
Our ancestors in the Savannah developed larger and larger brains that allowed them to communicate effectively.
Whether language came as side effect of larger brains or it was actually our ability to communicate that made our brain larger, the main point is, humans, strive for clarity!
One of the most powerful way humans use to deepen their understanding of the world is by asking questions.
In an interview to one of the greatest scientists of our times, Richard Feynman, he was explaining how magnetism worked, when the journalist suddenly asked,
Referring to why magnets attract each other.
That seemingly simple question made Feynman flinch for a few seconds.
Not because the question was naive. Quite the opposite, it was so powerful that it knocked him down.
In other words, when we ask questions, we want an answer that is clear and straight to the point.
Although scientific answers are complex by nature.
Simple questions, such as “who is the president of the United States?” are simple and require a direct answer.
Yet it has not been the way the web worked so far.
Why? Because machines did not understand human language.
Therefore, in order to make the content on your blog findable, you had to adjust it so that machines could index it.
Things are changing quite fast, though. Machines’ ability to understand human language has improved remarkably.
How? Thanks to natural language processing (NLP).
Why is that relevant to your blog? Let’s see…
How Google works in a nutshell
As Matt Cutts, engineer at Google, explains, when you do a search on Google, “you are not searching the web but Google’s index of it“.
In short, software programs called spiders crawl the web, trying to make sense of what they find, and index few pages out of billions of pages to answer your Google searches.
Deciding whether a page is relevant, therefore it needs to be indexed is not an easy task.
As Matt Cutts explains, those “little spiders” try to answer more than two-hundred questions, such as:
How many times does this page contain your keyword?
Do they appear in the title? Do they appear in the URL?
This list of questions goes on and on, until Google finally delivers a result in less than a second!
But if the exact formula Google uses to index web pages is as secret as Coca-Cola’s recipe – meaning that we all talk about it but none really knows what’s in it – a revolution happened.
The Hummingbird that changed the net
In September 2013 a new search platform – Hummingbird – came out.
Within this search platform, a new algorithm, called RankBrain became a major player.
Out of the more than 200 hundreds factors that Google accounts for when deciding whether the content on your blog is relevant RankBrain has become the third-most important signal contributing to the result of a search query.
But let’s take a short step back to see how it works!
A word is not an island
If I pick two random nouns, such as “Socrates” and “Plato” in your mind you are already building a set of relationships.
Chances are you already thought that Socrates was Plato’s teacher. Also that Socrates is an ancient greek philosopher. We cannot help it!
Why? Because humans think in terms of relationships among concepts.
Yet that is not what machines used to do. Until RankBrain changed it all!
RankBrain looks more at the relationship between concepts and words rather than a single word or keyword.
The machine learning algorithm learns to understand what you write based on contextual information and the network of concepts it meets along the way.
In short, a word is not an island, but it gets relevance based on the context it sits on.
The Power of context
As SEO strategist Gianluca Fiorelli puts it in RankBrain unleashed:
“What we should do is insist on optimizing our content using semantic SEO practices (emphasis mine), in order to help Google understand the context of our content and the meaning behind the concepts and entities we are writing about.“
To make your content relevant it is crucial to have a change of paradigm.
Keywords are not enough. What can you do? Let’s find out!
How to make machines understand the classics
Athens 399 B.C.: a chubby man, with a long white beard was standing in front of a jury. We are in Athens, the most developed city at the time. Yet that man was ready to be sentenced to death.
He was not afraid, and although he was in a risky situation he spoke his mind until the last instant. That man was Socrates, and that trial is portrayed in Plato’s “Apology of Socrates”.
Even though this is the most moving trial ever told, Google wasn’t able to understand it before Hummingbird unleashed RankBrain!
Indeed, if you were to use the classic approach to SEO, you would stuff your article with keywords (like you would do with a Thanksgiving’s turkey) hoping that one day Google understood it!
For how crazy that sounds, it is what many experts would do! But isn’t there a better way? Yes, that is!
For instance, that is what Wikipedia says about the “Apology of Socrates”:
“The Apology of Socrates, by Plato, is the Socratic dialogue that presents the speech of legal self-defence, which Socrates presented at his trial for impiety and corruption, in 399 BC.
Specifically the Apology of Socrates is a defense against the charges of “corrupting the young” and “not believing in the gods in whom the city believes, but in other daimonia that are novel” to Athens.”
As a human, this text is pretty straightforward. Yet to make it comprehended by machines we have to take an additional step.
