Deep neural networks are powerful tools with many possible applications at the intersection of the vision-language domain. One of the key challenges facing many applications in computer vision and natural language processing is building systems that go beyond a single language and that can handle more than one modality at a time.
These systems, capable of incorporating information from more than one source and across more than one language, are called multimodal multilingual systems. In this work, we provide a review of the capabilities of various artificial intelligence approaches for building a versatile search system. We also present the results of our multimodal multilingual demo search system.
What is a multimodal system?
Multimodal systems jointly leverage the information present in multiple modalities such as textual and visual information. These systems, aka cross-modal systems, learn to associate multimodal features within the scope of a defined task.
More specifically, a multimodal search engine allows the retrieval of relevant documents from a database according to their similarity to a query in more than one feature space. These feature spaces can take various forms such as text, image, audio, or video.
“A search engine is a multimodal system if its underlying mechanisms are able to handle different input modals at the same time.”
Why are multimodal systems important?
The explosive growth in the amount of a wide variety of data makes it possible, and necessary, to design effective cross-modal search engines to radically improve the search experience in the scope of a retrieval system.
One interesting multimodal system is building a search engine that enables users to express their input queries through a multimodal search interface. As the goal is to retrieve images relevant to the multimodal input query, the search engine’s user interface and the system under the hood should be able to handle the textual and the visual modalities in conjunction.
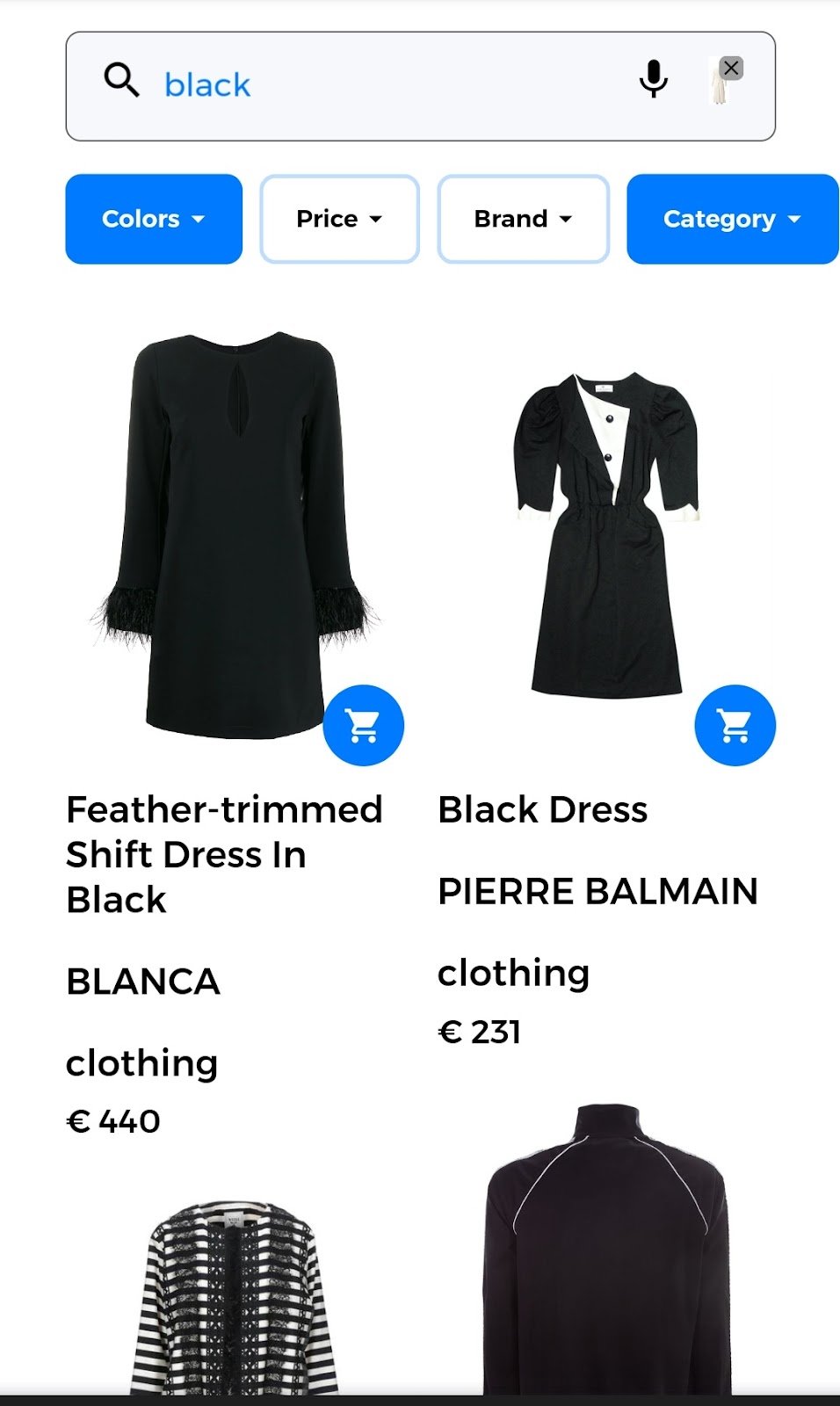
For instance, a search query could take the form of “give me something like this image but I want it to be black”. As shown in the image below, the user provides to the search engine 1) an image of the dress that she’s looking for and 2) a text, or another input form, to indicate the desired color. This way of expression, comparable to how humans communicate, would promote a much better search experience.
