How To Create Content Hubs Using Your Knowledge Graph
Content marketing is about creating compelling content that responds well to searchers’ intents and it’s essential for any inbound marketing strategy. In this article we will explore how knowledge graph embeddings can help us create content hubs that works for SEO.

Content marketing is about creating compelling content that responds well to searchers’ intents and it’s essential for any inbound marketing strategy.
The level of competition varies by sector, but it is in general extremely fierce. Just consider the following numbers to get an idea. There are around 500 million active blogs worldwide and, in 2021, according to Internetlivestats.com, we’re publishing over 7 million blog posts every day! These are astonishing numbers, and yet, we can still conquer the competition on broader queries. These queries, in our ultra-small niche, would be something like “structured data”, “linked data” or “semantic SEO”. To succeed in going after these broader search intents, we need to organize our content in topically relevant hubs.
In layman’s terms, we can define topically relevant content as a group of assets (blog posts, webinars, podcasts, faqs) that cover in-depth a specific area of expertise. In reality, though, there are various challenges in compiling this list:
- we want to identify all the themes and subthemes related to a given concept;
- we want to do it by using the various formats that we use (content from our academy, blog posts, and ideally content that we might have published elsewhere);
- we need to keep in mind different personas (the SEO agency, the in-house SEO teams of a large corporation, the bloggers, etc.).
In this article, I will share how you can build content hubs by leveraging deep learning and data in a knowledge graph. We will use specifically a technique called knowledge graph embeddings (or simply KGE). This is an approach to transform the nodes and edges (entities and relationships) in a low dimensional vector space that fully preserves the knowledge graph’s structure.
 Here is the link to the Colab that will generate the embeddings.
Here is the link to the Colab that will generate the embeddings.
 Here is the link to the TensorFlow Projector to visualize the embeddings.
Here is the link to the TensorFlow Projector to visualize the embeddings.
Let’s first review a few concepts together to make sure we’re on the same page.
- What is a content hub?
- What is a knowledge graph in SEO?
- What are knowledge graph embeddings (KGE)?
- Let’s build the knowledge graph embeddings
- How to create a content hub
- Conclusion
What Is A Content Hub?
A content hub is where you want your audience to land after triggering a search engine’s broad search query. A content hub is presented to the user either as a long-form article or as a compact category page (Content Harmony here has a nice list of various types of content hubs). In both cases, it needs to cover the core aspects of that topic.
The content being presented is not limited to what we have on our site but should ideally include assets that have been already developed elsewhere, the contributions of relevant influencers, and everything we have that can be helpful for our audience.
Experts and influencers in the given subject’s field have a strategic role in establishing the required E-A-T (Expertise, Authoritativeness, and Trustworthiness) for each cluster.
What Is A Knowledge Graph In Seo?
A knowledge graph is a graph-shaped database made of facts: a knowledge graph for SEO describes the content that we produce so that search engines can better understand it.
Our Dataset: The Knowledge Graph Of This Blog
In today’s experiment, we will use the Knowledge Graph behind this blog to help us create the content hubs. You can use any knowledge graph as long as it describes the content of your website (using RDF/XML or even a plain simple CSV).
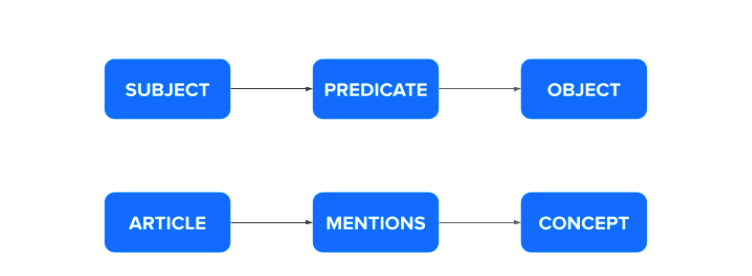
In most essential terms, a graph built using WordLift connects articles with relevant concepts using semantic annotations.
There is more, of course, some entities that can be connected to each other with typed relationships; for example, a person (i.e. Jason Barnard) can be affiliated with an organization (Kalicube) and so on depending on the underlying content model used to describe the content of the site.
Here below, we see a quick snapshot of the classes that we have in our dataset.
What Are Knowledge Graph Embeddings (KGE)?
Graph embeddings convert entities and relationships in a knowledge graph to numerical vectors and are ideal for “fuzzy” matches. Imagine graph embeddings as the fastest way to make decisions using the Knowledge Graph of your website. Graph embeddings are also helpful to unveil hidden patterns in our content and cluster content into groups and subgroups.

Deep learning and knowledge graphs are in general complex and not easy to be visualized, but things have changed, and we can now easily visualize concepts in high-dimensional vector spaces using Google’s technologies like TensorBoard. Meanings are multi-dimensional as much as people are. The magic of embeddings lies in their ability to describe these multiple meanings in numbers so that a computer can “understand” them.
We can approach a given concept like “Semantic SEO” from so many different angles. We want to use machine learning to detect these angles and group them in terms of assets (content pieces) and entities (concepts).
Let’s watch a video to grasp more about clustering topics, as this is what we’re about to do.
Let’s Build The Knowledge Graph Embeddings
I have prepared a Colab Notebook that you can use to create the graph embeddings using a Knowledge Graph built with WordLift. We are going to use an open-source library called AmpliGraph (remember to star it on GitHub).
Feel free to play with the code and replace WordLift’s Knowledge Graph with your data. You can do this quite simply by adding the key of your subscription in the cell below.
If you do not have WordLift, remember that you can still use the code with any graph database organized in triples (subject > predicate > object).
