Adding structured data to your website means enriching your data with information that makes your content easier for Google and search engines to understand. This way, your website and the search engines can talk to each other, allowing you to have a richer representation of your content in Google’s SERPs and increase organic traffic. You’ll then get more clicks and growth for your business.
With structured data in modern SEO, you can create an impact, and this impact is measurable whether you have a large or small business.
Focus on the importance of structured data beyond numbers (clicks, impressions, etc) and the advantage that you can gain in modern SEO.
Much of the adoption we see of modern standards like schema.org (particularly via json-ld) appears to be motivated by organizations and individuals who wish to take advantage of search engines’ support (and rewards) for providing data about their pages and content but outside of this, there’s a rich landscape of people who use structured data to enrich their pages for other reasons. Web Almanac
So structured data is not just the data we prepare for Google; it’s data that helps you understand the meaning of web pages.
The Semantic Web has changed the way we approach web content. As Tim Berners Lee himself says, the world is not made of words but is made of something more powerful: data. This means that to improve search engines’ understanding of web content, it is necessary to have a high-quality dataset enriched with information in structured data.
Structured data allows Google and search engines to understand what you’re talking about on your website and rank better by returning users with enriched results in SERPs. In this way, users can find relevant information that better meets their search intent.
We talk about entities and no longer about keywords. They represent “concepts” and allow machines (Google and search engines, voice assistants, etc.) to interpret what we know about a person, organization, place, or anything described in a document.
In this scenario, Semantic Web Analytics is the use of named entities and linked vocabularies such as schema.org to analyze the traffic of a website.
With this type of analysis, you’ll start from your website’s structured data, and you’ll be able to cross-reference it with the data from Google Analytics, Google Search Console or your CRM. In this way, you’ll be able to learn more about your users/customers and their behaviors, gaining a strategic advantage over impression and traffic data alone. As we’ll see below, with just a few clicks, you can extract structured data from web pages and blend it, in Google Data Studio, with traffic from Google Analytics.
How To Use Structured Data For Semantic Analytics
It’s clear that structuring information goes beyond search engine support and can also provide value in web metrics analysis.
At this point, we show you how you can extract structured data from web pages and blend it with Google Analytics traffic in Google Data Studio. You’ll also see how this will allow you to gain insights into web analytics.
We start from a demo website that we built for demonstration purposes. If you have a small business, with a small number of products, you can crawl your content by using a Streamlit application. Otherwise, if you are at a more advanced level and you have a large number of products, you can use Colab, working with the SEO crawler of Advertools, the free library created by Elias Dabbas, available here. With this system, you can crawl hundreds of thousands of URLs. But it has a pitfall: it is not able to detect structured data that has been injected with javascript.
Then the data will be brought by the crawler in Google Sheets and blended in Google Data Studio in order to have one single view.
You can create a Data Studio Dashboard where you can select and see some specific insights. Here, for example, you can see the breakdown of the session in Google Analytics with the category. So we can see that clothing is accounting for 50% for the session.
How Do Blended Sources In Google Data Studio Work? Blending Data Is Simple.
As you can see in the image, you have tables (in our case, Google Sheets and Google Analytics) and a list of available fields that you can use from this table within the join to create a view of combined fields.
Then you have the join configuration; that is how you want to blend this data. You can decide to take everything from the left table that overlaps with the right table, or you want to look at the strict overlap of the inner.
Then you have the name of the blended source that you will create and the fields that you will represent inside this blended source which is a view on one, two or more tables combined by a unique key. In this example, the unique key is the URL.
You are using the URL on both sides to combine them and these allow you to look at the analytic, for instance the session, by looking at the category.
If you want to see something more advanced, you can blend the second Spreadsheet with Google Analytics. In this case, you have more data, such as the color and the brand name, and you can create a chart using the product category, the session, and the price. This way, you can see traffic for each product category and the price. You can also see the breakdown of the colors and the brands.
You can play with different combinations in order to have the right data. Extracting structured data from your web pages and blending it with Google Analytics data gives you a more precise and more accurate picture of your users’ behavior with just a few clicks. This is particularly useful to improve your marketing strategy and grow your business in a data-driven way.
