
Multimodal Search: Exploring The Multilingual Path
Deep neural networks are powerful tools with many possible applications at the intersection of the vision-language domain. One of the key challenges facing many applications in computer vision and natural language processing is building systems that go beyond a single language and that can handle more than one modality at a time.
These systems, capable of incorporating information from more than one source and across more than one language, are called multimodal multilingual systems. In this work, we provide a review of the capabilities of various artificial intelligence approaches for building a versatile search system. We also present the results of our multimodal multilingual demo search system.
What is a multimodal system?
Multimodal systems jointly leverage the information present in multiple modalities such as textual and visual information. These systems, aka cross-modal systems, learn to associate multimodal features within the scope of a defined task.
More specifically, a multimodal search engine allows the retrieval of relevant documents from a database according to their similarity to a query in more than one feature space. These feature spaces can take various forms such as text, image, audio, or video.
“A search engine is a multimodal system if its underlying mechanisms are able to handle different input modals at the same time.”
Why are multimodal systems important?
The explosive growth in the amount of a wide variety of data makes it possible, and necessary, to design effective cross-modal search engines to radically improve the search experience in the scope of a retrieval system.
One interesting multimodal system is building a search engine that enables users to express their input queries through a multimodal search interface. As the goal is to retrieve images relevant to the multimodal input query, the search engine’s user interface and the system under the hood should be able to handle the textual and the visual modalities in conjunction.
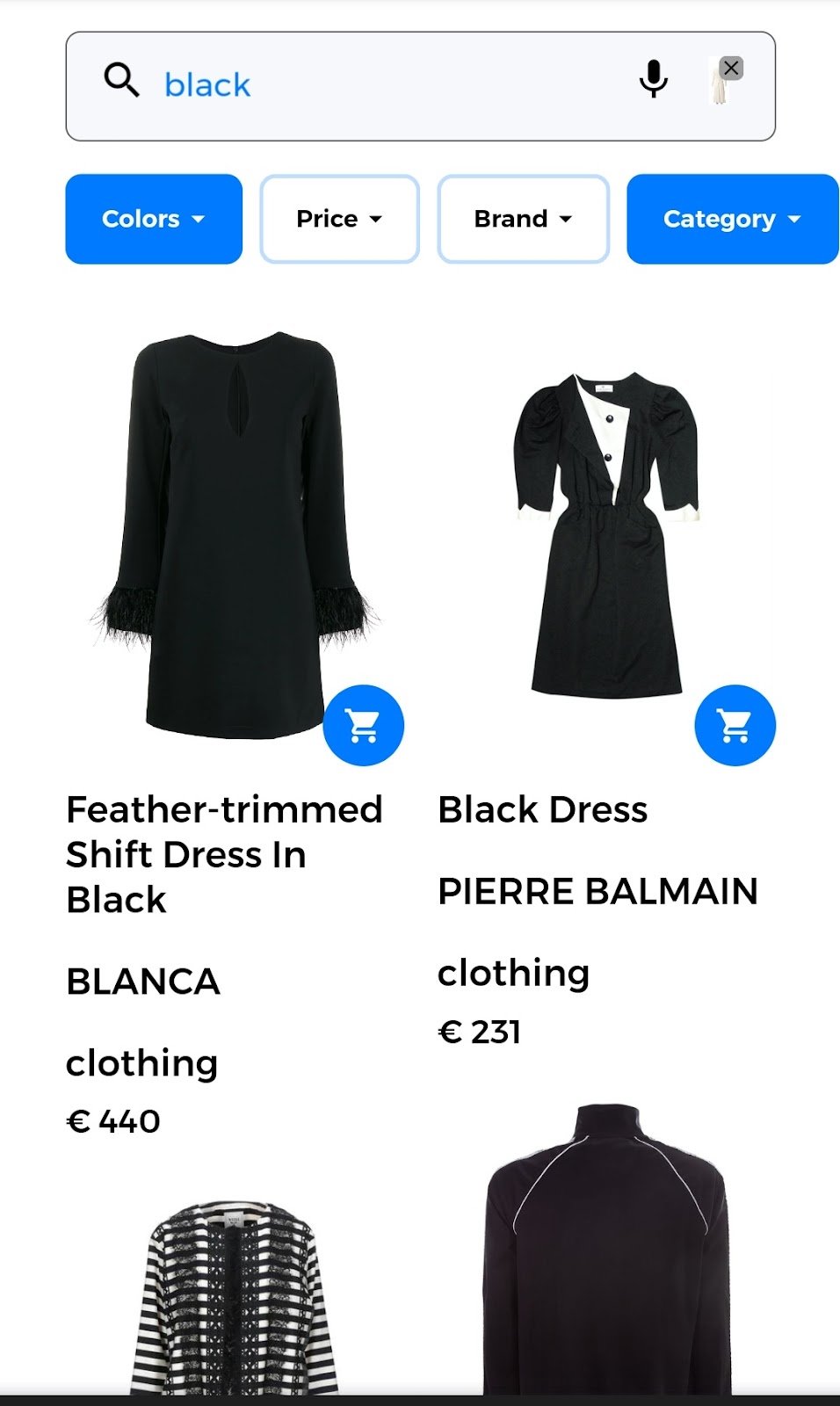
For instance, a search query could take the form of “give me something like this image but I want it to be black”. As shown in the image below, the user provides to the search engine 1) an image of the dress that she’s looking for and 2) a text, or another input form, to indicate the desired color. This way of expression, comparable to how humans communicate, would promote a much better search experience.
When running this search, the input image is a white dress that is shown in the image below. This is the first part of the query which corresponds to the visual part of the multimodal query.

