Fact-Checking in the Age of AI: Navigating Truth, Entities, and SEO
Introducing WordLift's new fact-checking API and AI agent: your allies in ensuring online content accuracy.

“It is the mark of an educated mind to be able to entertain a thought without accepting it.”
Aristotele – True or False?
In an era where the veracity of information is constantly scrutinized, the quote above is an interesting example, as it often gets misattributed to Aristotle. This clarifies the critical need for fact-checking. Fact-checking, I have to admit, is not on the trending side of AI, and most SEOs have, in general, little or no knowledge of its significance. Nevertheless, here at WordLift, we build knowledge graphs that aid machines in discerning facts, and as the new year begins, I decided to take a few steps in this direction. With the help of our fantastic team, I built an API to help publishers and e-commerce platforms semi-automate fact-checking.
Here is the index for this article. Feel free to skim through.
- What is fact-checking?
- History of the ClaimReview Markup and Google’s Involvement
- 2016: Introduction of the ‘Fact Check Tab’
- Early 2017: Enabling Publishers with Fact Check Tag
- 2019: Google’s Fact-Checked Articles: A Significant Reach and New Tools
- 2021: One Page, One Claim. Google’s Eligibility Criteria for Fact-Check Rich Results
- 2022: Google introduces the Fact Check Tool API and continues investing in Fact-Checking
- 2023: Fact-checking becomes multimodal
- Fact-checking in Google Search Generative Experience (SGE)
- ClaimReview markup explained
- Fact-Checking for E-commerce Websites
- Semi-Automating Fact-Checking with an AI Agent [code available]
- Epistemology, Ethics, and SEO
- Conclusions and future research work
- References
Let’s run a first test (and yes, I will also share the code behind it so that anyone can extend it and improve it).

Ok, let’s take a step back first. As we navigate the murky waters of misinformation, the role of fact-checking becomes critical in preserving the integrity of discourse and knowledge. With the advent of AI-generated content, the challenge of discerning truth from falsehood has taken on completely new dimensions, demanding more sophisticated, scalable, and reliable verification methods. This intersection of technology and truth-seeking is reshaping the landscape of fact-checking, making it an essential tool for individuals, online publishers, shop owners, and search engines in the quest for accuracy and SEO relevance.
What Is Fact-Checking?
Fact-checking is the rigorous process of verifying factual assertions in the text (or in media) to ensure the accuracy and credibility of the information presented. This practice has a storied history, tracing back to the early 20th century when magazines began employing fact-checkers to verify what journalists wrote. Over time, fact-checking has evolved from a publishing safeguard to a journalistic specialty, particularly in politics.
In journalism and digital media, fact-checking involves a meticulous process that includes cross-referencing information with credible sources, consulting databases, and sometimes conducting interviews with subject matter experts. Journalists and fact-checkers work in tandem to uphold the integrity of the content, a task that has become increasingly complex with the proliferation of digital platforms where anyone can publish information.
The impact of misinformation cannot be overstated. In our hyper-connected society, false information spreads rapidly, influencing public opinion and shaping political and social discourse. This alpine panorama, for example, doesn’t exist. It is inspired by the beautiful mountains of SalzburgerLand, but created using Midjourney with a simple prompt:
“Equirectangular photograph of a mountain landscape in SalzburgerLand”.

The consequences of misinformation are far-reaching, affecting everything from public health to democratic processes.
History of the ClaimReview Markup and Google’s Involvement
Google has played a pivotal role in developing the ClaimReview markup since its early inception in 2015. The initiative for ClaimReview began when Google, in collaboration with fact-checking leaders like Glenn Kessler from the Washington Post, Bill Adair from Duke Reporters’ Lab, and Dan Brickley 👏 from Schema.org, began to address the challenge of identifying and verifying factual information in the digital news environment.
The primary goal of Google has always been to enable the infrastructure to categorize and identify fact-checking content on the Web systematically.
2016: Introduction of the ‘Fact Check Tab’
Google introduced the ‘Fact Check Tab’ in 2016, a crucial year marked by the U.S. presidential election. This strategic move provided users easy access to fact-checked information during heightened political activity and information dissemination.
Early 2017: Enabling Publishers with Fact Check Tag
Google announced the integration of a fact-check tag in its search and news results. This feature was not about Google conducting its fact checks but aggregating and highlighting fact checks from authoritative sources like PolitiFact and Snopes.
Publishers wishing to feature in these fact-checked sections had to use the ClaimReview markup and adhere to the fact-check guidelines. Google emphasized already at that time that only publishers recognized algorithmically as authoritative sources of information would be eligible for inclusion. In 2017, Bing also started to feature on its SERP the fact check label for articles containing the ClaimReview markup.