Keep In Mind: Structured Data Has Its Pitfalls.
Structured data, when injected using Javascript, cannot be easily crawled;
If you want to know how to create a Web Analytics Dashboard using Google Data Studio, traffic data from Google Analytics, and WordLift, read this article.
Frequently Asked Questions
What is Semantic Web Analysis?
Semantic Web Analytics is the analysis of a website’s traffic done using named entities and related vocabularies such as schema.org.
With this analysis, you can start from the website’s structured data and cross-reference it with data from Google Analytics, Google Search Console, or other CRM. In this way, you can learn more about user and customer behavior and gain a competitive advantage beyond just analyzing impressions and traffic.
McKinsey Global Survey on artificial intelligence (AI) suggests that organizations are using AI as a tool to generate value. Increasingly, that value is coming in the form of revenue. As this data shows, AI for advertising allows you to increase your return on ad spend (revenue) and reduce the amount of money you spend on staff time and ineffective ad budgets.Suppose we take Google Ads as an example. Before using AI and then the automation that comes with it, you needed to invest a lot of time and effort in finding keywords, devices, targeting, messaging, and bidding to get more leads, sales, and subscriptions. Work that was being done manually by humans. Today, all this is outdated. With AI-based solutions, you can improve the efficiency of various aspects that affect paid campaigns, not only on Google Ads but on the various platforms available.
Budget optimization and targeting
Performance optimization is one of the prominent use cases of artificial intelligence in advertising. Machine learning algorithms can be used to analyze ad spreadsheets and get tips on optimizing them, either by automating previously manual actions or highlighting issues you didn’t know you had.
In more advanced cases, AI can automatically manage ad performance and spend optimization, allocating budgets across channels and audiences and letting humans focus on more strategic tasks.
Similarly, you can use AI to analyze audiences used in previous campaigns and optimize them based on past performance data. In this way, you can also identify new audiences interested in the business.
Ad creation and management
There are systems based on artificial intelligence that can create partially or completely ads for you based on your goals. This feature is already present in some social media advertising platforms, which use intelligent automation to suggest ads that you should run based on the links you are promoting.
But it also exists in some third-party tools, which use intelligent algorithms to write the ad copy for you. These systems leverage natural language processing (NLP) and natural language generation (NLG) to create texts that perform well or better than the human-written copy.
How Structured Data Can Make A Difference In PPC
Structured data is crucial for organic search but equally decisive for paid campaigns.
Structured data enrich your content with the information necessary to make Google and search engines understand what you are talking about. It makes your data more accurate and more appealing. This means that when you add structured data to your website, you enrich your dataset and, by using your first-party data, you push input into ad systems that are read correctly because they contain all the required attributes and allow you to get better performance from your paid campaigns.
We asked Frederick Vallaeys, CEO at Optmyzr, a few questions on this topic. Frederick was one of the first 500 employees at Google, where he spent ten years building AdWords and teaching advertisers how to get the most out of it as Google’s AdWords Evangelist.
Specifically, I asked Fred, how you can use structured data to optimize feeds and ad components to have better results.
“As Google Ads become more automated, the ways we optimize PPC are changing and structured data plays a big role in that. Rather than managing details inside the ads system, we have to shift towards managing the inputs into the ads system so that the automations can handle the details correctly.
Think of ads for example. Advertisers used to write separate ads for every ad group but now with Responsive Search Ads (RSA), they can re-use the most powerful ad components across many ad groups while changing just a small subset of ad assets for each. In effect, ad text has become a form of structured data and in our analysis it can drive significant incremental conversions.
One of our clients wanted to deliver automotive leads to their dealership clients at a lower cost. They had the structured data on the website. Through this and Optmyzr’s Campaign Automator, they were able to decrease cost per acquisition (-25%) and increase ROAS. In addition, they could save over 50 hours per month by keeping prices, colors, and trim levels up to date for their automotive customers.