When running this search, the input image is a white dress that is shown in the image below. This is the first part of the query which corresponds to the visual part of the multimodal query.
The second part of this query consists of the desired color which is the textual input. In this case, the user is looking for dresses that are “black”. The returned results are images of the dresses that are available at the e-commerce store. The result of the multimodal query is shown in the image below.
Given the richness and diversity within each modality, designing a multimodal system requires efforts to bridge the gap between the various modality, including image, text, video, and audio data. Encoding the textual and the visual modalities into a joint embedding space is one way for bridging the worlds of varying modalities.
While the image is language agnostic, the search terms are language-specific. Monolingual vision-language systems limit the usefulness of these systems in international applications. In general, these monolingual systems are English-only. Let’s now examine cross-lingual approaches in the context of textual and visual retrieval systems.
What is a multilingual system?
Let’s examine one of many key challenges at the intersection of computer vision and natural language processing. We quickly observe the limitation of the current systems to expand beyond a single language.
“A search system is multilingual if the system is able to retrieve relevant documents from the database by matching the document’s captions written in one language with the input text query in another language. Matching techniques range from syntaxical mechanisms to semantic search approaches.”
The task of designing a multilingual system boils down to building language models that support the addition of new languages. Consequently, a large number of additional parameters is required each time a new language is added. In reality, these parameters support the word embeddings that represent the newly added language’s vocabulary.
The primary use case of our multimodal multilingual system is an image-sentence retrieval task where the goal is to return relevant images from the database given a query image and a sentence at the same time. In this vein, we’ll explore the multimodal path and address the challenge of supporting multiple languages.
Towards multimodal and multilingual systems
Learning a good language representation is a fundamental component of addressing a vision-language task. The good news is that visual concepts are interpreted almost in the same way by all humans. One way is to align textual representations to images. Pairing sentences in different languages with visual concepts is a first step to promote the use of cross-lingual vision-language models while improving them.
It has been demonstrated that such approaches can accomplish better performance compared to traditional ones, i.e. text-only trained representations, across many vision-language tasks like visual question answering or image-sentence retrieval. However, many of these promising methods only support a single language which is, in most cases, the English language.
“A multimodal multilingual system is a combination of each of the multimodal and multilingual systems that are described in the previous sections.”
A large number of cross-modal approaches require much effort to pre-train and fine-tune multiple pairs of languages. Many of them have hand-crafted architectures that are dedicated, or at least, perform best at a specific vision-language task. In addition, many of these existing systems are able to handle one modality at a time. For instance, retrieve a relevant sentence from a corpus given an image or retrieve a relevant image from the database given a sentence.
BERT has paved the way for the large adoption of representation learning models based on transformers. BERT follows a two-fold training scheme. The first consists of pre-training a universal backbone to obtain generalizable representations from a large corpus using self-supervised learning. The second one is a fine-tuning task for specific tasks via supervised learning.
Recent efforts, such as MPNet build upon the advantages of BERT by adopting the use of masked language modeling (MLM). In addition, MPNet novel pretraining takes into consideration the dependency among the predicted tokens through permuted language modeling (PLM) – a pre-training method introduced by XLNet.
While these approaches are capable of transferring across different languages beyond English, the transfer quality is language-dependent. To address this computational roadblock, some approaches tried to limit the language-specific features for just a few by using masked cross-language modeling approaches.
Cross-modal masked language modeling (MLM) approaches consist of randomly masking words and then predicting them based on the context. On the one hand, cross-language embeddings can then be used to learn to relate embeddings to images. On the other hand, these approaches are able to align the embeddings of semantically similar words nearby, including words that come from different languages. As a result, this is a big step towards the longstanding objective of a multilingual multimodal system.
Training and fine-tuning a multilingual model is beyond the scope of this work. As BERT and MPNet have inspired de-facto multilingual models, mBERT, and mMPNet, we’re using such available multilingual pre-trained word embeddings to build the flow of a multilingual multimodal demo app.
Demo app: multilingual and multimodal search
The end goal of the search engine is to return documents that satisfy the input query. Traditional information retrieval (IR) approaches are focused on content retrieval which is the most fundamental IR task. This task consists of returning a list of ranked documents as a response to a query. Neural search, powered by deep neural network information retrieval (or neural IR), is an attractive solution for building a multimodal system.