Here is how the fact check label looks like now on Bing.
2019: Google’s Fact-Checked Articles: A Significant Reach and New Tools
The ClaimReview markup starts to gain traction. As of late 2019, Google served over 11 million fact-checked articles per day, as highlighted on SEJ. This considerable content volume, including global search results and Google News in five countries, translates to approximately 4 billion impressions annually. Google’s efforts in this direction, already in 2019, resulted in the creation of a publicly available search tool (the Fact Check Explorer) containing a database of over 40,000 fact checks. This tool became a significant resource for users seeking verified information. Along with the Fact Check Explorer, Google introduces the Markup Tool to let publishers add the claim even without adding the markup to their pages.

Here is an example of a claim made by Express Legal Funding that appears in the Fact Check Explorer.
2021: One Page, One Claim. Google’s Eligibility Criteria for Fact-Check Rich Results
In July 2021, as spotted by Roger Montti on SEJ at that time, Google updated the eligibility criteria for pages to qualify for fact-check rich results using ClaimReview structured data. This change represented a fundamental shift in how Google displays fact checks in search results. As more data becomes available, Google’s commitment to clarity and simplicity impacts the eligibility criteria for the rich results. Previously, Google allowed multiple fact checks on a single page, meaning a webpage could cover multiple fact checks on different topics.
Following the updated guideline, to be eligible for the fact check rich result, a page must only have one ClaimReview element. A page with multiple ClaimReview elements will no longer qualify for the rich result feature. The only exception is when the webpage hosts multiple fact-checks about the same topic from different reviewers. Also, in the same year, Google introduced support for MediaReview, a new taxonomy being developed by the fact-checking community to highlight if a video or image has been manipulated (more information on What is MediaReview).

The Fact-Check label on Google Image Search.
2022: Google introduces the Fact Check Tool API and continues investing in Fact-Checking
The new API tool allows users and developers to query the same Fact Check results via the Fact Check Explorer. You can call this API continuously to get the latest updates on a particular query or claim.
More importantly, as YouTube fact-check panels begin to appear, both Google and YouTube commit $13.2 million to the International Fact-Checking Network for the Global Fact Check Fund to fight misinformation. Fact-checking becomes available on:
- Google Search (and GSE),
- Google News,
- Google Image Search, and
- YouTube search results.
The “About this results” was introduced in late 2022 as an additional feature part of the same initiative to help users evaluate the context and helpfulness of a website.
2023: Fact-Checking Becomes Multimodal
In August 2023, Google introduced a beta version of its Image Search feature for approved testers. This feature allowed users to search for fact-checks related to a specific image. This advancement represented a significant step in Google’s efforts to combat misinformation, particularly in visual content. Google now also provides context and a timeline for images on the web, showing when they were first indexed by Google and the associated topics. We start to see (also on Google’s front-end interfaces) the interaction between topics and entities in the Knowledge Graph and fact-checking claims.