There are many other ways in which structured data impacts search advertising, from Dynamic Search Ads (DSA), to shopping ads driven by merchant feeds, local ads driven by business feeds, dynamic ads driven by ad customizers, etc.
Knowing how to feed better structured data into the automations will be critical for continued PPC success”.
When we think of bots, we either think of Star-Wars-like robots or humanoid androids communicating with us.
What are chatbots? Chatbots are computer programs built to communicate with humans using natural language. Usually, they handle customer service tasks, such as answering questions and booking appointments.
The primary purpose of chatbot systems is to retrieve valuable and relevant information from one or multiple knowledge bases by using natural language understanding (NLU) and semantic web technologies.
The problem
The web is packed with the most disparate information; it’s often hard for humans to classify and judge the quality of a source at first sight, so, in order to save time, which is our most valuable asset, we turn to machines to do the searching for us.
Technically speaking
Many chatbot systems are designed to require a lot of training data, which is unavailable and expensive to create. Recently, with the growth development of linked data, increasing progress on chatbots has been seen in research and industry. However, they face many challenges, including user query understanding, intent classification, multilingual aspect, multiple knowledge bases, and analytical queries interpretation.
Knowledge graphs are becoming more and more a standard technology for Companies, people, and publishers. A Knowledge-Graph-based bot is scalable, flexible, and dynamic.
Why Knowledge Graphs
A Knowledge Graph is a structure that portrays information as relationships and concepts connected to each other. Google was the first to mention Knowledge Graphs and the technology behind them back in 2012. You can find out more about why you need a Knowledge Graph, read our blog post.
Back to us now!
So we know that a chatbot needs a domain model in order to understand and answer user questions. In machine learning, we would generate a huge knowledge base of sentences and use cases, wasting time and resulting in a static chatbot, which the web is full of already.
Since a domain model collects information about a particular topic or subject, we can use a Knowledge Graph to store and retrieve information easily.
In this way, our chatbot would be dynamic and always up to date without manually adding and editing the knowledge base.
Advantages of Knowledge Graph-Based Chatbots
A chatbot based on a Knowledge Graph knows how to interpret requests from the users delivering meaningful answers straight away. Moreover, there won’t be a need for lengthy training.
Knowledge Graphs can be updated more efficiently simply by adding data and relationships to other entities.
How To Develop A Knowledge-Based Chatbot
First of all, there is the preparatory work for the Knowledge Graph, in which there should be a clear structure of concepts, entities, and relationships between them.
Then, the chatbot needs to “study” those rules, entities, and relations to answer questions.
These are three main flows that describe how to develop a conversational interface based on a Knowledge Graph:
Pushing contents from the Knowledge Graph (KG) to the website/backend (via GraphQL interface) – the data present in the KG are made available through targeted queries.
Semantic content search on questions-answers (via search API) – the FAQ content is made available through targeted queries that can be consulted performing semantic search, which allows you to manage, if present, the intent associated with specific questions.
Natural language understanding and dialogue management (via NLU for intent management) – the KG data and the semantic search functions are operated by an external dialogue manager application that intercepts the user’s intent and retrieves the answers (accessing content either in the KG or from semantic search).
Knowledge Graph and GraphQL
The Knowledge Graph is fed with content flows from the CMS and through the NLP end-point, which analyzes the unstructured contents and organizes them semantically using the Company’s vocabulary containing the key concepts (entities).
The graph may contain different content types: FAQpages, NewsArticles, Articles, Offers… all useful to sustain a conversation flow that includes different nuances on the same topic, as a user might want to know a definition of a term or articles related to this term.
GraphQL is a query language and execution engine designed to implement API-based solutions that access information in the Knowledge Graph.
We use GraphQL as a query service, and its functions are available for data consultation only. Reading takes place through a different end-point.
GraphQL is used when users want to see all articles related to a topic.
Requests towards GraphQL are executed in the Knowledge Graph via authentication.
Semantic Search
This module integrates the API for semantic search to the knowledge base. A first usage scenario is based on the FAQ content present on the site today.
Later, it will be possible to extend the scope of use of this feature to all web content in the KG through the use of models for open-domain question answering (ODQA).