To create the knowledge graph embeddings, we will train a model using TensorFlow. Embeddings are vector representations of concepts in a metric space.
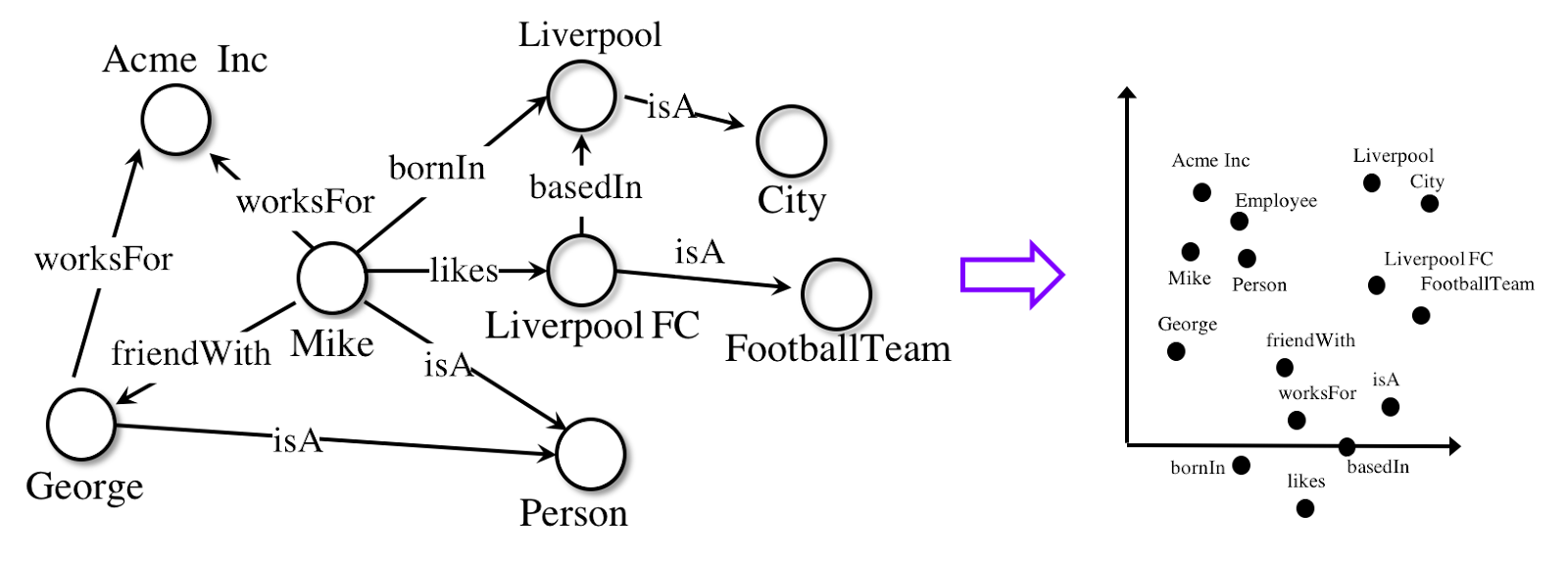
While there are various algorithms (TransE, TransR, RESCAL, DistMult, ComplEx, and RotatE) that we can use to achieve this goal, the basic idea is to minimize the loss function when analyzing true versus false statements. In other words, we want to produce a model that can assign high scores to true statements and low scores to statements that are likely to be false.
The score functions are used to train the model so that entities connected by relations are close to each other while entities that are not connected are far apart.
Our KGE has been created using ComplEx (Complex Embeddings for Simple Link Prediction); this is considered state-of-the-art for link predictions. Here are the parameters used in the configuration.

Model Evaluation
The library we’re using allows us to evaluate the model by scoring and ranking a positive element (for example, a true statement) against a list of artificially generated negatives (false statements).
AmpliGraph’s evaluate_performance function will corrupt triples (generating false statements) to check how the model is behaving.
As the data gets split between train and test (with a classical 80:20 split), we can use the test dataset to evaluate the model and fine-tune its parameters.
I have left most of the hyper-parameters untouched for the training but, I have worked, before the training, on cleaning up the data to improve the evaluation metrics. In particular, I have done two things:
- Limited the analysis to only triples that can really help us understand the relationships in our content. To give you an example, in our Knowledge Graph, we store the relationship between each page and the respective image; while helpful in other contexts, for building our content hubs, this information is unnecessary and has been removed.
- As I was loading the data, I also enabled the creation of all the inverse relationships for the predicates that I decided to use.
Here is the list of the predicates that I decided to use. As you can see, this list includes the “_reciproal” predicates that AmpliGraph creates while loading the KG in memory.
![]()
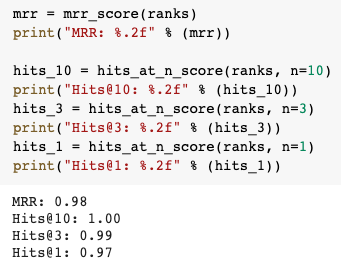
As a result of these optimizations, I was able to improve the ranking score.
How To Create A Content Hub
Now that we have the KGE, such a new powerful tool, let’s get practical and see how to use them for creating our content hubs. We will do this by auditing the content that we already have in three main steps:
- Familiziaring with the model by predicting new facts. These are previously unseen relationships that we want to rank to understand how likely they would be true. By doing that, we can immediately explore what list of concepts we could deal with for each cluster.
- Discovering sub-topics and relationships using the TensorFlow Embedding Projector. To enable a more intuitive exploration process we will use an open-source web application for interactive visualization that will help us analyze the high-dimensional data in our embeddings without without installing and running TensorFlow.
