
What is an entity in the Semantic Web?
In the Semantic Web an entity is the “thing” described in a document. An entity helps computers understand everything you know about a person, an organization or a place mentioned in a document. All these facts are organized in statements known as triples that are expressed in the form of subject, predicate, and object.
Take for example an article on the Chinese invasion of Tibet that refers to the prophecies that [Thubten Gyatso] made twenty years before the invasion. [Thubten Gyatso] as a string is composed by two separate words but as an entity it has a much richer meaning. [Thubten Gyatso] is a person, more specifically he’s the 13th Dalai Lama who was born in the Tsang-Ü province in Tibet on the 12th of February 1876. In the context of Semantic Web, an article annotated with the entity of [Thubten Gyatso], conveys all this information about the 13th Dalai Lama in a way that computers can understand it and, as you might suspect, computers might not be too familiar with the history of Tibetan Buddhism.
Every document on the Web is about many different kind of “things”. Entities describe content using knowledge models known as graphs that help computers “think” the way we do and that help us, in return, find information more efficiently.
Entities are linked to one another. Each entity holds the information required to provide direct answers to questions about itself (i.e. “When was Thubten Gyatso born?”) and questions that can be answered by looking at the relationships with other entities (i.e. “Was Trinley Gyatso his predecessor?”).
What is an Entity in WordLift?
Entities in WordLift are web pages that describe the “things” that we talk the most in our website. All the entities are organised in a vocabulary within WordPress. Each entity is a web page and corresponds to a data point that WordLift creates in the web of data.
WordLift publishes entities and their properties in an intelligent model — technically called “graph” — designed to help computers understand real-world “things” and their relationships to one another. The graph is published using linked data and it is used, in WordLift, to enrich all content published on a website.
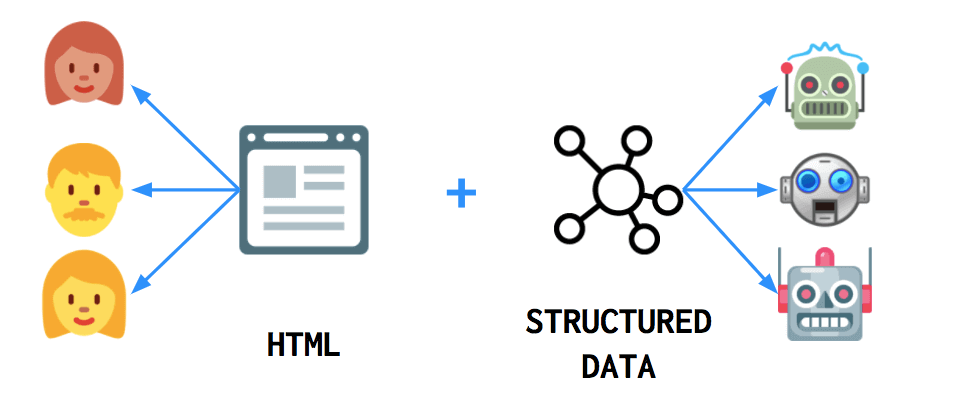
Let’s take this page as an example. This is the entity page to describe what entities are. You are reading content from this webpage, a hypertext document that is connected to the World Wide Web. At any time a crawler, a smart agent or a chatbot can read this same information by looking at the structured data that WordLift has created for this entity.
While humans can read a web document, for a computer is way easier to read semantically-rich data linked to other data published in openly available datasets.
How is an entity different from an article or a web page?
WordLift uses Entities in three ways:
- Entities describe the “things” that you talk about in your articles using 5-stars linked data so that search engines can unquestionably understand what you’re writing about
- Entities help organize the content that you’re writing. As you annotate an article with an entity, WordLift creates a relationship between the article and entity in such a way that a computer can understand it. These relationships are stored in the graph of the website and are used to provide meaningful recommendations to your readers
- Entities provide contextual information to the audience. Take for example Linked Data – this is a concept that I used in this article and you might not be familiar with. In this case, WordLift helps me create a link so that you can find out more what linked data is and avoid jumping on another website to get the same information.
Entities have to be relevant to the content that you’re writing and in a way define your content strategy and the knowledge domain you’re addressing with your website.
What are the guidelines for creating new entities to annotate a blog post or a page?
A basic guideline for adding a new entity is:
“I should create entities that a librarian would plausibly use to classify the content I am writing as if it was a book“
In some cases key concepts that are important for our audience are not automatically detected by WordLift. In this case, we can create them and teach WordLift – as well as search engines, so that they will be able to recognise them in the future.
Let me give you an example. When a new concept was introduced to describe PASO an acronym for Personal Assistant Search Optimisation, I created a new entity on this website and described it using structured data with WordLift.
As you can see in the video below, the entity, after few weeks, became a featured snippet. By doing so Google Home was able to provide a simple definition of PASO using the content from this same website.
I have already several articles that could be used to organize the content on my website, can I turn them into entities?
Yes, you can now convert your existing articles or pages into entities with a simple click. This helps you reuse your cornerstone articles to reorganize the content on your website and improve the search rankings of these pages.
Cornerstone articles are usually meant to describe the “things” you care the most and are a perfect match for becoming entities.
How Can I Link Entities With One Another?
According to Schema.org the sameAs property is:
URL of a reference Web page that unambiguously indicates the item’s identity. E.g., the URL of the item’s Wikipedia page, Wikidata entry, or official website.
It is like you’re saying to the search engine “this is the same thing as the one you find at this address.” Today only between 10,000 to 50,000 domains use this property. That is also why you can make a difference for your SEO strategy by using it.
However the sameAs property alone might not be enough if you need to query the data that you’re publishing (or simply if you want others to query the data that you’re publishing across multiple datasets).
You need something more. You need to publish data following the so-called five-stars open data scheme introduced by Berners-Lee, that requires you to link every piece of data with other data.
Here is where the owl:sameAs property comes into play.
How Can you Link Entities from your WordPress Site to the Linked Open Data Cloud?
Imagine we want to explain to a search engine Matt Mullenweg is and link the page I have for him on my blog with entities in the LOD cloud. How do I do that on my WordPress website?

As you can see above, I used WordLift within my WordPress to create a page about Matt Mullenweg. That page is set up as a Schema Entity Type “person”. To make it clear who I am talking about I run a search using WordLift that taps into giant graphs published in LOD and in a snap I can get the reference to the entity of Matt Mullenweg on Freebase, Wikidata, and DBpedia.
Once I update the page, the Schema sameAs, and the owl:sameAs properties are automatically added by WordLift and made available to search engines.
We can now use the Structured Data Testing Tool of Google to see how the search engine sees the page:

The structured data has been created without writing a single line of code and now Google can crawl and index that page way more efficiently. However, there is also more to it.
Now my data is interoperable with other datasets and published also off-page in an RDF-based knowledge graph.
An entity is a form of storing information, the entity can be a person, organization, place, or an object. An entity helps computers understand everything you know about a person, an organization or a place mentioned in a document.
An entity can have several tangible and intangible forms, a person can be one type of entity. An entity can be a single thing, person, place, or an object.
In business, entity means the organization, it refers to the legal structure created by a single person, group of people, or another entity for the purpose of conducting business regardless to the type of business.
Another word for entity is anything that has its own existence. Entity is an existing or real thing a distinction between a thing’s existence and its qualities.
@data annotation in Java is used to bundle a group of features and generate getters for all fields, to indicate that a variable should be treated as a collection. This allows annotations to be retained by the Java virtual machine at run-time and read via reflection.
Entity C# is a preprocessor that allows you to add metadata to your code that can be used by other tools, such as Source Insight, to assist with finding bugs.