The search for answers (/ ask)
The answers to user questions are extracted through a semantic content search system.
This way, we can enable a classification algorithm that uses a transformer-based neural network to classify questions based on how “significant” they are in relation to the user’s query.
The use case is based on the following application flow:
The dialogue manager (NLU) identifies an intent that can be satisfied by FAQ content
The user’s question is delivered to the Search API
The Search API identifies the closest question-answer
The result is sent to the dialogue manager (NLU)
The dialogue manager via ECSS sends the response to the end-user
Understanding of natural language and dialogue management
We use a scalable architecture: the two main components are natural language understanding (NLU – Natural Language Understanding) and a dialogue management platform.
NLU deals with managing the classification of intentions, the extraction of entities, and the recovery of responses. In the diagram, it is represented as an NLU pipeline because it processes user expressions using an NLU model generated by the trained pipeline.
The dialogue management component determines the following action in a conversation based on context (the Dialogue Policies indicated in the diagram).
Conclusions
Knowledge Graphs are very powerful databases to develop a conversational marketing strategy, and when it comes to building a conversational interface, they stand out from other technologies in terms of:
Speed
Powerful interrelationships between concepts
Flexibility
Possibility to easily update the graph
Embed potentially unlimited knowledge
The goal of any bot is to provide valuable and relevant information to users, adapting to each context and request. And that’s what Knowledge Graphs do: they move and adjust.
In a world of infinite information, be the KG-powered bot!
On-site search is the functionality by which a user can search for a piece of content or product directly on your website by entering a query in the search bar.
This functionality, also known as internal search, can significantly impact your website: it allows users to find what they are looking for and discover new content or products they are interested in but didn’t know about. It also gives you valuable data and insight into what content or products your audience likes and is most interested in, allowing you to tailor the website to the visitor’s specific needs.
Building an optimized on-site search can get you more conversions and foster brand loyalty. If the user doesn’t have a relevant search experience, they may choose to go to your competitors, risking losing customers.
On-site search is critical, not only if you have an e-commerce store. Any website with a collection of content can reap the benefits of relevant, fast, and easy-to-use site search: better click-through rates, more user engagement, and a better understanding of customer needs.
Why Is On-Site Search Important In SEO?
There is a relevant connection between SEO and on-site search. SEO allows you to increase organic traffic to your website. On-site search makes sure that visitors to your website find what they are looking for quickly and easily. SEO focuses on creating quality content that is relevant to your audience. But the more content you have on your site, the harder it is to get it found. That’s why there’s an internal search. It makes it easy for users to find your content, whether they’re looking for information or products, or services.
In addition, analyzing data on searches made by visitors to your site helps you understand which content or products are most popular and if there are any gaps in your content marketing, sales, or product development strategies. Knowing this data allows you to define more effective strategies and actions to optimize your website for both content and user experience.
How Can You Optimize On-Site Search with AI?
The Knowledge Graph is the key to your on-site search optimization. And below I will show you why.
The Knowledge Graph is the dynamic infrastructure behind your content. It allows your website to speak the native language of search engines, allowing Google and others to understand what you do and what you’re talking about. In this way, you build well-contextualized, related content that contains consistent information and addresses the needs of your audience. By providing users with a relevant experience, you get higher rankings on Google and more organic traffic to your website.
Not only that. We’ve seen that Google search is changing, moving from information retrieval to content recommendation, from query to dialogue. So the search engine is not only answering the user’s questions, but it’s also capable of discovering new content related to the user’s interests. Training the Knowledge Graph allows us to go in this direction, showing the user new content related to his search.
If Knowledge Graph makes Google search smart, it can make your on-site search smarter.
Creating a custom Knowledge Graph and then adding structured data allows your website to better communicate with Google and other search engines, making your content understandable to them. The same will happen for your website’s internal search engine. So, when a user enters a query, the results will be more consistent and respond to the user’s search needs. Also, through Knowledge Graph, you will be able to build landing page-like results pages that include FAQs and related content. In this way, the user will have relevant content, and their search experience will be more satisfying.