The backbone of this demo app is powered by Jina AI, an open-source neural search ecosystem. To learn more about this neural search solution you get started here. Furthermore, don’t miss checking this first prototype that shows how Jina AI enables semantic search.
To build this search demo, we modeled textual representations using the Transformer architecture from MPNet available fromHugging Face (multilingual-mpnet-base-v2 to be specific). We processed image captions and the textual query input using this encoder. As for the visual part, we used another model made available and called MobileNetV2.
The context
In what follows, we present a series of experiments to validate the results of the multilingual and multimodal demo search engine. Here are the two sets of experiments:
The first set of tests aims to validate that the search engine is multimodal. In other words, the search engine should be able to handle textual and images features simultaneously.
The second set of tests aims to validate that the search engine is multilingual and able to understand textual inputs in multiple languages.
Before detailing these tests, there are a few notes to consider:
The database consists of 540 images related to Austria.
Every image has a caption that is written in English.
Each modality can be assigned a weight that defines the importance of each modality. A user can assign a higher weight to either the textual or the visual query input (the sum of the weights should always be 1). By default, both modalities have an equal weight.
The following table summarizes these experiments.
Test
Setting
Test 1A
Multimodal inputs with equal weights
Test 1B
Multimodal inputs with a higher weight for the image
Test 1C
Multimodal inputs with a higher weight for the text
Test 2A
Multimodal inputs with a textual query in English
Test 2B
Multimodal inputs with a textual query in French
Test 2C
Multimodal inputs with a textual query in German
Test 2D
Multimodal inputs with a textual query in Italian
The results
For the first set of tests (Test 1A, 1B, and 1C), we use the same multimodal query made of an image and a text as shown below. This input query consists of:
An image: a church in Vienna and
The textual input: Monument in Vienna
Test 1A – Multimodal inputs with equal weights
In Test 1A, the weight of the image and the textual input are equal. The returned results show various monuments in Vienna like statues, churches, and museums.
Test 1B – Focus on the image input
Test 1B gives more weight to the image and completely ignores the textual inputs. The intention is to test the impact of the input image without the text. In practice, the search result is composed of various monuments that, most of them, contain buildings (no more statues). For instance, we can see many churches, the auditorium, city views, and houses.
Test 1C – Focus on the textual input
Test 1C is the opposite of Test 1B. All the weight is given to the textual input (the image is blank, it is ignored). The results are aligned with input sentence monuments in Vienna. As shown in the image below, various types of monuments are returned. The results are no longer limited to buildings. We can see statues, museums, and markets in Vienna.
Test 2A – Multilingual queries
As mentioned earlier, the captions associated with the images are all in English. For the sake of this test, we chose the following 4 languages to conduct the multilingual experiments:
English (baseline)
French
German
Italian
We translated the following query to each of these four languages: grapes vineyards. As for the weight, the textual input has a slightly higher weight (0.6) in order to eliminate potential minor noise signals.
For each of the 4 languages, we run a test using the English version of the MPNet transformer (sentence-transformers/paraphrase-mpnet-base-v2) and then its multilingual version (multilingual mpnet). The goal is to validate that a multilingual transformer is able to grasp the meaning of the textual query in different languages.
Test 2A – English + monolingual textual encoding
The query is in English: grapes vineyards and the encoder is monolingual.
Test 2B – English + multilingual textual encoding
The query is in English: grapes vineyards and the encoder is multilingual.
Test 2B – French + monolingual textual encoding
The query is in French: raisins vignobles and the encoder is monolingual.
Test 2B – French + multilingual textual encoding
The query is in French: raisins vignobles and the encoder is multilingual.
Test 2C – German + monolingual textual encoding
The query is in German: Trauben Weinberge and the encoder is monolingual.
Test 2C – German + multilingual textual encoding
The query is in German: Trauben Weinberge and the encoder is multilingual.
Test 2D – Italian + monolingual textual encoding
The query is in Italian: uva vigneti and the encoder is monolingual.
Test 2D – Italian + mono lingual textual encoding
The query is in Italian: uva vigneti and the encoder is multilingual.
Insights and discussions
Comparing the edges cases (Test 1B and Test 1C) with the test where the two modalities have the same weight (Test 1A) show that:
The results of Test 1A take into consideration both the image and the text. The first two images refer to churches and at the same time the result set contains other types of monuments in Vienna.
Test B that focuses on the image returns only images in the category of buildings, ignoring every other type of monument in Vienna.
Test C that focuses on the text returns various types of monuments in Vienna.
As for testing the multilingual capabilities across four languages. We can clearly see that for the English language, the mono and multilingual performance are good and are almost similar. This is expected as both encoders are trained on a corpus language. A small note regarding the monolingual encoder for the French language, the first three results are surprisingly good for this specific query.
