
Page Speed is the unquestionable strength of Accelerated Mobile Pages. This factor gives these pages an incredible boost in mobile SEO and in CTR. What can you do to further optimize your AMP pages? Here is where structured data in the form of schema.org markup comes into play.
Before we go deep into why structured data can be a not-so-obvious way to boost your AMP pages, let’s answer a simple question: what are Accelerated Mobile Pages and why are they so important?
AMP: the open-source library that speeds up your mobile pages
Launched by Google in 2015, AMP is an open-source library that allows developers to create web pages that load almost instantaneously on mobile browsers. In other words, speed is a crucial factor that AMP aims to optimize.
To understand why the speed factor is so important nowadays – especially after Google rolled out its mobile-first index – you have to think about how users are browsing the web and, therefore, how Google is trying to offer them a better search experience.
In 2018, mobile search has taken the lead over desktop search: 67% of worldwide visits are performed using mobile devices according to Stone Temple.
What do mobile users want? Speed!
Yep, it is as simple as that. 53% of mobile users leave a page after 3 seconds of loading. Does that sound exaggerated? Think about yourself, looking for a piece of information or news for a quick read and waiting in front of your tiny smartphone display for seconds that feel like minutes.
#AMP & #PageSpeed What do mobile users want? Speed! 53% of mobile users leave a page after 3 seconds of loading! Click To TweetI think you already know that frustrating feeling. In fact, 75% of mobile websites take 10 or more seconds to load.
By giving AMP pages a place of honor on its SERPs, Google is trying to guarantee its users a better search experience.
By implementing AMP on your website, you can:
- Overcome your mobile speed issues
- Give a better user experience to your readers
- Incentivize Google to show your pages first instead of the slow-loading pages of the majority of your competitors
- Your website will be eligible for visual stories, and rich result features, such as image, logo or headline, for instance
- Website might be able to be shown in mobile Search results as rich results
- See your news featured in the top news carousel, if you are a news publisher

To prove why implementing AMP on your website is important, here are some basic figures taken from research conducted by TechJury in 2019 on mobile vs Desktop use. The numbers clearly indicate that mobile market share worldwide is 52.1% in comparison to desktop market share of 44.2%. What is not surprising is that Millennials spend about 3 hours and 45 minutes browsing on their mobile devices per day in 2019. It is highly unlikely that the number will decrease in 2020.
Here is another similar research by AMP Project, and it indicates that E-commerce websites which are using AMP, experienced a 20% increase in sales conversions compared to non-AMP pages. Still doubting whether you need to implement AMP?
Canonical page or native AMP?
To avoid duplicate content issues, Google requires each AMP page to be linked to its canonical non-AMP version, and the canonical page has to link back to the AMP page.
Here is the code that does the trick
In the AMP page you should place:
<link rel="canonical" href="https://www.example.com/url/to/full/document.html">
In the canonical page you should place:
<link rel="amphtml" href="https://www.example.com/url/to/amp/document.html">
In case the page is native-AMP, meaning that there isn’t another page for desktop devices, the canonical should be the AMP page itself. This could become a smart option in the future for websites whose traffic and business model is mostly mobile based.
#AMP A native-AMP website could become a smart option in the next future for those websites whose traffic and business model is mostly mobile-focused. Click To TweetWhy adding structured data to AMP pages can make the difference
Adding schema.org markup to AMP is recommended by Google itself. In their guide of how to enhance AMP for Google Search, they begin with:
You can enhance your AMP content for Google Search by creating a basic AMP page, adding structured data, monitoring your pages, and practicing with codelabs.
And later in the same article:
Use structured data to enhance the appearance of your page in Google mobile search results. AMP pages with structured data can appear in rich results in mobile search, like the Top stories carousel or host carousel.
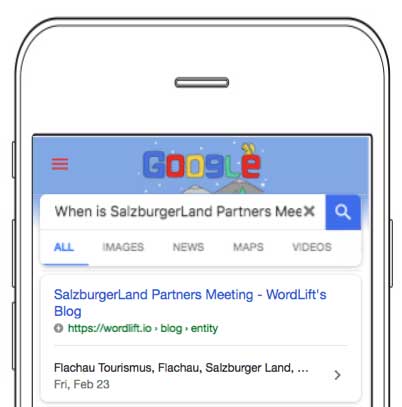
What exactly does “enhance the appearance of your page in Google mobile search” mean? As you can see in the example below, the page of SalzburgerLand Partners Meeting on WordLift Blog is an entity of the Event type. Below the link, you can see that Google features some basic metadata such as place and date. This gives users extra information and adds one more reason for them to click on the content.
The same thing can be done with different types of entities: for example, imagine products coming with their price and availability information.
How to add structured data to your AMP pages
Google Search recommends to use the same structured data markup for both the canonical and the AMP pages:
Use the same structured data markup across both the canonical and AMP pages.
This means that if you want to benefit from semantic SEO techniques on your AMP pages, you have to align the structured data of your AMP version to the canonical page. If you have invested some time with the schema.org markup of your content, it would be a shame not doing so!
AMP Project suggests to include in the structured data of your AMP at least these four schema.org properties to make your AMP pages more easy to find:
- the specific type of content (i.e. ‘news article’)
- the headline
- the published date
- associated preview images.
Of course, the richer your structured data is, the more that Google Search will understand the content on your page and be able to help you reach the right target audience. If you are not sure if the structured data parses correctly, you can use these tools to test structured data.
The more your #StructuredData is rich, the more Google Search will understand the content on your page and help you reach the right target audience. #SchemaOrg Click To TweetIf you are using WordPress, you may already know that thanks to the plugin AMP for WordPress you can turn any of your pages or articles into an AMP page.
There are many other plugins that do the same thing, but we recommend you to chose this exact one because it comes from the first strict cooperation between Google and WordPress. In fact, the Google AMP team is the same team that is working to empower the WordPress ecosystem. One of the first results of this cooperation is the AMP for WordPress plugin created by Automatic, our friends at XWP (a leading WP developing agency) and Google itself. Here some some cool new updates that your website can benefit from:
- Gutenberg Support
- Divi Support
- AMP Stories
- Improved CSS Optimization
- Google Fonts Support For All Designs
- AMP Infinite Scroll Support
- Photo Gallery by 10Web Support
- MEWE social network Support
From now on with WordLift, your AMP pages can finally inherit the schema.org markup of the canonical page and share the same JSON-LD. Simply put, after you add the structured data to your article, WordLift will automatically implement all the metadata in the corresponding AMP pages.
Using our plugin, structured data for AMP is quite simple. Have a look at this schema.org markup of an AMP post on the blog of our sister company InsideOut Today.

Wrapping up: the benefits of structured data on AMP pages
Using the same markup for AMP pages and canonical pages, you will benefit from the advantages of a mobile-optimized page – since Google index is more and more focused on mobile performances – and also from the extra help of semantic SEO. Boom! You can kill two birds with one stone.
As we have seen before, AMP speeds up a website’s load time and therefore it increases mobile ranking, which affects the CTR. Users are more likely to click on the results that are more prominent on the SERP.
Wait, there’s more! A fast loading page will also have a lower bounce rate. Here the advantage is twofold: your users will benefit from a better UX and search engines will register the high dwell time as a positive signal – helping you to strengthen your website rankings.
#AMP speeds up a website load time. This means: better rankings, higher CTR and lower bounce rate. Boom! Click To TweetOn the other side, enriching your AMP pages with structured data will help search engines better understand your content and also give them enough metadata to display your pages as rich snippets on the SERP. Guess what? This will guarantee you even a higher CTR.