By answering users’ top search queries and including information relevant to your audience, these pages can be indexed on Google, also increasing organic traffic to your website.
For example, this is the result for the query vakantieparken met subtropisch zwembad (trad. “vacation parks with subtropical swimming pool”). As you see, we have a page with all the solutions offered by the brand and a FAQ block that will help give the user additional answers for what he is looking for.
If we search the same query on Google we will have the same page as a first result in the SERP.
Search engines use entities and their relationships to understand human language. A generic occurrence of the term ‘delivery’ on the website of a logistic company might indicate the more specific concept of ‘last mile delivery’- using structured data the term is lifted as it gets uniquely identified by a Machine-Readable Entity ID that references a similar concept in public graphs like Wikidata or DBpedia (ie last mile in this example). When a term is semantically enriched (or lifted in our jargon) a search engine is also able to leverage its synonyms and neighboring terms. A user making a search for ‘last mile delivery’ or even ‘last mile’ on that website will be able to find that page.
With WordLift, you can build your Knowledge Graph and add structured data to your website content. Together, we can optimize your site search if you already have it or make it in a way that your customers will love.
On-Site Search Best Practices
To have on-site search optimization, you can follow some best practices.
Make the search box user-friendly
Make sure the search bar is visible from any device and long enough to contain the user’s query. Usually, it will be at least 27 characters long. Remember to place search bars on your site’s primary pages, but not on all of them. Putting it on the checkout page or landing pages may be inappropriate and distract the user from other required actions, such as purchasing a product. Insert a clear call-to-action in the search bar and encourage research with phrases like “insert product, code or brand” or “what are you looking for?”, etc.
Analyze your search data
Analyzing data on internal searches on your website allows you to understand what users are interested in, what they’re looking for, and what content, products, or services are most popular. Also, you can see there may be search intents that aren’t covered with existing content, so work needs to be done to create it. (For example, if a user searches for “how to add FAQ markup” on wordlift.io, we know we are missing that content, and it needs to be created).
Improve imperfect inputs
Facilitates on-site search by improving imperfect inputs and making them predictive. Use autocomplete, autocorrect, filters, and facets to assist the search. Users will appreciate it.
Make the results page intuitive, helpful, and inspiring
Semantic search analyzes the context and searches intent behind the query to deliver relevant results to the user. Also, take advantage of “No Results Pages” to make suggestions to the user about other similar content or in line with their search, so they don’t miss out.
Always redirect the user to the right page (when you have already one)
Bypassing the search result page will make the customer journey smoother. If you have a laser target page on “outdoor speakers” and the user is searching for that, make sure to redirect him/her directly there without passing by the results page.
Not all result pages need to be the same, you can curate some of these pages to cover long-tail intents that really matter. You can do this by adding intro text and FAQ content on these pages. Now, these “enriched” result pages will also work well in search (provided that you add them to the sitemap).
A good-looking search box doesn’t mean anything if the results aren’t helpful to the searcher. And that’s where structured data and the Knowledge Graph come in, as we showed you above.
Knowledge validation is an important task in the curation of knowledge graphs. Validation (also known as fact-checking) aims to evaluate whether a statement in a knowledge graph (KG) is semantically correct and corresponds to the so-called “real” world.
In this article, we describe our proposed approach for validating knowledge graphs (KGs).