As for the three remaining languages, the multilingual encoder returns much more relevant results than the monolingual encoder. This shows that this multimodal multilingual search demo is able to understand queries written in one language and return relevant images with captions written in English.
The future of neural search
Neural search is attracting widespread attention as a way to build multimodal search engines. Deep learning-centric neural search engines have demonstrated multiple advantages as reported in this study. However, the journey of building scalable and cross-domain neural search engines has just begun.
On July 5th and 6th the team at WordLift reached Salzburg to meet the Consortium partners for the WordLift Next Generation project. As you may know, WordLift received a grant from the EU to bring its tools to any website and to perfect anyone’s semantic SEO strategy [link].
WordLift Next Generation is made up of WordLift, Redlink GmbH, SalzburgerLand Tourismus GmbH and the Department of Computer Science of the University of Innsbruck.The aim is to develop a new platform to deliver Agentive SEO technology to any website, despite its CMS, and to concretely extend the possibilities of semantic SEO in a digital strategy. The work started in January 2019 and is being developed in a 3-year timeframe.
The project started with a clear definition of the roles and responsibilities of each partner in the scope to improve WordLift’s backend to enrich RDF/XML graphs with semantic similarity indices, full-text search and conversational UIs. The main goals for the project are: being able to add semantic search capabilities to WordLift, improved content recommendations on users’ websites and the integrations with personal digital assistants.
Here is an example of the initial testing done with Google’s team on a mini-app inside Google Search and the Google Assistant that we developed to experiment with conversational user interfaces.
Artificial Intelligence is leading big companies’ investments, and WordLift NG aims at bringing these technologies to small/mid sized business owners worldwide.
In order to accomplish these ambitions goals the consortium is working on various fronts:
Development of new functionalities and prototypes
Research activities
Community engagement
What is WordLift NG?
The study for the new platform for WordLift’s clients started with a whole new user journey, including an improved UX. New features, developed with content analysis, include automatic content detection, specific web page markup, and knowledge graph curation.
The main benefit of this development is to exploit long tail queries to be featured as speakable (voice) tagging for search helpers. The new backend lets users create dedicated landing pages and applications with direct queries in GraphQL.
The new platform also provides users with useful information about data shared in the Knowledge Graph, including traffic stats, Structured Data reports.
The development of NG involves features to bring WordLift’s technology to any CMS, the new on-boarding WebApp is part of that.
Envisioning a brand new customer journey, built to help publishers get their SEO done with a few easy steps, the new on-boarding web app guides the setup for users not running their websites on WordPress.
The workshop held various demos for applications developed by partners.
WordLift showcased a demo for semantic search, a custom search engine that uses deep learning models while providing relevant results when queried. With semantic search one can immediately understand the intent behind customers and provide significantly improved search results that can drive deeper customer engagement.
This feature would have a major impact on e-commerces.
WordLift applied semantic search to the tourism sector and to e-commerce.
The backend of the platform is being developed by RedLink, on state-of-the-art technologies.
The services are issued within a cloud microservice architecture which makes the platform scalable, and the data that today are published with WordLift is hosted on Microsoft Azure.
It will provide specific services and endpoints for the text analysis (Named Entity Recognition and Linking) data management (public and private knowledge graphs and schema, data publication), search (full text indexing) and conversation (natural language understanding, question answering, voice conversation) for its users.
GraphQL was selected to facilitate access to data in the Knowledge Graph by developers. Tools for interoperability between GraphQL and SPARQL were also tested and developed.
Data curation and Validation
An essential phase of the project is the collection of requirements and state of the art analysis in order to guarantee a perfectly functioning and functional product.
The requirements for WordLift NG were developed by SLT, the partner network and STI.
The results of the research activities are aimed at:
enhancement of content analysis – read more about this here
analysis of the methodologies for the identification of similar entities (in order to allow, on the basis of the analysis of the pages in the SERP, the creation or optimization of relevant content already present in the Knowledge Graph)
the algorithms for data enrichment in the Knowledge Graph and reconciliation with data from different sources
On this front, the Consortium is currently working on the definition for SD verification and validation of Schema markup.
This phase will ensure all statements are:
Semantically correct
Corresponding to real world entities (annotations must comply with content present and validated on the web)
and that annotations are compliant with given Schema definitions (correct usage of schema.org vocabulary).
Community Engagement
Part of the project is the beta testing and the presentation of the platform to WordLift’s existing customers.
We’d be thrilled to share our findings on structured data with the SEO community and very happy to support open sharing of the best practices also from Google and Bing (both seem to be willing to share in machine-readable format the guidelines for structured data markup).
WordLift is an official member of the DBPedia community and will actively contribute to DBpedia Global. Find out more.
If you’re willing to know more about it, and to be included in the testing of the new features contact us or subscribe to our newsletter!