The entity Donald Trump is associated with a ClaimReview (and no, Michael Moore doesn’t support Trump’s 2024 election campaign).
Also, in 2023, Google added support for the ‘About this image’ feature to learn more about an image and its veracity. As part of the same update, the Fact Explorer becomes capable of displaying ClaimReview data behind image URLs.
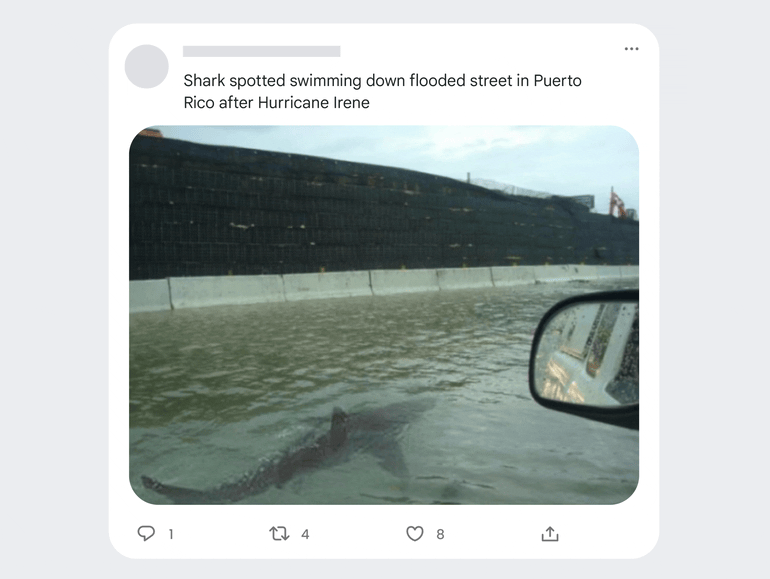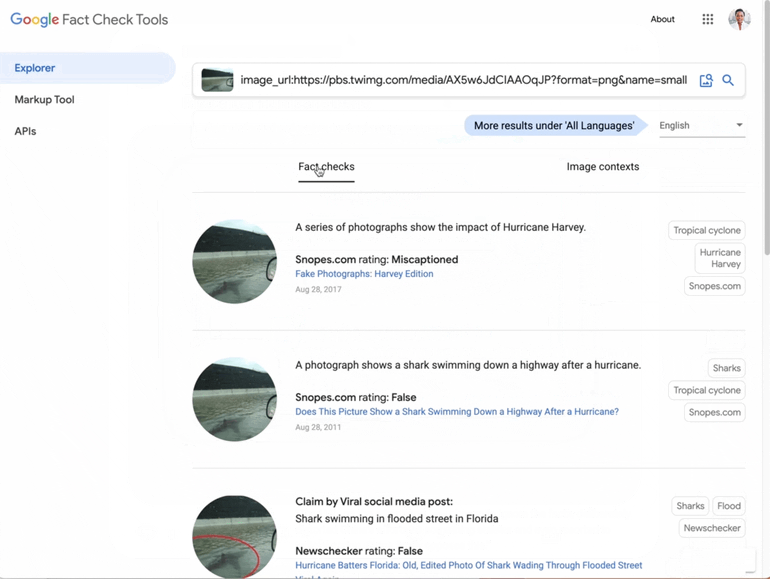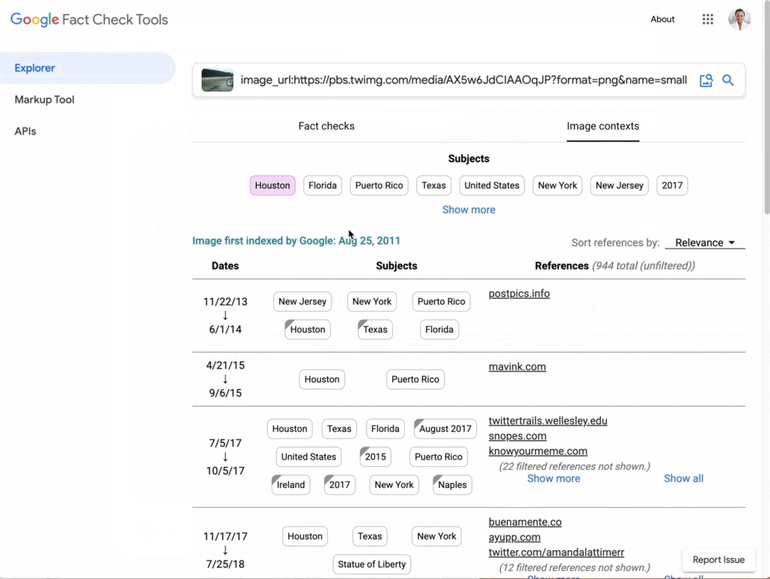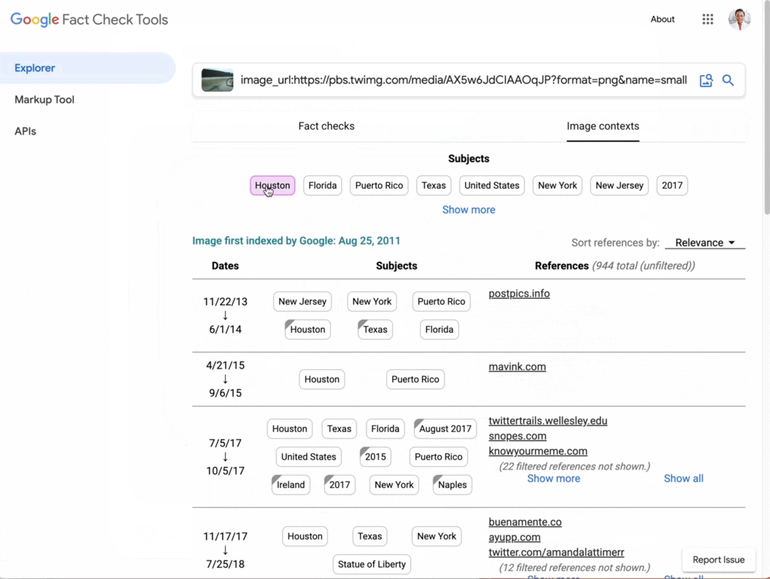
Fact-checking in Google Search Generative Experience (SGE)
These new features have also been introduced as an integral part of Google’s SGE. We read on Google’s Blog about fact-checking images:
“For people who are opted-into Search Generative Experience (SGE) through Search Labs, you’ll now be able to see AI-generated descriptions of some sources, supported by information on high-quality sites that talk about that website. We’ll showcase links to these sites in the AI-generated description of the source.
These AI-generated descriptions of the source will show up in the “more about this page” section of About this result for some sources where there isn’t an existing overview from Wikipedia or the Google Knowledge Graph.”

