Semantic Markup In SEO: Html5, Structured Data And Beyond With AI Power
Semantic markup is crucial for structuring webpage data. Let's see all the semantic markup available and a new approach to semantic publishing.

Table of contents:
- What is Semantic Markup?
- Semantic markup HTML
- Microdata for HTML5
- From Microdata to JSON/LD
- The power of Knowledge Graphs
- Entity Markup with the power of AI
- Why is semantic markup so important for SEO?
- How to Take Semantic Markup a Step Further
What is Semantic Markup?
With the advent of the concept of Web 3.0, it is becoming increasingly important to create web pages that have meaning beyond the codes that make them up, that search engines can understand. Semantic markup can serve this purpose. Semantic markup in modern SEO is the process of adding semantic value to the content of a web page. We know two groups of semantic markup: semantic HTML tags and structured data.
Semantic markup HTML
Let’s start with HTML, a markup language used to create a hierarchical structure of a web document. Many of the HTML tags we know are naturally associated with this language. For example, the <ul> markup and the nested <li> tags are elements that compose the paragraph’s form and content; the <p> tag represents the grammatical concept of a paragraph; <h1>, <h2>, <h3>, and <h4> tags are the titling of a text according to a hierarchical order of importance.
The semantic HTML elements are one of the first approaches to structuring a web page’s information. The semantic HTML markup differs from the tags used for the sole purpose of graphical modeling through the use of CSS (<div>, <ul>, <li>, <b>, <span>, etc.) but adds new descriptive elements of some areas of a web page. Thus was born the latest version of HTML, HTML5, which introduces several tags with a semantic purpose, such as <section>, <article>, <aside>, <header>, <footer>, etc., each with a meaning and a role of markup. To understand the difference between a generic <div> and a <section>, the W3C, the World Wide Web Consortium founded by Tim Berners-Lee, explains that:
“The section element is not a generic container element. When an element is needed for styling purposes or as a convenience for scripting, authors are encouraged to use the div element instead.“(…)”The section element represents a generic section of a document or application. A section, in this context, is a thematic grouping of content, typically with a heading.“
World Wide Web Consortium
Let’s see the most common semantic HTML tags and their meaning.

Microdata for HTML5
Defining the role of some areas of a web page is not enough to structure the information so that it is understandable to the search engine. Instead, it is necessary to use a markup that can convey the same linguistic understanding as a human. To achieve this, HTML5 introduces the ability to add Microdata, a speaking attribute that can be added to a regular HTML tag.
Microdata is organized into groups of items declared via the itemcope attribute assigned to an HTML tag. The itemtype attribute can specify a data vocabulary, which is a dictionary that defines terms for types of things, properties, and relationships. To add a property to an item, there is the itemprop attribute. Let’s see an example of using the Schema.org vocabulary to structure the information of a breadcrumb:
<ol itemscope itemtype="https://schema.org/BreadcrumbList">
<li itemprop="itemListElement" itemscope
itemtype="https://schema.org/ListItem">
<a itemprop="item" href="https://example.com/shoes">
<span itemprop="name"> Shoes </span> </a>
<meta itemprop="position" content="1"/>
</li>
<li itemprop="itemListElement" itemscope itemtype="https://schema.org/ListItem ">
<a itemprop="item" href ="https://example.com/shoes/sneaker ">
<span itemprop="name"> Sneaker </span> </a>
<meta itemprop="position" content="2"/>
</li>
</ol>Let’s see an example using Schema.org vocabulary to describe a company.
<div itemscope itemtype="https://schema.org/Organization">
<span itemprop="name"> WordLift </span>
<img src="logo.jpg" itemprop="logo" alt ="Wordlift's logo" />
WordLift's home page:
<a href="https://wordlift.io" itemprop="url">wordlift.io </a>
</div>Microdata is a markup system for HTML code that uses a data vocabulary that contains all the rules of the properties of an object. In the last example, we saw a semantic HTML markup of the type “organization”, whose properties are organized hierarchically and expressed by a key-value pair understandable by a search engine:
- Type = Organization;
- Name = WordLift;
- Logo = https://wordlift.io/logo.jpg
- Url = https://wordlift.io
From Microdata to JSON/LD
Although semantic markup with microdata represents a clear step forward in structuring information, it has several disadvantages for maintenance and updates of the code. The attribute markup is a weak construct due to the dependence on an HTML tag. The evolution of semantic markup is the JSON/LD annotation (still reported by Google as a best practice for structuring data). JSON/LD can be defined as a headless system that works independently of DOM’s <body> because it develops independent <script> tags inserted in the <head> tag of the document. Microdata can still be mixed with the JSON/LD annotation.