- Clustering topics. We want to audit the links in our graph and see what contents we have and how they can be grouped. The clustering happens in the embedding space of our entities and relations. In our example, we will cluster entities of a model that uses an embedding space with 150 dimensions (k=150); we will apply a clustering algorithm on the 150-dimensional space to create a bidimensional representation of the nodes.
Let’s Start Predicting New Facts
To familiarize with our model, we can make our first predictions. Here is how it works. We are going to check the likelihood that the following statements are true based on the analysis of all the links in the graph.

- semantic_seo > mentions > content_marketing
- precision_and_recall > relation_reciprocal > natural_language_processing
- andrea_volpini > affiliation > wordlift
- rankbrain > relation > hummingbird
- big_data > relation > search_engine_optimization
I am using one predicate from the schema.org vocabulary (the property mentions) and one predicate from the dublin core vocabulary (the property relation along with its reciprocal) to express a relationship between two concepts. I am also using a more specific property (affiliation from schema.org) to evaluate the connection between Andrea and WordLift.
Let’s review the results.

We can see that our model has been able to capture some interesting insights. For example, there is some probability that Big Data has to do with SEO (definitely not a strong link), a higher probability that Precision and Recall is related with Natural Language Processing, and an even higher probability that RankBrain is connected with Hummingbird. With a high degree of certainty (rank = 1), the model also realizes that Andrea Volpini is affiliated with WordLift.
Exploring Embeddings To Discover Sub-Topics And Relationships
To translate the things we understand naturally (e.g., concepts on our website) to a form that the algorithms can process, we created the KGE that captures our content’s different facets (dimensions).
We are now going to use the Embedding Projector (an open-source tool released by Google) to navigate through views of this data directly from our browser and using natural click-and-drag gestures. This will make everything more accessible and easy to use for the editorial team.
Here is the shareable link to the Projector with our KGE already loaded. We will now discover the facets around two clusters: Semantic SEO and Structured Data.
Let’s review the concept of Semantic SEO.
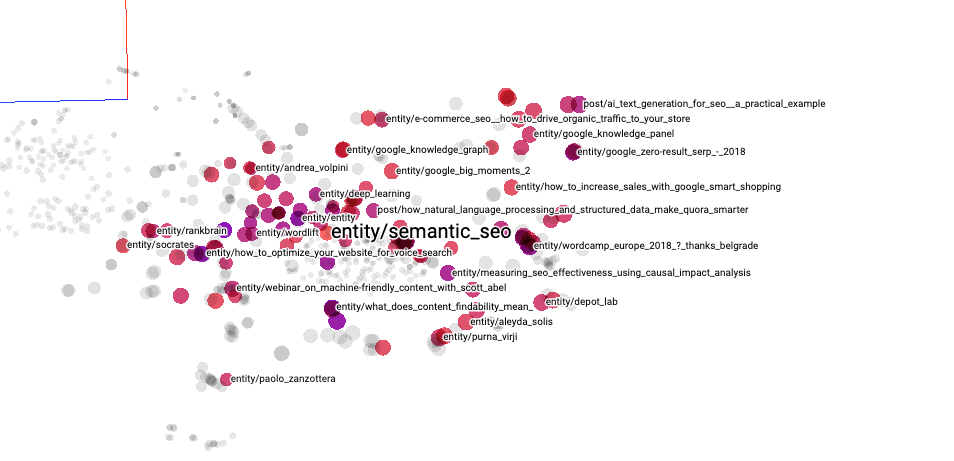
We can quickly spot few interesting connections with:
- Concepts:
- Google Zero Results SERPS
- Voice Search
- Rankbrain
- Google Knowledge Graph
- Content findability
- Google Big Moments
- …
- Influencers:
- Aleyda Solis
- Purna Virji
- Webinars:
- Machine learning friendly content with Scott Abel (one of my favourites)
- Events:
- The WordCamp Europe in 2018 in Belgrade (the talk was indeed about semantic seo and voice search)
- Blog Posts:
- How Quora uses NLP and structured data
- AI text generation (using data in a KG)
- …
Over the years, we have built a knowledge graph that we can now leverage on. We can use it to quickly find how we have covered a topic such as semantic SEO, the gaps we have when comparing our content with the competition, and our editorial point of view.
The beauty of this exploration is that the machine is revealing us years of classification work. While these embeddings have been created using machine learning, our editorial team has primarily human-curated the data in the knowledge graph.
Let’s explore Structured Data.