With the rise of knowledge graphs (KGs), interlinking KGs has attracted a lot of attention. Finding similar entities among KGs plays an essential role in knowledge integration and KG connection. It can help end-users and search engines more effectively and easily access pertinent information across KGs.
In this blog post, we introduce a new research paper and the approach that we are experimenting with within the context of Long-tail SEO.
Long-tail SEO
One of the goals that we have for WordLift NG is to create the technology required for helping editors go after long-tail search intents. Long-tail queries are search terms that tend to have lower search volume and competition rate, as well as a higher conversion rate. Let me give you an example: “ski touring” is a query that we can intercept with a page like this one (or with a similar page). Our goal is twofold:
helping the team at SalzburgerLand Tourismus (the use-case partner of our project) expand on their existing positioning on Google by supporting them in finding long-tail queries;
helping them enrich their existing website with content that matches that long-tail query and that can rank on Google.
In order to facilitate the creation of new content we proceed as follows:
analyze the entities behind the top results that Google proposes (in a given country and language) for a given query.
find a match with similar entities on the local KG of the client.
To achieve the first objective WordLift has created an API (called long-tail) that will analyze the top results and extract a short summary as well as the main entities behind each of the first results.
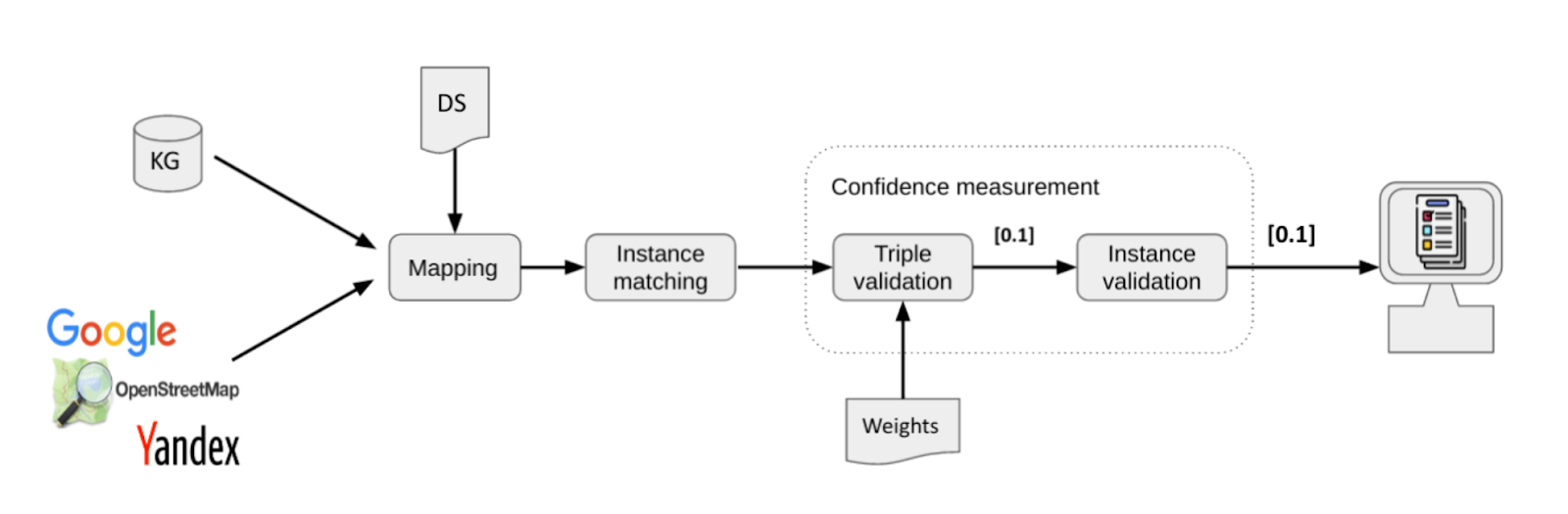
Now given a query entity in one KG (let’s say DBpedia), we intend to propose an approach to find the most similar entity in another KG (the graph created by WordLift on the client’s website) as illustrated in Figure 1.
Figure 1. The interlinking problem over the knowledge graphs
The main idea is to leverage graph embedding, clustering, regression and sentence embedding as shown in Figure 2.
Figure 2. The proposed approach
In our proposed approach, RDF2Vec technique has been employed to generate vector representations of all entities of the second KG and then the vectors have been clustered based on cosine similarity using K medoids algorithm. Then, an artificial neural network with multilayer perceptron topology has been used as a regression model to predict the corresponding vector in the second knowledge graph for a given vector from the first knowledge graph. After determining the cluster of the predicated vector, the entities of the detected cluster are ranked through the sentence-BERT method and finally, the entity with the highest rank is chosen as the most similar one. If you are interested in our work, we strongly recommend you to read the published paper.