NOTE: JSON/LD markup, according to Google directives, always needs a counter-proof of the information within the content visible on the page.
The Power Of Knowledge Graphs
In recent years, search engines have developed an accurate archive of related concepts called knowledge graphs. These huge relational archives are organized with a graph structure of entities (nodes) and relationships between entities (arcs). The nodes in a knowledge graph represent real-world entities such as people, companies, cities, events, etc., and the arcs represent the relationships between the nodes, i.e., the relationships between different entities.
The most important knowledge graph for SEO is Google’s knowledge graph. Thanks to the entities contained within his Knowledge Graph, Google can answer factual questions such as “When was Tom Cruise born?”, “How long is the Chinese wall?”, “When was America discovered?” or “How old is the CEO of Meta?”.
The Knowledge Graph information comes from various sources collecting factual data, public databases, and information in Google Knowledge Panels. Another example of a semantic network is WordNet, one of the most popular lexical databases for the English language, which is often used for NLP frameworks. Other important public knowledge graphs are:
- DBpedia takes advantage of the Wikipedia infobox structure to create a large data set. Often used to improve the performance of NLP and search applications;
- Geonames a database with over 25 million geographical entities: states, regions, cities, municipalities, places of interest such as villas, monuments, etc.
In summary, knowledge graphs help us organize content into interrelated concepts and objects into known entities through a shared vocabulary. Search engines can consult entities to better understand our expertise and mastery of content, and thus provide more relevant search results to users.
Entity Markup with the power of AI
We have analyzed how it is possible to structure the information of a web document by using languages that machines can understand. This task has always involved the manual injection of JSON/LD, an approach that is not scalable and requires constant human intervention. Thanks to new machine learning and artificial intelligence technologies, it is now possible to automate a large part of the semantic markup process.
How To Implement Semantic Markup Using WordLift
WordLift is an AI-powered SEO tool to automate the semantic markup process. Its technology captures, marks, and integrates structured data into any website by reading and analyzing the content of your page.
WordLift can organize entities in 4 categories: Who, What, When and Where, and with its AI, builds a customized Knowledge Graph for businesses with entities marked by different topics, categories, and regions. You can accept the entities suggested adding contextual info for the user, efficiently selecting internal links for your content.
WordLift is the perfect assistant for semantic publishing because it also helps to beautify your structured data with specific properties and valuable content. For instance, events can be displayed chronologically by adding the Timeline widget, Locations in your article can quickly be mapped by adding the Geomap widget, and with the Navigator feature, you can display relevant articles to your readers obtaining better user engagement. Those are only a few features that come built-in with WordLift.
By using WordLift, search engines can understand the structure of your content faster and more accurately and avoid ambiguities. This way you’ll get more organic traffic and user activity on your website, leading to more conversions and leaving your competition behind.
Why Is Semantic Markup So Important For SEO?
Semantic markup makes it possible to structure the information on the page and make it understandable for search engines. This activity is crucial for SEO for three main reasons:
- Improvement of the E.AT. (Expertise, Authoritativeness and Trustworthiness) thanks to the sending of relational signals (SameAs attribute, memberOf, isPartOf, etc.)
- Improvement of the appearance of search results thanks to rich snippets in SERP that improve CTR performance (FAQ, HowTo, Reviews, etc.)
- Consolidate the data within the Google Knowledge Graph (also called the data reconciliation process).
How to Take Semantic Markup a Step Further
So far, we have seen the process of structuring web page data with a self-referencing approach. In a competitive system like SERPs, it is necessary to change the perspective from the inside to the outside and understand how to improve the structuring of the data compared to the competitors that are dealing with our topic.