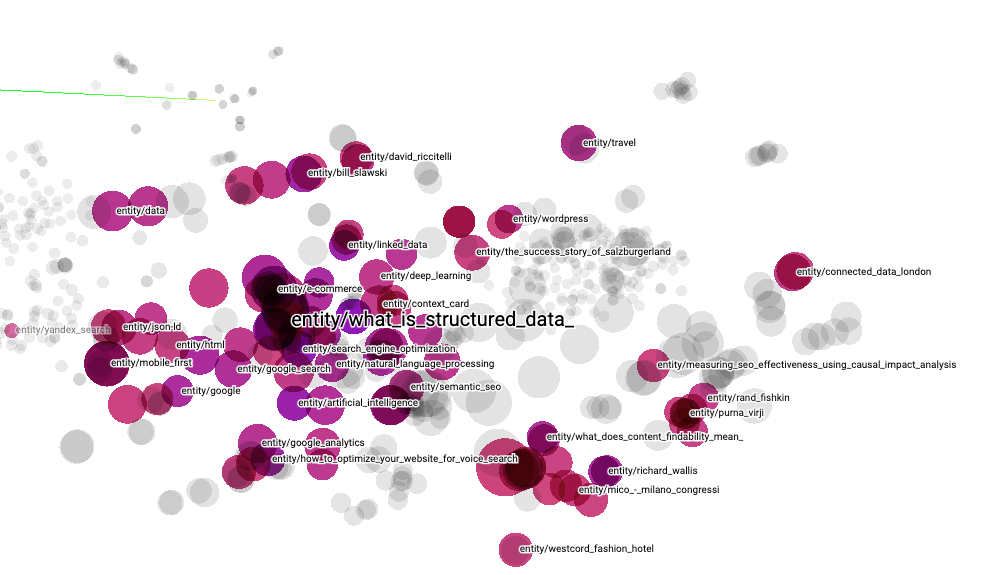
As a tool for automating structured data, this is for sure an attractive cluster. Here we can see the following at first glance:
- Concepts:
- Linked Data
- Context Card (a product feature that uses structured data)
- WordPress
- SEO
- NLP
- Google Search
- JSON-LD
- Impact measurement
- …
- Influencers:
- Bill Slawski (thanks for being part of our graph)
- Richard Wallis (for those of you who might not know, Richard is one of the greatest evangelist of schema)
- Showcase:
- The success story of Salzburger Land Tourismus
Using the slider on the right side of the screen, we can capture the most relevant connections.
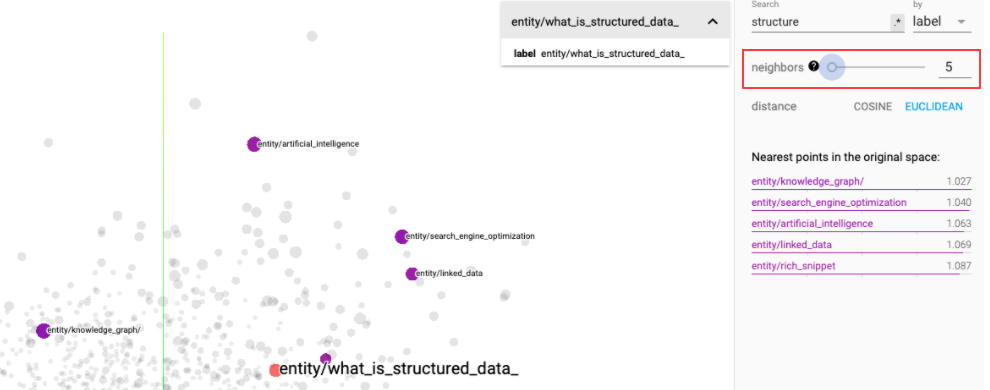
I am analyzing the semantic similarity of the nodes using the euclidean distance; this is the distance calculated between each vector in the multidimensional space. This is definitely more valuable as it provides a structure and helps us clearly understand what assets we can use in our content hubs. In our small semantic universe, we can see how the concept of Structured Data is tightly related to Linked Data, Knowledge Graph, and Wikidata.
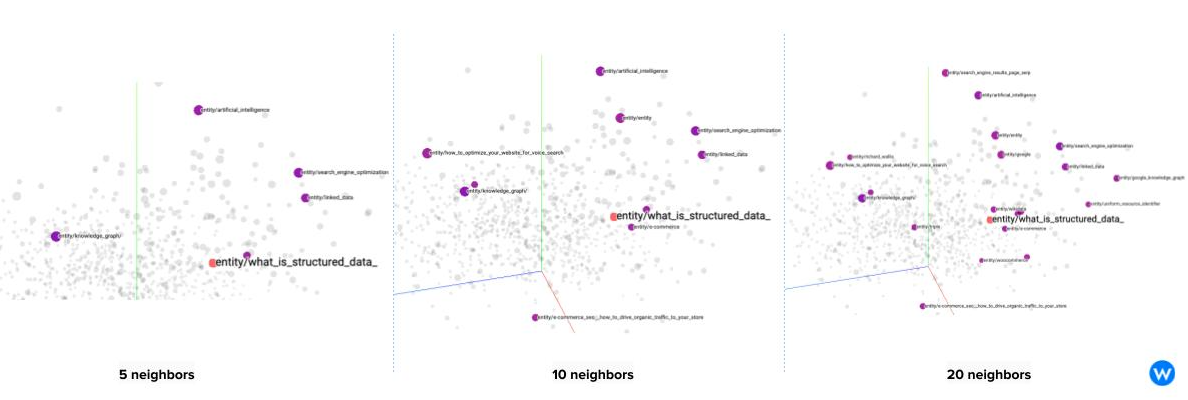
The Projector uses different dimensionality reduction algorithms (UMAP, T-SNE, PCA) to convert the high-dimensional space of the embeddings (150 dimensions in our case) down to a 2 or 3D space. We can also use a custom setting, at the bottom left corner of the screen, to create a custom map that will layout the concept around Structured Data so that we will have as an example, on the left everything that is related to e-commerce and on the right everything that has to do with web publishing. We will simply add the terms, and the Projector will reorganize the map accordingly.