Conclusions and future work
To sum up, the proposed approach to find the most similar entity from a local KG with a given entity from another KG, includes four steps: graph embedding, clustering, regression and ranking. In order to evaluate the approach presented, the DBPedia and SalzburgerLand KGs have been used as the KGs and the available entity pairs which have the same relation, have been considered as training data to train the regression models. The absolute error (MAE), R squared (R2) and root mean square error (RMSE) have been applied to measure the performance of the regression model. In the next step, we will show how the proposed approach leads to enriching the SalzburgerLand website when it takes the main entities from the long-tail API and finds the most similar entities in the SalzburgerLand KG.
Reference to the paper with full details: Aghaei, S., Fensel, A. „Finding Similar Entities Across Knowledge Graphs“, in Proceedings of the 7th International Conference on Advances in Computer Science and Information Technology (ACSTY 2021), Volume Editors: David C. Wyld, Dhinaharan Nagamalai, March 20-21, 2021, Vienna, Austria.
If you are a developer, you probably have already worked with or heard about SEO (Search Engine Optimization). Nowadays, when optimizing websites for search engines, the focus is on annotating websites’ content so that search engines can easily extract and “understand” the content. Annotating, in this case, is the representation of information presented on a website in a machine-understandable way by using a specific predefined structure. Noteworthy, the structure must be understood by the search engines. Therefore, in 2011 the four most prominent search engine providers Google, Microsoft, Yahoo!, and Yandex, founded Schema.org. Schema.org provides patterns for the information you might want to annotate on your websites, including some examples. Those examples allow web developers to get an idea of making the information on their website understandable by search engines.
Knowledge Graphs
Besides using the websites’ annotations to provide more precise results to the users, search engines use them to build so-called Knowledge Graphs. Knowledge Graphs are huge semantic nets describing “things” and their connections between each other.
Consider three “things”, i.e. three hiking trails “Auf dem Jakobsweg”, “Lofer – Auer Wiesen – Maybergklamm” and “Wandergolfrunde St. Martin” which are located in the region “Salzburger Saalachtal” (another “thing”). “Salzburger Saalachtal” is located in the state “Salzburg,” which is part of “Austria.” If we drew those connections on a sheet, we would end up with something that looks like the following.
This is just a small extract of a Knowledge Graph, but it shows pretty well how things are connected with each other. Search engine providers collect data from a vast amount of websites and connect the data with each other. Not only search engine providers are doing so but even more companies are building Knowledge Graphs. Also, you can build a Knowledge Graph based on your annotations, as they are a good starting point. Now you might think that the amount of data is not sufficient for a Knowledge Graph. It is essential to mention that you can connect your data with other data sources, i.e., link your data or import data from external sources. There exists a vast Linked Open Data Cloud providing linked data sets of different categories. Linked in this case means that the different data sets are connected via certain relationships. Open implies that everyone can use it and import it into its own Knowledge Graph.
An excellent use case for including data from the Linked Open Data Cloud is to integrate geodata. For example, as mentioned earlier, the Knowledge Graph should be built based on the annotations of hiking trails. Still, you don’t have concrete data on the cities, regions, and countries. Then, you could integrate geodata from the Linked Open Data Cloud, providing detailed information on cities, regions, and countries.
Over time, your Knowledge Graph will grow and become quite huge and even more powerful due to all the connections between the different “things.”
Sounds great, but how can I use the data in the Knowledge Graph?
Unfortunately, this is where a huge problem arises. For querying the Knowledge Graph, it is necessary to write so-called SPARQL queries, a standard for querying Knowledge Graphs. SPARQL is challenging to use if you are not familiar with the syntax and has a steep learning curve. Especially, if you are not into the particular area of Semantic Web Technologies. In that case, you may not want to learn such a complex query language that is not used anywhere else in your daily developer life. However, SPARQL is necessary for publishing and accessing Linked Data on the Web. But there is hope. We would not write this blog post if we did not have a solution to overcome this gap. We want to give you the possibility, on the one hand, to use the strength of Knowledge Graphs for storing and linking your data, including the integration of external data, and on the other hand, a simple query language for accessing the “knowledge” stored. The “knowledge” can then be used to power different kinds of applications, e.g., intelligent personal assistants. Now you have been tortured long enough. We will describe a simple middleware that allows you to query Knowledge Graphs by using the simple syntax of GraphQL queries.
What is GraphQL?
GraphQL is an open standard published in 2015, initially invented by Facebook. Its primary purpose is to be a flexible and developer-friendly alternative to REST APIs. Before GraphQL, developers had to use API results as predefined by the API provider even if only one value was required by the user of the API. GraphQL allows specifying a GraphQL query in a way that only the relevant data is fetched. Additionally, the JSON syntax of GraphQL makes it easy to use. Nearly every programming language has a JSON parser, and developers are familiar with representing data using JSON syntax. The simplicity and ease of use also gained interest in the Semantic Web Community as an alternative for querying RDF data. Graph database (used to store Knowledge Graphs) providers like Ontotex (GraphDB) and Stardog introduced GraphQL as an alternative query language for their databases. Unfortunately, those databases can not be exchanged easily due to the different kinds of GraphQL schemas they require. The GraphQL schema defines which information can be queried. Each of the database providers has its own way of providing this schema.