The second part of this query consists of the desired color which is the textual input. In this case, the user is looking for dresses that are “black”. The returned results are images of the dresses that are available at the e-commerce store. The result of the multimodal query is shown in the image below.
Given the richness and diversity within each modality, designing a multimodal system requires efforts to bridge the gap between the various modality, including image, text, video, and audio data. Encoding the textual and the visual modalities into a joint embedding space is one way for bridging the worlds of varying modalities.
While the image is language agnostic, the search terms are language-specific. Monolingual vision-language systems limit the usefulness of these systems in international applications. In general, these monolingual systems are English-only. Let’s now examine cross-lingual approaches in the context of textual and visual retrieval systems.
What is a multilingual system?
Let’s examine one of many key challenges at the intersection of computer vision and natural language processing. We quickly observe the limitation of the current systems to expand beyond a single language.
“A search system is multilingual if the system is able to retrieve relevant documents from the database by matching the document’s captions written in one language with the input text query in another language. Matching techniques range from syntaxical mechanisms to semantic search approaches.”
The task of designing a multilingual system boils down to building language models that support the addition of new languages. Consequently, a large number of additional parameters is required each time a new language is added. In reality, these parameters support the word embeddings that represent the newly added language’s vocabulary.
The primary use case of our multimodal multilingual system is an image-sentence retrieval task where the goal is to return relevant images from the database given a query image and a sentence at the same time. In this vein, we’ll explore the multimodal path and address the challenge of supporting multiple languages.
Towards multimodal and multilingual systems
Learning a good language representation is a fundamental component of addressing a vision-language task. The good news is that visual concepts are interpreted almost in the same way by all humans. One way is to align textual representations to images. Pairing sentences in different languages with visual concepts is a first step to promote the use of cross-lingual vision-language models while improving them.
It has been demonstrated that such approaches can accomplish better performance compared to traditional ones, i.e. text-only trained representations, across many vision-language tasks like visual question answering or image-sentence retrieval. However, many of these promising methods only support a single language which is, in most cases, the English language.
“A multimodal multilingual system is a combination of each of the multimodal and multilingual systems that are described in the previous sections.”
A large number of cross-modal approaches require much effort to pre-train and fine-tune multiple pairs of languages. Many of them have hand-crafted architectures that are dedicated, or at least, perform best at a specific vision-language task. In addition, many of these existing systems are able to handle one modality at a time. For instance, retrieve a relevant sentence from a corpus given an image or retrieve a relevant image from the database given a sentence.
BERT has paved the way for the large adoption of representation learning models based on transformers. BERT follows a two-fold training scheme. The first consists of pre-training a universal backbone to obtain generalizable representations from a large corpus using self-supervised learning. The second one is a fine-tuning task for specific tasks via supervised learning.
Recent efforts, such as MPNet build upon the advantages of BERT by adopting the use of masked language modeling (MLM). In addition, MPNet novel pretraining takes into consideration the dependency among the predicted tokens through permuted language modeling (PLM) – a pre-training method introduced by XLNet.
While these approaches are capable of transferring across different languages beyond English, the transfer quality is language-dependent. To address this computational roadblock, some approaches tried to limit the language-specific features for just a few by using masked cross-language modeling approaches.
Cross-modal masked language modeling (MLM) approaches consist of randomly masking words and then predicting them based on the context. On the one hand, cross-language embeddings can then be used to learn to relate embeddings to images. On the other hand, these approaches are able to align the embeddings of semantically similar words nearby, including words that come from different languages. As a result, this is a big step towards the longstanding objective of a multilingual multimodal system.
Training and fine-tuning a multilingual model is beyond the scope of this work. As BERT and MPNet have inspired de-facto multilingual models, mBERT, and mMPNet, we’re using such available multilingual pre-trained word embeddings to build the flow of a multilingual multimodal demo app.
Demo app: multilingual and multimodal search
The end goal of the search engine is to return documents that satisfy the input query. Traditional information retrieval (IR) approaches are focused on content retrieval which is the most fundamental IR task. This task consists of returning a list of ranked documents as a response to a query. Neural search, powered by deep neural network information retrieval (or neural IR), is an attractive solution for building a multimodal system.
The backbone of this demo app is powered by Jina AI, an open-source neural search ecosystem. To learn more about this neural search solution you get started here. Furthermore, don’t miss checking this first prototype that shows how Jina AI enables semantic search.
To build this search demo, we modeled textual representations using the Transformer architecture from MPNet available fromHugging Face (multilingual-mpnet-base-v2 to be specific). We processed image captions and the textual query input using this encoder. As for the visual part, we used another model made available and called MobileNetV2.
The context
In what follows, we present a series of experiments to validate the results of the multilingual and multimodal demo search engine. Here are the two sets of experiments:
- The first set of tests aims to validate that the search engine is multimodal. In other words, the search engine should be able to handle textual and images features simultaneously.
- The second set of tests aims to validate that the search engine is multilingual and able to understand textual inputs in multiple languages.
Before detailing these tests, there are a few notes to consider:
- The database consists of 540 images related to Austria.
- Every image has a caption that is written in English.
- Each modality can be assigned a weight that defines the importance of each modality. A user can assign a higher weight to either the textual or the visual query input (the sum of the weights should always be 1). By default, both modalities have an equal weight.
The following table summarizes these experiments.
| Test | Setting |
| Test 1A | Multimodal inputs with equal weights |
| Test 1B | Multimodal inputs with a higher weight for the image |
| Test 1C | Multimodal inputs with a higher weight for the text |
| Test 2A | Multimodal inputs with a textual query in English |
| Test 2B | Multimodal inputs with a textual query in French |
| Test 2C | Multimodal inputs with a textual query in German |
| Test 2D | Multimodal inputs with a textual query in Italian |
The results
For the first set of tests (Test 1A, 1B, and 1C), we use the same multimodal query made of an image and a text as shown below. This input query consists of:
- An image: a church in Vienna and
- The textual input: Monument in Vienna
Test 1A – Multimodal inputs with equal weights
In Test 1A, the weight of the image and the textual input are equal. The returned results show various monuments in Vienna like statues, churches, and museums.