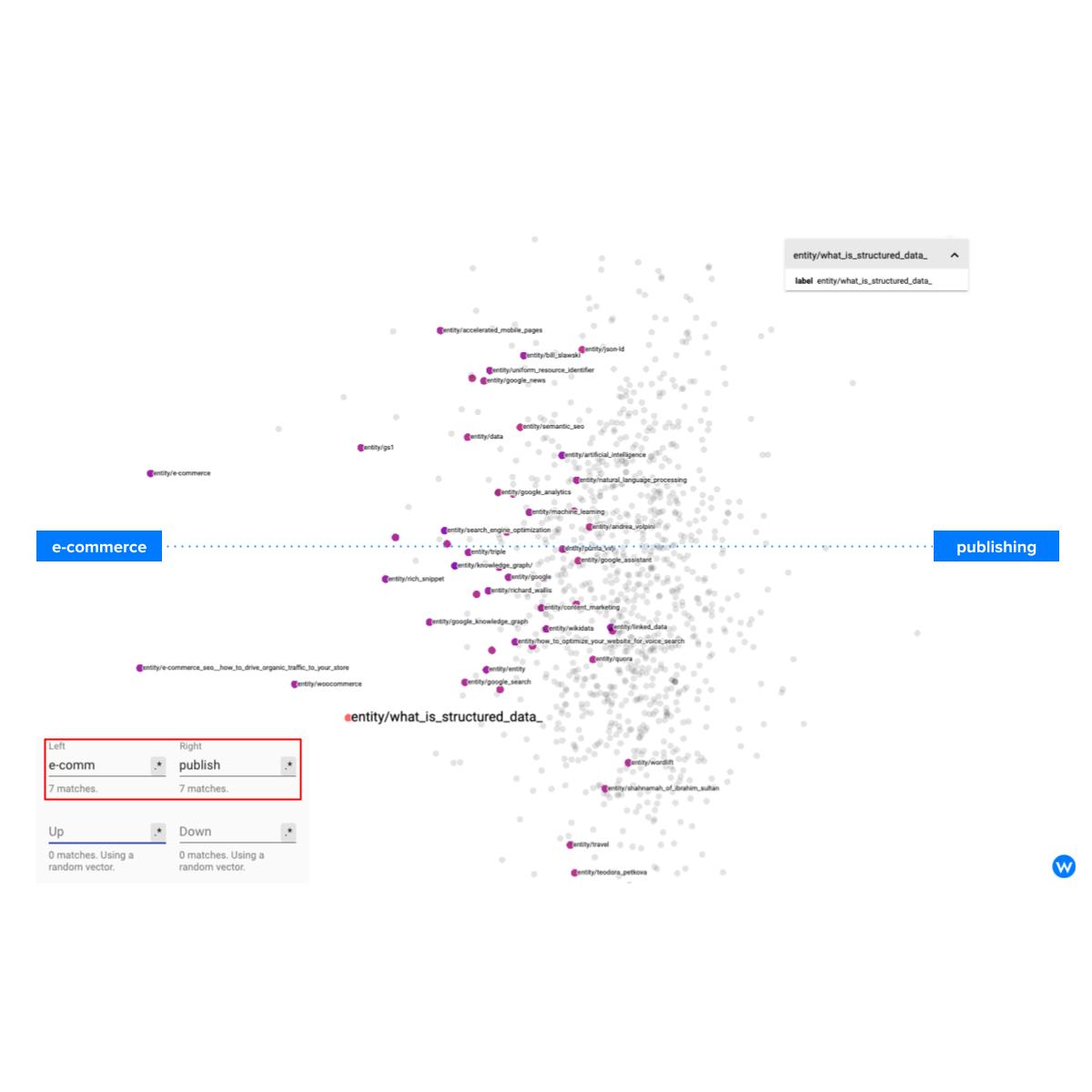
This way, we can see how “Structured Data” for E-Commerce shall include content related to WooCommerce and GS1 while content for publishers could cover broader topics like content marketing, voice search, and Google News.
Topic Clustering
We can now visualize the embeddings on a 2D space and cluster them in their original space. Using the code in the Colab notebook, we will use PCA (Principal Component Analysis) as a method to reduce the dimensionality of the embedding and K-Means for clustering.
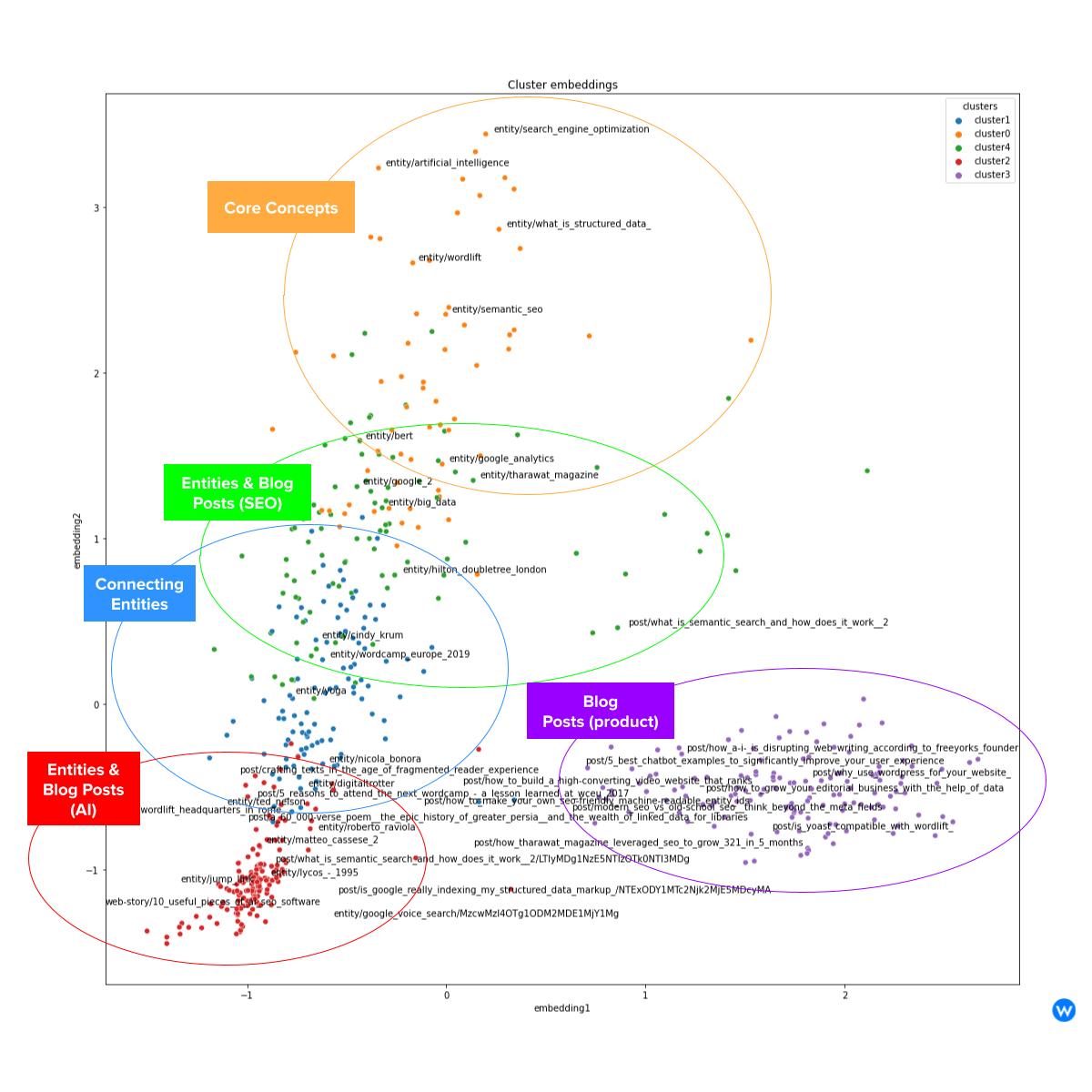
We can see five clusters: core concepts (Semantic SEO, SEO, AI, WordLift, …), entities and posts on SEO (including showcases), connecting entities (like events but also people), blog posts mainly centered on the product and content related to AI and machine learning.
We can change the number of clusters we expect to see in the code (by setting the n_cluster variable). Also, you might want to add a set of nodes that you want to inspect by adding them to the list called top10entities.
In general, it is also very practical to directly use the Projector with our KGE and the different clustering techniques for exploring content. Here below, we can see a snapshot of t-SNE, one of the methods we can use to explore our embeddings.
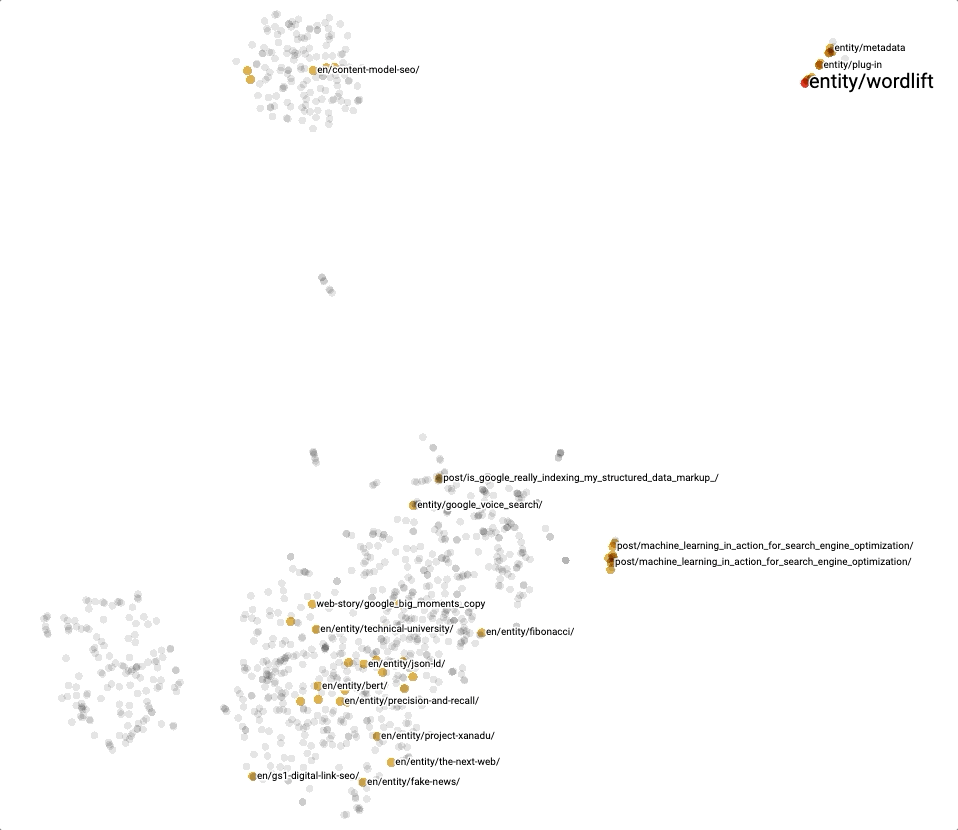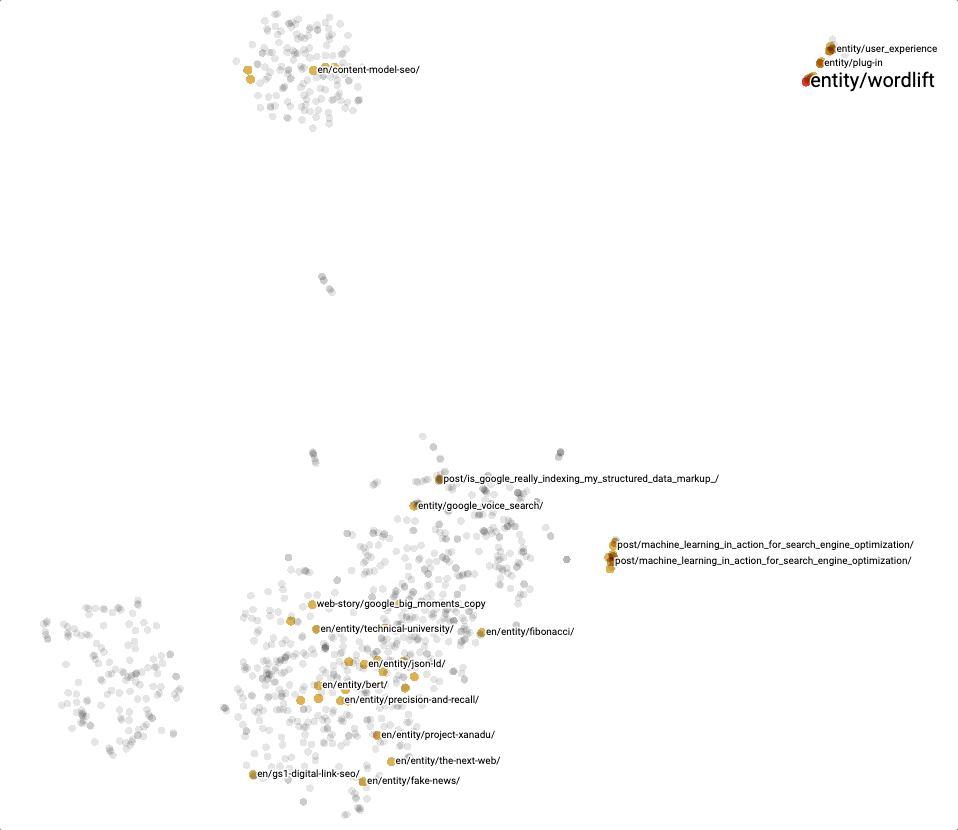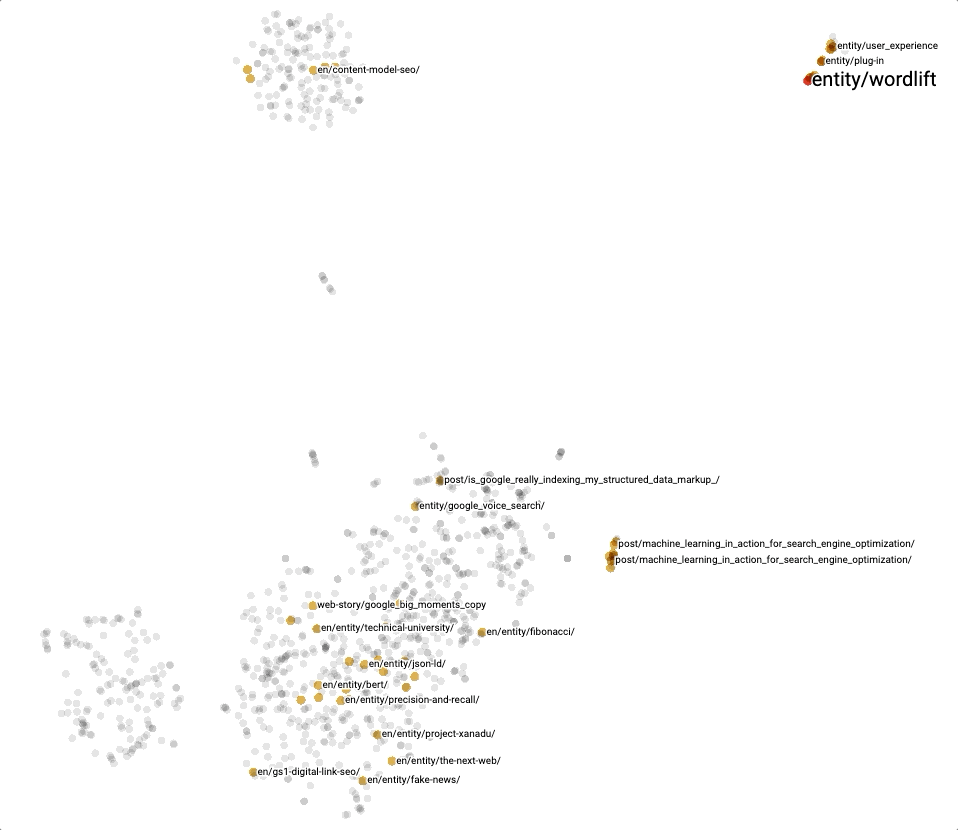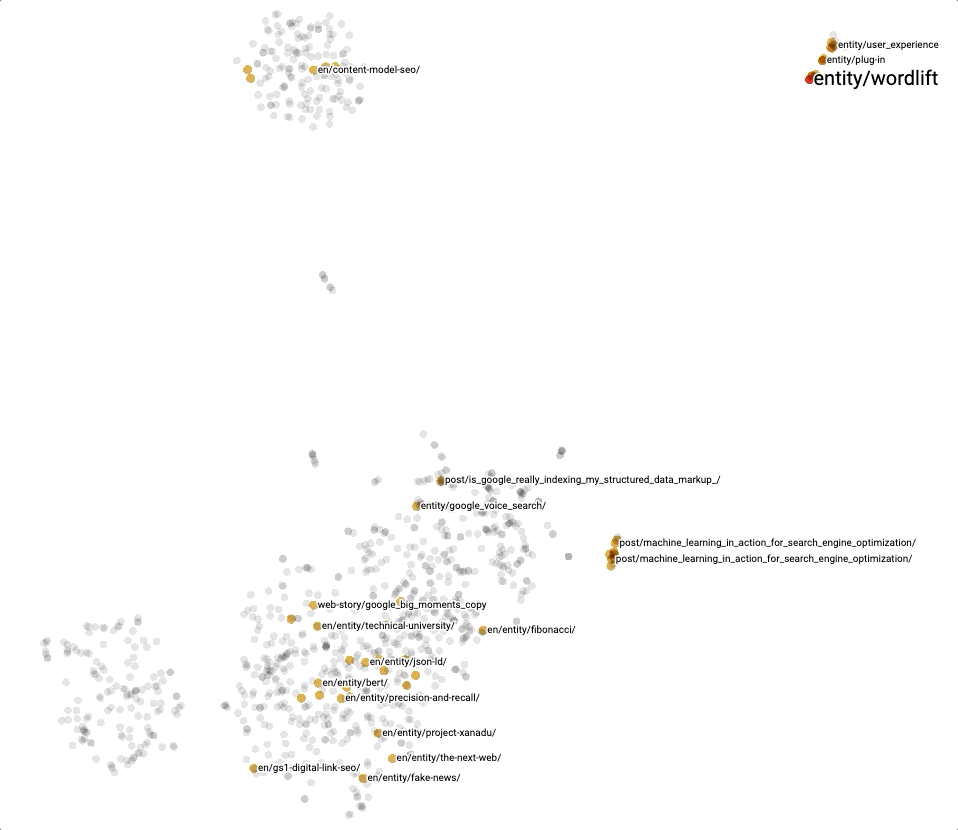