Knowledge Graphs
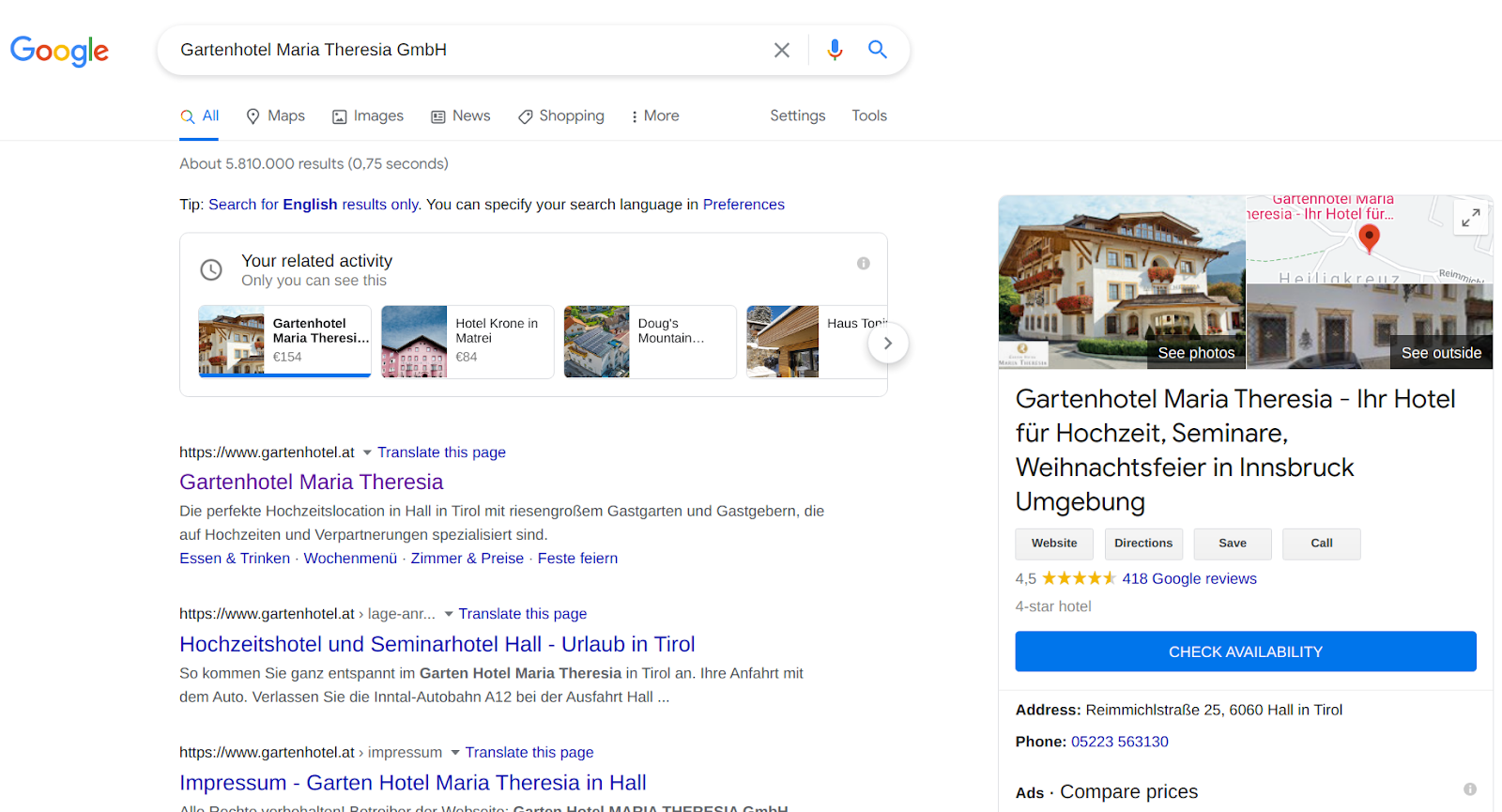
Nowadays, various KGs have been created. For instance, DBpedia and Wikidata KGs have been created semi-automatically and through crowdsourcing respectively. However, those KGs might have errors, duplicates, or missing values. Moreover, KGs are used in search engines and personal assistants applications. For example, Google shows the fact “Gartenhotel Maria Theresxia GmbH’s phone is 05223563130” that might be wrong to advertise because the main switchboard of the hotel can be reached under “0522356313”. See Fig. 1.
Fig. 1: Knowledge Panel of Garten hotel.
Knowledge Sources
Apart from KGs mentioned above, there are various knowledge sources that collect and store content and data of the Web. For instance, Google places is a service offered by Google and it provides data about more than 200 million businesses, places, points of interest, and more. Furthermore, there are other knowledge sources, such as Yandex Places or Open Street Maps (OSM) that provide data about places, restaurants, point of interests, and much more. Those knowledge sources can be used to validate statements of KGs.