Additionally, the syntax of the GraphQL queries supported by the database providers differs due to special optimizations and extensions. Another problem is that there are still many services available on the Web that are only accessible via SPARQL. How can we overcome all this hassle and reach a simple solution applicable to arbitrary SPARQL endpoints?
GraphSPARQL
All those problems led to a conceptualization and implementation of a middleware transforming GraphQL into SPARQL queries called GraphSPARQL. As part of the R&D work that we are doing, in the context of the EU-cofounded project called WordLift Next Generation, three students from the University Innsbruck developed GraphSPARQL in the course of a Semantic Web Seminar
Let us consider the example of a query that results in a list of persons’ names to illustrate the functionality of GraphSPARQL. First, the user needs to provide an Enriched GraphQL Schema, in principle defining the information that should be queryable by GraphSPARQL. This schema is essential for the mapping between the GraphQL query and the SPARQL query.
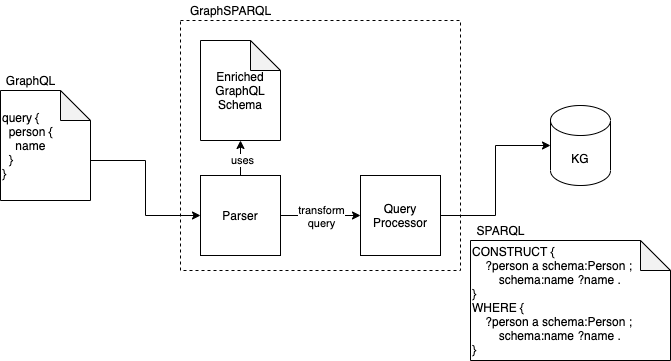
The following figure shows the process of an incoming query and transforming it to a SPARQL query. If you want to query for persons with their names, the GraphQL query shown on the left side of the figure will be used. This query is processed inside GraphSPARQL by a so-called Parser. The Parser uses the predefined schema to transform the GraphQL query into the SPARQL query. This SPARQL query is then processed by the Query Processor. It handles the connection to the Knowledge Graph. On the right side of the figure, you see the SPARQL query generated based on the GraphQL query. It is pretty confusing compared to the simple GraphQL query. Therefore, we want to hide those queries with our middleware.
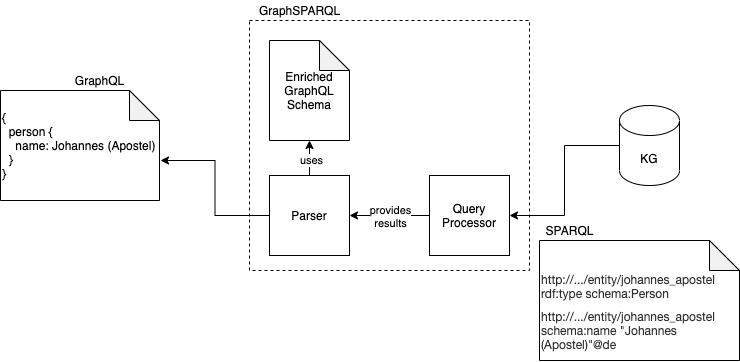
As a result of the SPARQL query, the Knowledge Graph responds with something that seems quite cryptic, if you are not familiar with the syntax. You can see an example SPARQL response on the following figure’s right side. This cryptic response is returned to the Parser by the Query Processor. The Parser then, again with the help of the schema, transforms the response into a nice-looking GraphQL response. The result is a JSON containing the result of the initial query.
GraphSPARQL provides you easy access to the information stored in a Knowledge Graph using the simple GraphQL query language.
You have a Knowledge Graph stored in a graph database that is accessible via SPARQL endpoint only? Then GraphSPARQL is the perfect solution for you. Before you can start, you need to follow two configuration steps:
Provide the so-called Enriched GraphQL Schema. This schema can either be created automatically based on a given ontology, e.g., schema.org provides its ontology as a download or can be defined manually. An example for both cases can be found on the GraphSPARQL Github page in the example folder: – automatic creation of a schema based on the DBPedia ontology – manually defined schema
Define the SPARQL endpoint GraphSPARQL should connect to. This can be done in the configuration file (see “config.json” in the example folder).
Have you done both preparation steps? Perfect, now you are ready to use GraphSPARQL on the endpoint you defined. Check the end of the blog post if you are interested in a concrete example.