Here, above is the SGE expansion on a Fact Check article. The article acts as the primary source for the Claim Review along with another piece from the same publisher.
ClaimReview Markup Explained
The markup allows us to share the review of a claim made by others. The key properties, based on Google’s guidelines, are:
- claimReviewed: This is the core of the ClaimReview markup. It concisely describes the claim being evaluated. For example, a statement like “Beatrice Gamba is the Head of Innovation at WordLift.” (Big news by the way and congratulations to Bea and her team!).
- Claim: It is the factually-oriented claim that could be the itemReviewed in a ClaimReview. The content of a claim can be summarized with the text property. Variations on well-known claims can have their common identity indicated via sameAs links and summarized with a name. It needs to be unambiguous.
- itemReviewed: This property describes the manifestation of the claim (evidence where the Claim being reviewed appeared). It usually has its own set of nested properties:
- @type: Typically “CreativeWork” such as a news article or blog post.
- url: The url of the item reviewed.
- author: The person or organization making the claim
- reviewRating: This property evaluates the claim. It includes several sub-properties:
- @type: Always set to “Rating”.
- ratingValue: A numerical score given to the claim, for example, “4”.
- bestRating and worstRating: These define the rating scale (e.g., 1 to 5).
- alternateName: A textual representation of the rating, such as “True,” “False,” or “Partially True”.
- author: The entity responsible for the fact check. It usually has sub-properties like:
- @type: Often “Organization” or “Person”.
- name: The name of the organization or person conducting the fact check.
- datePublished: The date when the fact-checking article or report was published.
- url: The URL of the fact-checking article or report.
Here is an example of how we can now automatically fact-check a claim such as “Beatrice Gamba is the Head of Innovation at WordLift.” using WordLift API (or directly Agent WordLift). The API will return the following snippet:
{
"@context": "http://schema.org",
"@type": "ClaimReview",
"claimReviewed": "Beatrice Gamba is the Head of Innovation at WordLift",
"author": {
"@type": "Organization",
"name": "WordLift"
},
"datePublished": "2024-01-15",
"reviewRating": {
"@type": "Rating",
"ratingValue": "4",
"alternateName": "Mostly true",
"bestRating": "5",
"worstRating": "1"
},
"url": "https://fact-check.wordlift.io/review/beatrice-gamba-title",
"reviewBody": "Based on multiple sources, Beatrice Gamba does indeed work at WordLift. Her title is shown to be Head of Agency or SEO strategist in most records. However, one source stated her title as Head of Innovation. Therefore, the statement 'Beatrice Gamba is the Head of Innovation at WordLift' is mostly accurate, but her exact title may vary.",
"itemReviewed": {
"@type": "CreativeWork",
"url": [
"https://wordlift.io/blog/en/entity/beatrice-gamba/",
"https://it.linkedin.com/in/beatrice-g",
"https://wordlift.io/entity/beatrice-gamba/",
"https://theorg.com/org/wordlift/org-chart/beatrice-gamba",
"https://www.knowledgegraph.tech/speakers/beatrice-gamba/"
]
}
}You can review it directly on the Rich Result Testing tool here. Because when the check was done, the news was still fresh and only propagated on WordLift’s website, the statement appears to be “Mostly True,” as highlighted in the reviewBody above.