Knowledge Validation
To ensure that a KG is of a high quality, one important task is knowledge validation: it measures the degree to which statements are correct. For instance, knowledge validation measures to which degree information about a hotel (e.g. Hotel Alpenhof’s phone number is+4352878550) is correct based on comparing information of the same hotel in a set of knowledge sources. See Fig. 2.
Fig. 2: Validating information about the Hotel Alpenhof.
KG validation carried out by human experts is a time-intensive and non-scaleable task. Therefore, an approach to validate data semi-automatically is needed. There are some approaches that can help with this process, see Fig. 3.
Fig. 3: Overview of validation approaches [Huaman et al., 2020]
Further, we present our approach to validate KGs based on weighted sources.
Approach
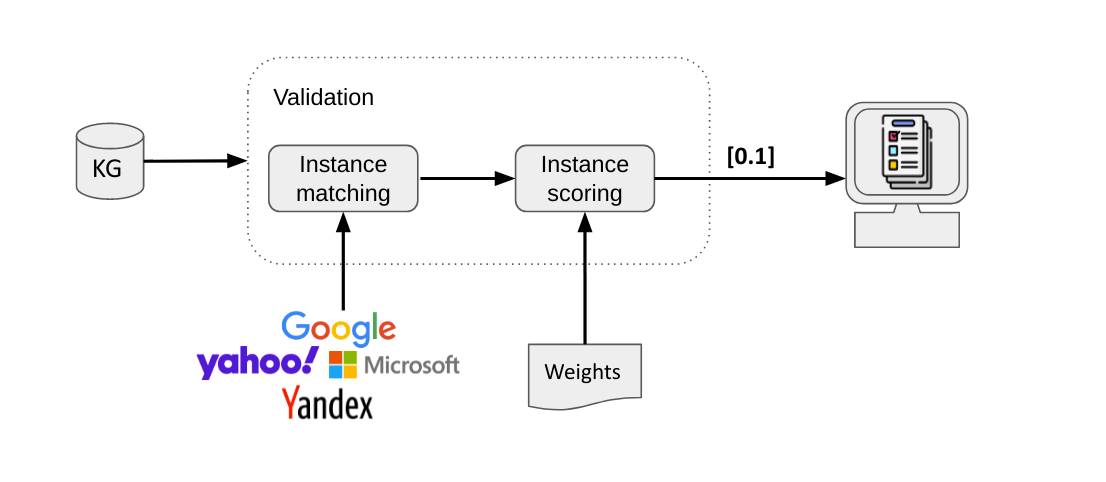
The process overview of the Validator is shown in Fig. 4. At first, users have to set their KG as input to the Validator. Internally, the Validator retrieves data from external knowledge sources (e.g., Google Places, Yandex Places), the Validator performs instance matching to identify which instances (e.g., hotels) refer to the same “real-world” entity, for example, it retrieves Alpenhof hotel from external sources.
Fig. 4: KG Validation process overview.
Later on, the instance scoring process is triggered and the properties (e.g., name, phone number, address) of the same instances are compared with each other. For example, the address of Alpenhof Hotel from the user’s KG is compared with the address value of the Alpenhof Hotel from Google Places, Yandex Places, and so on. Note that each external source is weighted according to its importance: a user can set the weight of (his or her personal) importance for Google Places, Yandex Places, and so on. 0 is the minimum degree of importance and a value of 1 is the maximum degree.