Test 1B – Focus on the image input
Test 1B gives more weight to the image and completely ignores the textual inputs. The intention is to test the impact of the input image without the text. In practice, the search result is composed of various monuments that, most of them, contain buildings (no more statues). For instance, we can see many churches, the auditorium, city views, and houses.

Test 1C – Focus on the textual input
Test 1C is the opposite of Test 1B. All the weight is given to the textual input (the image is blank, it is ignored). The results are aligned with input sentence monuments in Vienna. As shown in the image below, various types of monuments are returned. The results are no longer limited to buildings. We can see statues, museums, and markets in Vienna.

Test 2A – Multilingual queries
As mentioned earlier, the captions associated with the images are all in English. For the sake of this test, we chose the following 4 languages to conduct the multilingual experiments:
- English (baseline)
- French
- German
- Italian
We translated the following query to each of these four languages: grapes vineyards. As for the weight, the textual input has a slightly higher weight (0.6) in order to eliminate potential minor noise signals.
For each of the 4 languages, we run a test using the English version of the MPNet transformer (sentence-transformers/paraphrase-mpnet-base-v2) and then its multilingual version (multilingual mpnet). The goal is to validate that a multilingual transformer is able to grasp the meaning of the textual query in different languages.
Test 2A – English + monolingual textual encoding
The query is in English: grapes vineyards and the encoder is monolingual.

Test 2B – English + multilingual textual encoding
The query is in English: grapes vineyards and the encoder is multilingual.

Test 2B – French + monolingual textual encoding
The query is in French: raisins vignobles and the encoder is monolingual.

Test 2B – French + multilingual textual encoding
The query is in French: raisins vignobles and the encoder is multilingual.

Test 2C – German + monolingual textual encoding
The query is in German: Trauben Weinberge and the encoder is monolingual.

Test 2C – German + multilingual textual encoding
The query is in German: Trauben Weinberge and the encoder is multilingual.

Test 2D – Italian + monolingual textual encoding
The query is in Italian: uva vigneti and the encoder is monolingual.

Test 2D – Italian + mono lingual textual encoding
The query is in Italian: uva vigneti and the encoder is multilingual.

Insights and discussions
Comparing the edges cases (Test 1B and Test 1C) with the test where the two modalities have the same weight (Test 1A) show that:
- The results of Test 1A take into consideration both the image and the text. The first two images refer to churches and at the same time the result set contains other types of monuments in Vienna.
- Test B that focuses on the image returns only images in the category of buildings, ignoring every other type of monument in Vienna.
- Test C that focuses on the text returns various types of monuments in Vienna.
As for testing the multilingual capabilities across four languages. We can clearly see that for the English language, the mono and multilingual performance are good and are almost similar. This is expected as both encoders are trained on a corpus language. A small note regarding the monolingual encoder for the French language, the first three results are surprisingly good for this specific query.
As for the three remaining languages, the multilingual encoder returns much more relevant results than the monolingual encoder. This shows that this multimodal multilingual search demo is able to understand queries written in one language and return relevant images with captions written in English.
The future of neural search
Neural search is attracting widespread attention as a way to build multimodal search engines. Deep learning-centric neural search engines have demonstrated multiple advantages as reported in this study. However, the journey of building scalable and cross-domain neural search engines has just begun.
Recent Comments