Questions such as “What entities have our competitors mentioned?”, “Are there entities that expand the horizon of my content?”, and “What relationships have I not considered?”. We have entered the age of semantic publishing, which is now a fact. In a webinar with Max Geraci, SEO Expert, he used his application Entities’ Swiss Knife to perform an example of entity gap analysis. Let’s us take a look at how it’s done in a few steps.
First, connect to the web application and fill in the URL field within the target web page you wish to analyze.
Then select the following option for data extraction:
- Check the first option to extract entities only from the relevant HTML tags;
- Check the second option to process a content analysis with SpaCy, an open-source software library for advanced natural language processing;
- Check the third option below to extract categories and topics according to the media topics taxonomies developed by IPCT;
- Check the last option to scrape all the entity’s descriptions from Wikipedia.

Now you should see an interesting output: all the entities mentioned within the content, categories and topics covered and the content audit with SpaCy. All this information can be used in your content to drive more value and to fill the entity gap between your content and competitor’s content. Below there’s an example of WordLift’s blog post on schema markup for Local SEO.

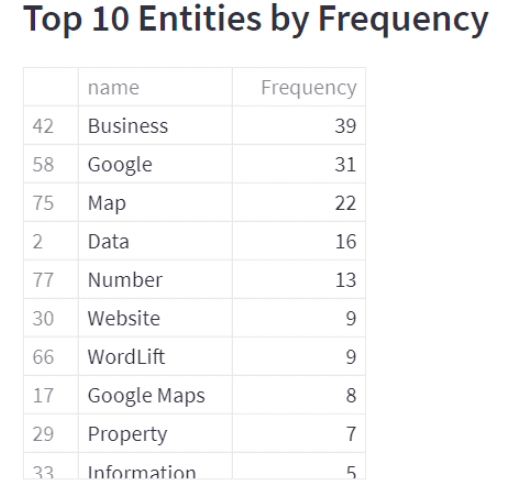
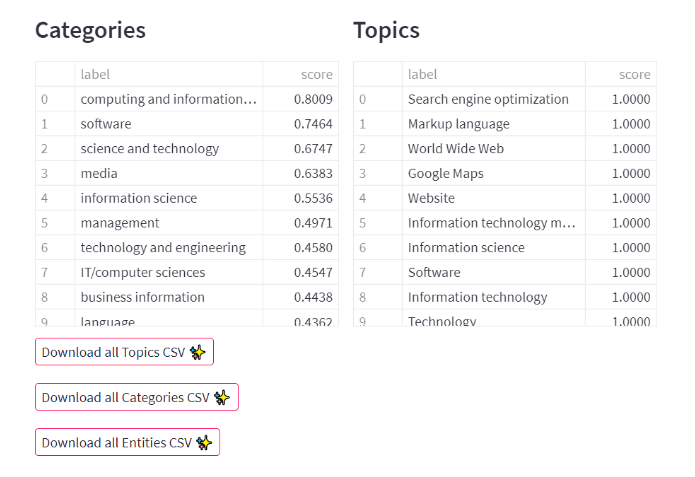
How To Properly Use The About And Mentions Properties
We already saw how to extract entities from a competitor’s page, but how do we use those entities to enrich our content? Let’s spend some words on two properties crucial for the SEO entity gap strategy: the about and mention property.
We correctly use the about property when we refer to one or two entities for us the main topic of our content. The entity included in the above property should be inserted in the relevant HTML semantic tags or at least in the <h1> (the main header) and metatags such as the title tag.
The mention property is also crucial because it describes all the subtopics we touch on in our content. The ideal number of mentioned entities is 3-5 per article, and it strictly depends on the article’s length. For long articles, it is not strange to see five mentioned entities in the property value. The mention property must be used only when we explicitly refer to the entity in a significant portion of our content.
To know more about the semantic publishing, watch the webinar Entity-based SEO: Semantic Publishing and Entities Gap Analysis with Max Geraci or check out his presentation here👇