How We Got To Linked Data in SEO
How we got to the Linked Data in SEO and why you need to build a Knowledge Graph side-by-side with your website to stand out in search results.

Knowledge Graphs exist for a long time, yet most of the solutions in the SEO market deal marginally with them, probably because it may be difficult to explain them and even more to manage them in the SEO context.
In this article, I will try to give a bit of background information and clearly explain why you need to build a Knowledge Graph side-by-side with your Web Site and why they matter SEO.
What is a Knowledge Graph in SEO?
First of all, a short definition of a Knowledge Graph by IBM:
“A knowledge graph, also known as a semantic network, represents a network of real-world entities—i.e. objects, events, situations, or concepts—and illustrates the relationship between them.”
To summarize even further a Knowledge Graph defines real-world concepts such as people, organizations, places, events, etc., and how they relate to each other.
This is an example of the graph for “Arnold Schwarzenegger”:
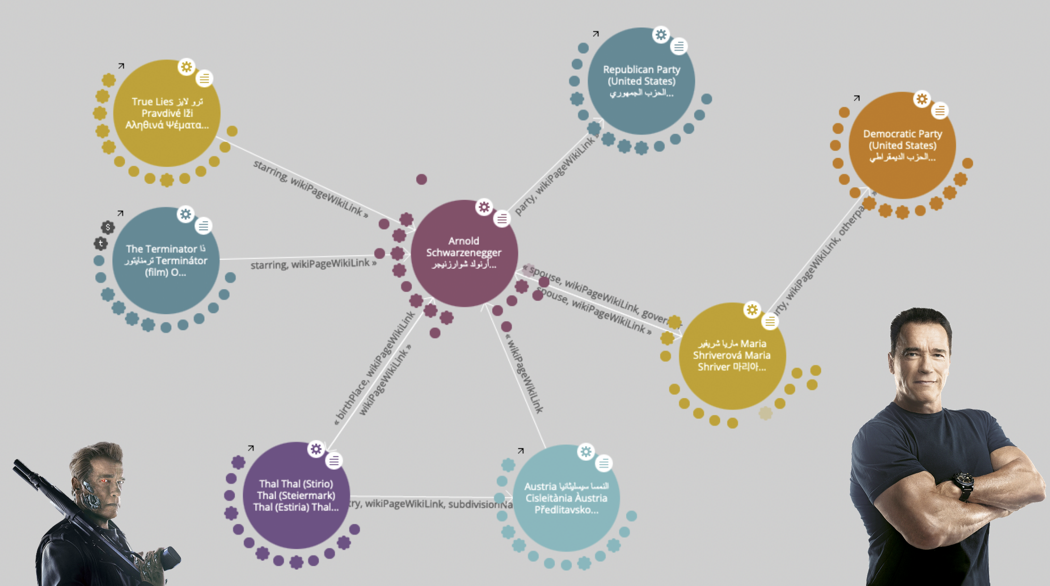
In this graph you can see at the center the Person entity representing Arnold Schwarzenegger and its connections for example to the movie The Terminator, this is how Google can understand that The Terminator is Arnold Schwarzenegger. We can also see the birthplace of Thal located in Austria and so forth.
Is Google indexing the whole web?
This is a visual representation of the Web AD 1996:

We could count the total number of pages equivalent to roughly 26 million pages.
This is the Web in 2013, almost 10 years, ago:

There are more than 30 trillion pages, so many that it’s actually impossible to count them anymore, in fact, Google stopped counting them already in 2008 as they admitted in a public post:
“We don’t index every one of those trillion pages — many of them are similar to each other, or represent auto-generated content“
Google, 2008
If you were under the impression that Google was indexing the whole Web, well now you know, it gave up 15 years ago.
How to stand out in search results?
Let’s take a step further: a year later in 2009, Tim Berners Lee, the creator of the Web, gave a speed at TED and he said:
“They’re much more than […] initial website that we started off with. Now, I want you to put your data on the web. Turns out that there is still huge unlocked potential.“
Tim Berners-Lee at TED 2009
He also gave us a 5 stars system to score our data:

- Data should be on the Web of course.
- It should be readable by machines, not interpreted by humans.
- It should use non proprietary formats (prefer CSV instead of Excel).
- Better yet make use of formats that can describe reality using sentences, e.g. JSON-LD.
- But the most important of all, data must have a unique permanent URL that can be used to reference other data or to be referenced from other data, for example this is our unique and permanent id on DBpedia: http://dbpedia.org/resource/WordLift and on Wikidata: http://www.wikidata.org/entity/Q31998763.
What is schema.org?
2 years later, in 2011, schema.org is born as a joint initiative of Google, Microsoft, and Yahoo (and later on Yandex) to define a common shared vocabulary to describe entities and with the specific aim to “improve query results relevance” (schema.org presentation, 2011).
In fact, the schema.org FAQ elaborates more on that explaining that “when search engines see more of the markup they need, users will end up with better search results” and that “schema.org helps you to surface your content more clearly or more prominently in search results” (schema.org FAQ).
So let’s glue the pieces together:
- The web is way to big to be fully indexed.
- Tim Berners Lee is telling us to put our data on the web to unlock the full potential of the Web.
- The major search engines created a shared vocabulary with the clear intent of improving the search relevance.
If you want to know more about structured data and how to implement it on your website, read the article.
Why I need a Knowledge Graph in SEO?
Just a few months after schema.org was created, Amit Singhal, at the time SVP of Engineering at Google shared an important post that changed the game: Introducing the Knowledge Graph: things, not strings.
And he said, and I quote:
“Take a query like [taj mahal]. For more than four decades, search has essentially been about matching keywords to queries. To a search engine, the words [taj mahal] have been just that—two words.”
“But we all know that [taj mahal] has a much richer meaning. You might think of one of the world’s most beautiful monuments, or a Grammy Award-winning musician, or possibly even a casino in Atlantic City, NJ.”
“The Knowledge Graph enables you to search for things, people or places […] This is a critical first step towards building the next generation of search, which taps into the collective intelligence of the web and understands the world a bit more like people do.”

In conclusion, Knowledge Graphs help us organize our content through a shared vocabulary into concepts and things interconnected together to well-known entities that search engines can consume to better understand what is our competence and content domain, thus delivering more relevant search results to end-users.
Learn more about why you need a Knowledge Graph and what it brings to SEO, content marketing, read our article.