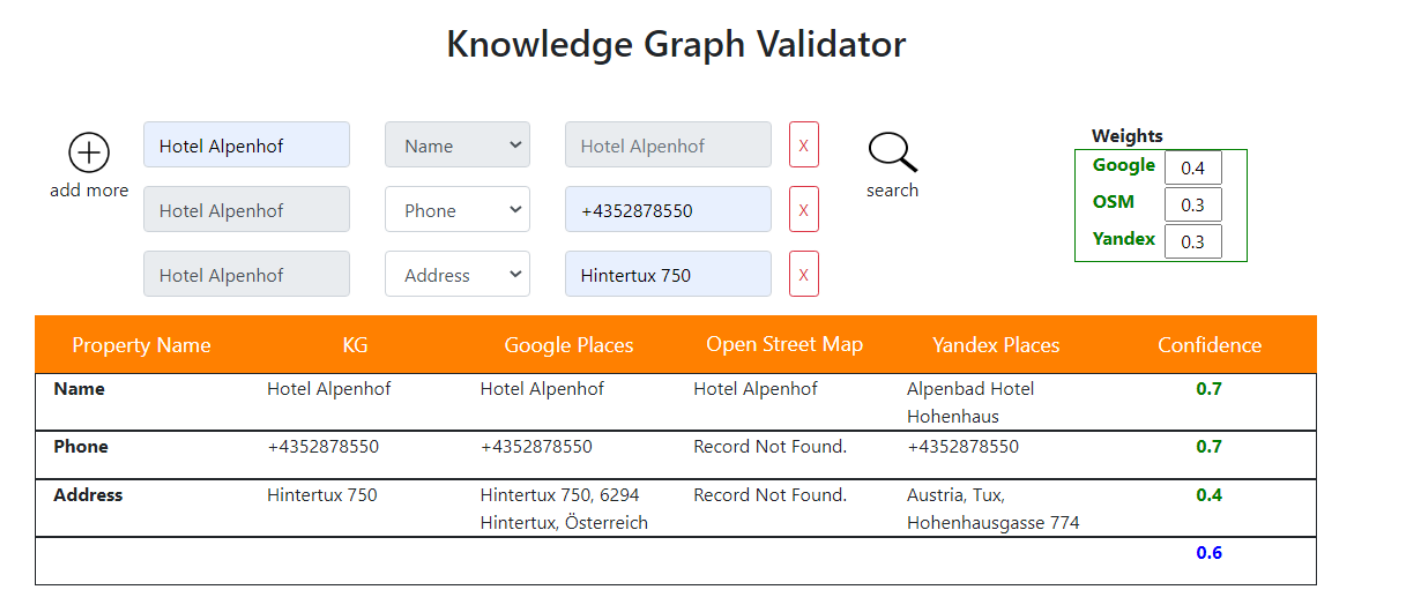
Fig. 5: Screenshot of the Validator [Huaman et al., 2021].
Finally, the computed scores are shown via a graphical user interface (see Fig. 5). It allows users to select multiple properties (e.g. address, name, and/or phone number) to be validated, users can assign/change weights to external sources.
Full details about the approach, implementation, and evaluation are provided at [Huaman et al., 2021].
Where can you use it?
A user can check whether the information for his or her hotel or other business provided by Google Places, Yandex Places, and other sources are correct and up-to-date.
A user could want to validate if the provided information is correct based on different knowledge sources.
The approach might be used to link user’s KG with Google Places, Yandex Places, and so on.
Tools and Technology
The Validator was developed by three students from the University of Innsbruck, in the context of the Eurostars co-funded project WordLift Next Generation.
Summary
Conceptualization of a new KG Validation approach and a first prototypical implementation thereof.
Showcasing use cases where it can be used.
Validating KGs ensures that major search engines show the correct information about your business.
References
[Huaman et al., 2021] Huaman E., Tauqeer A., Fensel A. (2021) Towards Knowledge Graphs Validation Through Weighted Knowledge Sources. In: Villazón-Terrazas B., Ortiz-Rodríguez F., Tiwari S., Goyal A., Jabbar M. (eds) Knowledge Graphs and Semantic Web. KGSWC 2021. Communications in Computer and Information Science, vol 1459. Springer, Cham. https://doi.org/10.1007/978-3-030-91305-2_4
[Huaman et al., 2020] Huaman E., Kärle E, and Fensel D. (2020) Knowledge Graph Validation https://arxiv.org/abs/2005.01389





















Recent Comments