If you are interested in the original definition of the markup, I suggest reading Dan Brickley’s original description of the key concepts behind fact-checking on the schema.org GitHub.
Fact Check Eligibility Criteria
Here is how the rich results look like on the SERP of Google when the ClaimReview markup is correctly applied and indexed.

ClaimReview Rich Result on Google Search.
When the intent is specific this might trigger (as in the example below) a feature snippet.

Interestingly enough we do expect premium visibility on Google Search Generative Experience. Here the page containing the claim from our client is presented as a primary source of information in the generative response associated with the Fact-Check.

What steps should we take to be featured? What are the essential requirements for eligibility to appear on Google’s ClaimReview rich result? Here is a brief summary of the criteria.
Structured Data Requirements
- Your site must have multiple pages marked with ClaimReview structured data.
- Structured data must accurately reflect the content on the page (e.g., both structured data and content should agree on whether a claim is true or false).
Content and Website Standards
- Compliance with standards for accountability, transparency, readability, and avoiding site misrepresentation as per Google News General Guidelines.
- Presence of a corrections policy or a mechanism for users to report errors.
- Political entities such as campaigns, parties, or elected officials are not eligible for this feature.
- Clear identification of claims and checks in the article body, making it easy for readers to understand what was checked and the conclusions reached.
- The specific claim being assessed must be clearly attributed to a distinct origin (e.g., another website, public statement, social media) separate from your website.
- Fact check analysis must be transparent and traceable, with citations and references to primary sources.
Technical Guidelines
- A page is eligible for a single fact check rich result and must contain only one ClaimReview element.
- The page hosting ClaimReview must include at least a brief summary of the fact check and its evaluation, if not the full text.
- A specific ClaimReview must only appear on one page of your site. Do not duplicate the same fact check on multiple pages, except for variations of the same page (e.g., mobile and desktop versions).
- If aggregating fact-check articles, ensure all articles meet these criteria and provide an open, publicly available list of all fact-check websites you aggregate.
Structuring Claims in a Knowledge Graph
In examples like this one, in the context of linked data and knowledge graphs, we can also reference Beatrice Gamba in a more subject-oriented way, which can be particularly useful if the fact check is directly related to her as a person or her role. We do this by leveraging the schema:about property. We also use the ‘@id’ property as a way to uniquely identify Beatrice (the entity of a Person) within JSON-LD structured data. It helps to specify the unique identifier of an entity, providing a clear reference to an external resource or a node in the knowledge graph.

