2020, this feature was enhanced to also display a licensable badge above an image and a link to the licensing information.
Structured data: structured data is an association between the image and the page on which it appears with the markup. You must add structured data for each use of an image, even if it is the same image.
IPTC photo metadata: IPTC photo metadata is embedded in the image itself, and the image and metadata can be moved from page to page without being corrupted. You need to embed IPTC photo metadata only once per image.
3. Add Structured Data
Add structured data markup that helps Google and search engines understand your content and images. For example, a recipe page would include in the structured data the name of the recipe, the author, the preparation time, and the publication date. It would also include a brief description of the text and images.
Similarly, when the image represents a well-known entity (such as a person or a landmark), you can use the schema:about property to link the photo and the concept in Google’s Knowledge Graph. To learn more about improving the markup of your images, ImageSnippets is a great starting point.
ImageSnippets is an image-based, data-centric platform that links machine-readable descriptions to images using state-of-the-art Semantic Web and Linked Data technology and standards. You can see, using the tool, how images are translated into triples (subject > predicate > object) and immediately become machine-readable. Interestingly, the tool also uses AI to extract features, translating them into additional markup.
4. Have High Quality And High Resolution Images
Make sure you use SEO optimized images for your content. They should be of high quality, have a high resolution and be in the various formats required from Google best practices.
Try our free AI-powered Image Upscaler to enlarge and enhance images from the website to improve structured data markup using a state-of-the-art deep learning model. Moreover, when dealing with Google Lens, it is essential to provide multiple angles of the same object and prepare the different versions for the same image (1:1, 4:3, and 16:9).
An Example Of Content Optimized For Google Lens
If you want to optimize your content for Google Lens, you can train Google to recognize them by providing semantic meanings behind media assets using structured data. You can also increase the quantity and quality of imagery to help Google learn about our products. Last but not least, remember to make always visible and accessible to Google the licensing metadata of the image. Adding licensing information allows web searchers to use the drop-down menu in Google Images for filtering images based on their license.Here below is one of the experiments we did, along with the team of Ippen Digital, where we succeeded in bringing one of their sites to the top for a visual query depicting the wall mural in front of their office.
If you searched for the mural using Google Lens in October, you saw that it did not show up in the results, meaning it was not at the top of the rankings and none of the top results came from their properties. It was also interesting that Alamy was among the top results. Alamy is an excellent site that collects images and does a great job of promoting search engine optimization of their images.
How could we help this publisher to optimize this content fo Google Lens?
To achieve this, we worked on three aspects.
Enrich the structured data behind these images. This allowed us to gain Google’s confidence that, on the one hand, the images are rights-free and therefore can be used, and, on the other hand, that the images really represent this entity in this particular geographic area. So we added as much information as possible using structured data markup.
Provide the images in different formats and from different perspectives. Because, as you can understand, if I need to train a model that is able to recognize an image, the model will benefit from high quality images, but also from multiple perspectives of the same object.
Adding licensing metadata making the images free and accessible for everyone.
After a few months, we were able to outrank Alamy.
In his talk at Knowledge Graph Conference 2022, Andrea Volpini talked about visual semantic SEO. In particular, he showed how you could use the knowledge graph of a website to train an AI-image generator that uses CLIP and a diffusion model and how a similar approach might be in use behind Google’s recent multisearch functionality.
Most Frequently Asked Questions
What is Visual Search?
Visual search is an AI-assisted search via your camera instead of text. Imagine you are searching for a new pair of sneakers. You could go to Google and type in “sneakers.” You can refine the search if you know the brand. Or you could open Google Lens, snap or upload a picture of sneakers you like, and search with that. That’s a visual search.
Using machine learning and artificial intelligence, Google can pretty much “read” the content of your camera lens and search for it, showing you the results that are closest to what you’re interested in. Appearing in this type of search is a sure way to increase your market share and organic traffic.
Is Google Lens Free?
Yes, it is. You can download it on both iOS and Android devices in their respective app stores.
What is Pinterest Lens?
Pinterest Lens is one of the most important platforms where mainly e-commerce companies are present. It allows searchers to quickly get inspired, but also to directly buy a product that interests them.
Pinterest can accurately identify 2.5+ billion objects.
80% of Pinterest users start their shopping journeys with visual search
The platform has 454 million MAU (Monthly Active Users) globally
It’s well represented in most countries, especially in the West.






















Recent Comments