Summary
– What are the benefits of GraphSPARQL? – Benefit from Knowledge Graphs by using a simple query language – Simple JSON syntax for defining queries – Parser support for the JSON syntax of GraphQL queries in nearly all programming languages – GraphQL query structure represents the structure of the expected result – Restrict data access via the provided GraphQL schema
GraphSPARQL as middleware allows querying SPARQL endpoints using GraphQL as a simple query language and is an important step to open Semantic Web Technologies to a broader audience.
Example
Docker container to test GraphSPARQL:
Two options to start the docker container are supported so far:
Use predefined configuration for DBPedia: start the GraphSPARQL docker container
If you work in SEO, you have been reading about Google and Bing becoming semantic search engines but, what does Semantic Search really mean for users, and how things work under the hood?
Semantic Search helps you surface the most relevant results for your users based on search intent and not just keywords.
Semantic (or Neural) Search uses state of the art deep learning models to provide contextual and relevant results to user queries. When we use semantic search we can immediately understand the intent behind our customers and provide significantly improved search results that can drive deeper customer engagement. This can be essential in many different sectors but – here at WordLift – we are particularly interested in applying these technologies to: travel brands, e-commerce and online publishers.
Information is often unstructured and available in different silos, using semantic search our goal is to use machine learning techniques to make sense of content and to create a context. When moving from syntax (for example how often a term appears on a webpage) to semantics, we have to create a layer of metadata that can help machines grasp the concepts behind each word. Google defines this ability to connect words to concepts as “Neural Matching” or *super synonyms* that help better match user queries with web content. Technically speaking this is achieved by using neural embeddings that transform words (or other types of content like images, video or audio clips) to fuzzier representations of the underlying concepts.
As part of the R&D work that we’re doing, in the context of the EU-cofounded project called WordLift Next Generation, I have built the prototype using an emerging open-source framework called Jina AI and the beautiful photographic material published by Salzburgerland Tourismus (also a partner in the Eurostars research project) and Österreich Werbung 🇦🇹 (Austrian National Tourist Office).
I have created this first prototype:
☝️ to understand how modern search engines work;
✌️ to re-use the same #SEO data that @wordliftit publishes as structured *linked* data for internal search.
How does Semantic Search work?
Bringing structure to information, is what WordLift does by analyzing textual information using NLP and named entity recognition, and now also images using deep learning models.
With semantic search, these capabilities are combined to let users find exactly what they need naturally.
In Jina, Flows are high-level concepts that define a sequence of steps to accomplish a task. Indexing and querying are two separate Flows; inside each flow, we run parallel Pods to analyze the content. A Pod is a basic processing unit in a Flow that can run as a dockerized application.
This is strategic as it allows us to distribute the load efficiently. In this demo, Pods are programmed to create neural embeddings: one pod to processes text and one for images. Pods can also run in parallel and the results (embeddings from the caption and embeddings from the image) are combined into one single document.
This ability to work with different content types is called multi-modality.
The user uses a text in the query to retrieve an image or vice-versa; the user uses an image, in the query, to retrieve its description.
See in the example below; I make a search using natural language at the beginning and right after, I send an image (from the results of the first search) as query to find its description 👇
Are you ready to innovate your content marketing strategy with AI? Let’s talk!
What is Jina AI?
Han Xiao, Jina AI’s CEO, calls Jina the “TensorFlow” for search 🤩. Besides the fact that I love this definition, Jina is completely open source, and designed to help you build neural (or semantic) search on the cloud. Believe me it is truly impressive. To learn more about Jina, watch Han’s latest video on YouTube “Jina 101: Basic concepts in Jina“.
How can we optimize content for Semantic Search?
Here is what I learned from this experiment:
When creating content, we shall focus on concepts (also referred to as entities) and search intents rather than keywords. An entity is a broader concept that groups different queries. The search intent (or user intent) is the user’s goal when making the query to the search engine. This intent can be expressed using different queries. The search engines interpret and disambiguate the meaning behind these queries by using the metadata that we provide.
Information Architecture shall be designed once we understand the search intent. We are used to thinking in terms of 1 page = 1 keyword, but in reality, as we transition from keywords to entities (or concepts), we can cover the same topic across multiple documents. After crawling the pages, the search engine will work with a holistic representation of our content even when it has been written across various pages (or even different media types).
Adding structured data for text, images, and videos adds precious data points that will be taken into account by the search engine. The more we provide high-quality metadata, the more we help the semantic search engine improve the matching between content and user intent.
Becoming an entity in Google’s Knowledge Graph also greatly helps Google understand who we are and what we write about. It can have an immediate impactacross multiple queries that refer to the entity. Read this post to learn more how to create an entity in Google’s graph.
Working with Semantic Search Engines like Google and Bing, require an update of your content strategy and a deep understanding of the principles of Semantic SEO and machine learning.
























Recent Comments