Here is the markup now with the addition of the schema:about property and here is how it renders on the Google Structured Data Testing Tool:
{
"@context": "http://schema.org",
"@type": "ClaimReview",
"claimReviewed": "Beatrice Gamba is the Head of Innovation at WordLift",
"author": {
"@type": "Organization",
"name": "WordLift"
},
"datePublished": "2024-01-15",
"reviewRating": {
"@type": "Rating",
"ratingValue": "4",
"alternateName": "Mostly true",
"bestRating": "5",
"worstRating": "1"
},
"url": "https://fact-check.wordlift.io/review/beatrice-gamba-title",
"about": {
"@type": "Person",
"@id": "http://data.wordlift.io/wl0216/entity/b-23977",
"name": "Beatrice Gamba" },
"reviewBody": "Based on multiple sources, Beatrice Gamba does indeed work at WordLift. Her title is shown to be Head of Agency or SEO strategist in most records. However, one source stated her title as Head of Innovation. Therefore, the statement 'Beatrice Gamba is the Head of Innovation at WordLift' is mostly accurate, but her exact title may vary.",
"itemReviewed": {
"@type": "CreativeWork",
"url": [
"https://wordlift.io/blog/en/entity/beatrice-gamba/",
"https://it.linkedin.com/in/beatrice-g",
"https://wordlift.io/entity/beatrice-gamba/",
"https://theorg.com/org/wordlift/org-chart/beatrice-gamba",
"https://www.knowledgegraph.tech/speakers/beatrice-gamba/"
]
}
}
Adding the “about” property in ClaimReview markup, especially when combined with an “@id” attribute that links to a unique entity in a knowledge graph, can significantly enhance the capabilities of data querying and retrieval, particularly with technologies like GraphQL. We can, for example, give an entity (whether is a Person, an Organization, or a Product), and collect with a single query all the available ClaimReview.
Fact-Checking for E-commerce Websites
Fact-checking, while prominently used in the context of news and information, is not limited to these areas alone, and it can also be applied to products. This is particularly relevant when building Product Knowledge Graphs. We can foresee value on multiple sides:
- Products often come with various claims regarding their effectiveness, ingredients, environmental impact, health benefits, and more. Fact-checking these claims can be a crucial approach to ensure that they are accurate and not misleading to the consumers.
- Conversely, there are instances where media reports about products may contain misleading information with limited substantiation. In such cases, fact-checking becomes essential to validate the veracity of these media claims.
AI Fact-Checking for Product Descriptions
At WordLift, while seeding product data for creating Product Knowledge Graphs, we’re using fact-checking to verify the accuracy of product descriptions and specifications listed on our clients’ e-commerce platforms. Here are a couple of practical examples:
| Image | Product Description | Claim | AI Fact-Checking |
|---|---|---|---|
 | Ready for all those travel adventures you have planned? Don’t forget to pack a pair of Gucci shoes. Crafted from ECONYL® – a nylon fabric made with recycled yarn – this GG Supreme canvas pair not only adds style to your journey but also lets you extend environmentally friendly practices to your travels. Step forward with your best foot in these Italian-made shoes. | Women’s Gucci Off The Grid sneaker uses recycled materials. | { “@context”: “http://schema.org”, “@type”: “ClaimReview”, “claimReviewed”: “Women’s Gucci Off The Grid sneaker is made from recycled materials”, “author”: { “@type”: “Organization”, “name”: “WordLift” }, “datePublished”: “2024-01-18”, “reviewRating”: { “@type”: “Rating”, “ratingValue”: “5”, “alternateName”: “True”, “bestRating”: “5”, “worstRating”: “1” }, “url”: “https://fact-check.wordlift.io/review/womens-gucci-off-the-grid-sneaker-recycled-materials”, “reviewBody”: “Gucci has indeed launched a product line called ‘Off The Grid’ which includes the Women’s Gucci Off The Grid sneaker, and it is promoted as being made from recycled materials. This is confirmed by multiple reliable sources. The company states that the product line uses recycled, organic, bio-based, and sustainably sourced materials.”, “itemReviewed”: { “@type”: “CreativeWork”, “url”: [ “https://wwd.com/feature/gucci-launches-off-the-grid-sustainable-collection-1203652671/#!”, “https://www.gucci.com/us/en/st/capsule/circular-line-off-the-grid”, “https://the-ethos.co/gucci-sustainable-run-sneakers/”, “https://www.gucci.com/us/en/st/stories/article/off-the-grid-collection-shoppable”, “https://www.elle.com/fashion/a33014463/gucci-off-the-grid-sustainable-collection/” ] } } |
| Image | Product Description | Claim | AI Fact-Checking |
|---|---|---|---|
 | Un fond de teint tenue 16 heures boosté par le pouvoir de l’éclat, qui conjugue couvrance moyenne à intense et fini naturel. Longue tenue rime avec légèreté. Haute couvrance et résultat ultra-naturel. Sa formule respirante et résistante est infusée aux extraits de framboise, de pomme et de pastèque pour aider à lisser et améliorer l’apparence de la peau instantanément et au fil du temps, et révéler un teint éblouissant de luminosité. Elle tient mieux, plus longtemps, et offre un résultat toujours plus beau à mesure que les heures passent. La technologie spéciale « accord parfait » vous assure une nuance au plus proche de votre carnation. | NARS Natural Radiant Longwear Foundation Mali contient des extraits de framboise, de pomme et de pastèque. | { “@context”: “http://schema.org”, “@type”: “ClaimReview”, “claimReviewed”: “NARS Natural Radiant Longwear Foundation Mali ingredients”, “author”: { “@type”: “Organization”, “name”: “WordLift” }, “datePublished”: “2024-01-19”, “reviewRating”: { “@type”: “Rating”, “ratingValue”: “5”, “alternateName”: “True”, “bestRating”: “5”, “worstRating”: “1” }, “url”: “https://fact-check.wordlift.io/review/nars-natural-radiant-longwear-foundation-mali-ingredients”, “reviewBody”: “The ingredients of NARS Natural Radiant Longwear Foundation in the shade Mali include Dimethicone Crosspolymer, Bis-Butyldimethicone, Polyglyceryl-3, Stearic Acid, among others. It is indeed a liquid foundation with a natural finish and full coverage. Thus, the claim about its ingredients is correct”, “itemReviewed”: { “@type”: “CreativeWork”, “url”: [ “https://www.narscosmetics.com/USA/natural-radiant-longwear-foundation/999NAC0000065.html”, “https://www.temptalia.com/product/nars-natural-radiant-longwear-foundation/mali/”, “https://incidecoder.com/products/nars-natural-radiant-longwear-foundation”, “https://www.narscosmetics.co.uk/en/mali-natural-radiant-longwear-foundation/0607845066323.html”, “https://www.skincarisma.com/products/nars/natural-radiant-longwear-foundation/ingredient_list” ] } } |
We use AI to analyze product information on an attribute-by-attribute level and create a single source of truth for our clients’ organizations. This allows them to control any Generative AI workflow (product description, chatbots, content recommendations and more).
Semi-Automating Fact-Checking with an AI agent [code available]
In this section I will share the code to set up your own AI Agent for fact-checking 🎉 . This section is for Python developers only (sorry), feel free to jump right at the end of it to read the conclusions or stick with me to understand the workflow.