Conclusion
Semantic SEO has revolutionized how we think about content. We can tremendously increase the opportunities to engage with our audience by structuring content while establishing our topical authority. It takes more time to combine all the bits and pieces, but the rewards go beyond SEO. These clusters become effective with paid campaigns for onboarding new team members and let our clients understand who we are, how we work, and how we can help them grow.
As SEOs, we’re constantly at the frontier of human-machine interfaces; we have to learn and do new and different things (such as building a knowledge graph or training language models) and to do things differently (like using embeddings to create content hubs).
We need to reimagine our publishing workflows and optimize the collaborative intelligence that arises when humans and artificial intelligence meet.
The lesson is clear: we can build content hubs using collaborative intelligence. We can transform how we do things and re-organize our website with the help of a knowledge graph. It will be fun, I promise!
More Questions On Content Hubs
Why are content hubs important in Semantic SEO?
In Semantic SEO, we don’t target keywords but rather create topical clusters to help readers understand the content in-depth. We don’t simply create pages but think in terms of concepts and how they relate to each other. We want to become the Wikipedia of our niche and content hubs help us in achieving this goal. Content modeling is an integral part of modern SEO. The more we can become authoritative around a given topic and the more we attract new visitors.
How can I create a knowledge graph for my website?
You can simply start a trial of WordLift and build your knowledge graph ?. Alternatively, Koray Tuğberk GÜBÜR has worked on a Python script that will get you started on building a graph starting from a single web page. Remember that Knowledge graphs are not just for Google to learn about our content but are meant to help us in multiple ways (here is an in-depth article on why knowledge graphs are important).
What type of content hubs exists?
Here is a list of the different types of content hubs:
- Classic hubs. A parent page and a number of sub-pages ranging from a minimum of 5 to a maximum of 30. The work well for every green content and are easy to implement without too much development work. A great example here are Zapier’s guides (https://zapier.com/learn/remote-work/).
- Library style. The main topic is divided in sub-categories and from there the user sees the content items at the end of the journey. A good example here can is Baremetrics’ academy (https://baremetrics.com/academy).
- Wiki Hub. The page is organize like an article on Wikipedia and links to all relevant assets. It might appear similar to the classic hubs but the content is organized differently and some blocks can be dynamic. Investopedia goes in this direction (https://www.investopedia.com/terms/1/8-k.asp).
- Long-tail. Here we have a page that is powered by an internal search engine with faceted navigation. The page is a regular search engine result page but it has an intro text and some additional content to guide the user across the various facets. A great example is our client Bungalowparkoverzicht. (https://www.bungalowparkoverzicht.nl/vakantieparken/subtropisch-zwembad/)
- Directory style. Much like a vocabulary (or a phone book) all sub-topics are organized in alphabetical order. The BTC-Echo Academy is a good example (https://www.btc-echo.de/academy/bibliothek/).
References
- Luca Costabello: Ampligraph: Machine learning on knowledge graphs for fun and profit
- Philipp Cimiano, Universität Bielefeld, Germany: Knowledge Graph Refinement: A Survey of Approaches and Evaluation Methods
- Koray Tuğberk GÜBÜR: Importance of Topical Authority: A Semantic SEO Case Study
- How to Use t-SNE Effectively
- Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. RotatE: Knowledge graph embedding by relational rotation in complex space. CoRR, abs/1902.10197, 2019.
- ComplEx: Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier, and Guillaume Bouchard. Complex embeddings for simple link prediction. CoRR, abs/1606.06357, 2016.
Learn more about topic clusters in SEO, watch our last web story!