Google finally meets Socrates
I took Wikipedia’s text and edited it with WordLift and that is what I got:
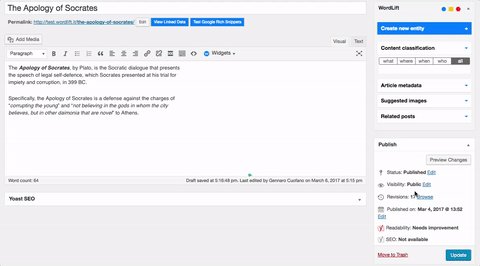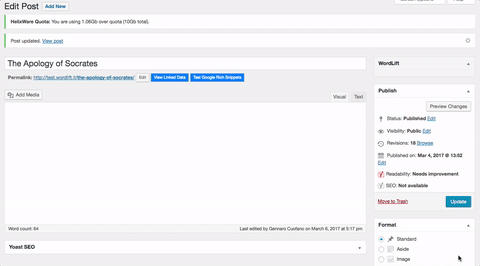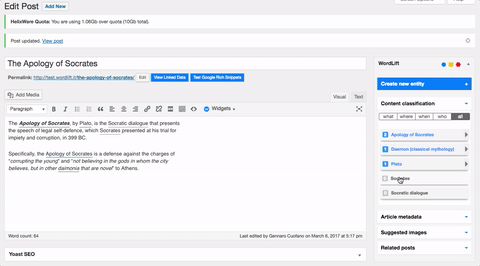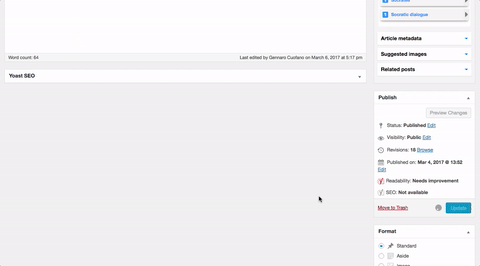
First, as soon as I placed the text in my WordPress editor and saved it as a draft, WordLift started to analyze it semantically. In short, WordLift understood what I wrote thanks to NLP.
Second, on the right side, WordLift classified the content of my post under the “What, where, when and who” and extracted the relevant entities. What is an entity? An entity is a page that is structured semantically, thus understood not only by humans but also by search engines.
Third, WordLift suggested a set of entities (such as Apology, Classical Athens, Daemon, Plato, Socrates and Socratic Dialogue) that would help me to tell the story both to humans and machines.
With a click, I selected the entities classified by WordLift and saved the article. WordLift marked my content through schema.org, and made it readable to machines!
How do I know?
Within my editor WordLift makes available a box, that says “View Linked Data”.
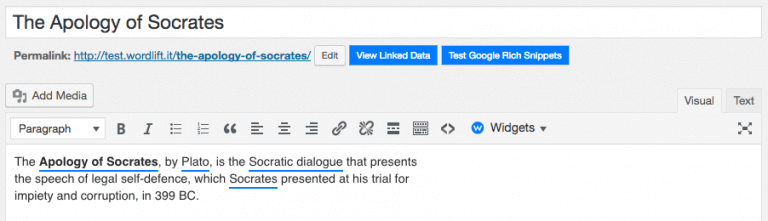
Once I click on it, and take an additional step I can see how the information I placed in my editor is reshaped until it became organized knowledge.

In short, the information I wrote in the article was reshaped and organized in a set of nodes and edges. Where the nodes are the articles and entities. While the edges are the relationships between those articles and entities.
Why is that relevant?
That knowledge is now accessible to both humans (in the form of text) and machines (in the form of schema.org markup).
In other words, without placing a single keyword in my post I managed to explain the “Apology of Socrates” to my new friend, Google!
The only caveat is to structure your content by creating Entities rather than keywords!
The Evolution of SEO: from keyword to Entity
Throughout this article, we saw a few very interesting points.
First, humans use questions to communicate. Yet we expect answers that are clear and straightforward. Paradoxically, though, that is not the way the web worked until recently.
Second, machines didn’t understand human language. Yet a revolution happened in 2013, when Hummingbird unleashed RankBrain.
Third, now thanks to semantic web, humans and machines are on the same page. Yet to take advantage of this revolution, you have to stop thinking about keywords and start creating Entities!
Do you want to create your first entity? Get in touch with me!
Book your free live demo session now!