Here is the flow in the Colab but for the SPARQL/GRAPHQL tool.
The code creates an AI agent for fact-checking, leveraging OpenAI’s function calling. The notebook begins by installing essential libraries such as llama-index (I love LlamaIndex), llama-hub, and tavily-python (this is an interesting gem for this type of project), which are integral in building the pagent’s capabilities. You will need:
- An OpenAI key
- A Tavily-API key (here)
Following this, it imports various modules necessary for JSON data handling, defining types, and interacting with OpenAI’s API, among other functionalities. This setup is crucial for the agent to process and verify information efficiently.
The agent is designed to receive queries in the form of claims, process them, and return fact-checked information.

By using advanced LLM models, the agent can analyze text data, cross-reference information with reliable sources, and provide validated answers. We are planning to extend the capabilities of the Agent by accessing (when available) to data inside the knowledge base. We can chain another tool and run a SPARQL query on the RDF graph to bring first-party information into the evaluation process.

Epistemology, Ethics, and SEO
Epistemology, the philosophical study of knowledge, intersects with SEO in the quest for understanding and optimizing the acquisition and dissemination of information on the web.
When doing SEO, we streamline the workflow of a search engine to increase the visibility of a content piece; by doing so, we’re acting on what people see and understand of the World. Ethically, we want to choose where and how to direct our powers. We want to keep things balanced and society as healthy as possible. Fact-checking powered by AI assists in the pursuit of truth and understanding. It can also limit the use of bad marketing techniques and the publishing of low-quality content.
As professionals in the Search Engine Optimization (SEO) field, we are always adapting to the changing landscape of information. We focus on understanding the context and relationships between entities in the real world. ClaimReview, especially when associated with entities, helps search engines determine the truthfulness of information. We can also use fact-checking to assess the accuracy of statements we promote.
In the example above about Beatrice becoming Head of Innovation at WordLift, we can see how this methodology helps us review the extent to which Google has perceived this change in its top search results.
Consider another scenario: with the increase in AI-generated content, it becomes imperative to bolster our infrastructure to evaluate the truthfulness of such information. Many may recall the incident following the debut of Google’s Bard through a promotional video, which resulted in a staggering $100 billion market value loss for Google. This drop occurred after researchers on Twitter pointed out that Bard had disseminated incorrect information, claiming that the James Webb Space Telescope (JWST) was the first to photograph an exoplanet. Here’s how Agent WordLift, an AI SEO Agent, can identify the erroneous statement about the JWST that tripped up Bard.

Agent WordLift (AI SEO Agent) and its new ability to do fact-checking. We can now validate claims and reduce the risk of hallucinations.
Conclusions And Future Research Work
The landscape of fact-checking is rapidly changing with the advent of AI and the proliferation of misinformation. The need for robust, scalable, and reliable fact-checking methods is more crucial than ever in journalism and across various digital platforms.

Agent WordLift (AI SEO Agent) is in action with fact-checking.
Fact-checking is not just about ascertaining truth; it’s increasingly intertwined with SEO. The credibility and authority of content (E-E-A-T), vital for SEO success, can be enhanced through meticulous fact-checking in various ways. Google and Bing continue investing in fact-checking tools and structured data to improve the quality of information presented in search results across multiple platforms like Google Search, Google News, Google Images, Google Generative Search Experience, and YouTube.
AI plays a crucial role in automating and improving the accuracy of fact-checking processes, and its applications extend to other areas such as SEO, where autonomous AI agents are beginning to make an impact.
With the help of AI Agents like the one presented in this article, we can structure claims in knowledge graphs to bolster content integrity and improve SEO.
On the technical side I envisage the future evolutions of our tooling in this area as follows:
- Firstly, enhancing the versatility of linking ClaimReviews to entities is a pivotal challenge. This involves refining how our tools identify and associate claims with relevant entities in a more dynamic and context-aware manner.
- Secondly, there’s a need for more sophisticated mechanisms to determine the trustworthiness of websites. This requires restricting and evaluating the list of sources when analyzing information.
- Another critical aspect is the integration of data from Knowledge Graphs. Our agent should be adept at extracting and comparing this data with web search results, enabling a more comprehensive and accurate verification process.
- Lastly, the aspect of multimodality cannot be overlooked. The ability to validate along with text, images, and other media files is essential in a digital landscape increasingly dominated by diverse content formats.
Let’s raise the open web standards together and make the information in our knowledge graphs more trustworthy!
References
- A better ClaimReview to grow a global fact-check database By Sanha Lim – April 18, 2019
- How Google’s Fact Check Tools and SERP Features Work by Carter Puntur – April 4, 2023
- Fact Check Schema Helps To Build Online Credibility by Jeannie Hill – updated July, 2023
- Fact Check Structured Data – Google Guide
- Google Fact Check Tools
- Fact Check Structured Data on Bing
- The Epistemology of Fact Checking – October 2013 Joseph by E. Uscinski &Ryden W. Butler
- Introduction to ClaimReview: The hidden infrastructure of fact checks – International Fact-Checking Network [YouTube Video]
- Download Fact Check Data created with the Google Fact Check Markup Tool – Datacommons.org