
Findability really is a key topic these days if you work with content and if you’re wondering how to leverage on conversational UIs and artificial intelligence.
Whether you are creating content that can easily be picked up by Personal Digital Assistant like Google Assistant, Cortana or Amazon Echo or you’re developing your own AI to power a chatbot over Facebook Messenger, you are indeed working to make your content more accessible and easier to be found.
Findability is about creating a context and guiding the user to make their next move into the funnel.
Every day we read about a new chatbot trying to achieve miraculous results and behind these low-level (or narrow) AIs there is always content playing its magic. Content is essential in many ways and typically comes in three forms:
- data that the chatbot needs to answer a specific question (“how old is Andrea Volpini?”)
- a content card that can bring the user one step closer to the target (i.e. the landing page of a product or an explanatory article on how the ledger works in a blockchain)
- a media asset (an infographic or a video when the device has a display or an audio content).
When creating a conversation UI the structure is always the same and it’s made of a scenario, some intents, a context and… knowledge (the content part).
The scenario depicts the user in a specific condition (i.e. training for my next race, waiting for a connecting flight at the airport or spending time by looking at the ceiling). Each scenario is defined by a series of potential intents (or requests), typically organized in a tree structure (i.e. “what is my pace right now? ok, when will I complete this training session then?” or “when is boarding on my next flight starting? Is the flight on time?”).
The intents are all the things that the user might ask during the interaction with the chatbot, the context is everything being said until that point plus other contextual variables such as the type of device being used, the capability of the device (ie there is a screen to render a web page or it can also play videos) the location of the user and so on.
The knowledge needs to be exposed with a set of APIs and somehow is connected to your content management system. After all a chatbot, in most cases, is just another entry point and/or, in many cases, is the only chance to engage with users trapped in the flow of their social media streams.
Marketing is really about efficiency and if you are planning to make your content smarter to prepare for voice search, you can really plan to re-use the same content and the same metadata also for building your own chatbot.
The 6 steps to make your website talk
Let me give you an example to walk you through the 5 steps required to prepare your content for voice search and AI-driven experiences.
1. Choose an intent that you want to address
As I was preparing the content for the Main Street ROI Webinar with Nils De Moor (CTO and co-founder of WooRank) I looked at recurring questions that I personally have after choosing a Webinar that I’m interested in and I picked one: “When is the webinar on xyz?”.
This is the typical long tail question (made of 6 words with all articles and propositions in the text – as expected from this type of voice search queries) that I would keep on asking before an event.
Typically Who/What/How questions are more generic than When/Where questions. A “When” question, implies that the person is already convinced to attend the webinar, whether when someone is asking a “Who” question (like “Who is Andrea Volpini?”) he or she might still be evaluating the quality of the event.
2. Provide the answer using structured data
Make sure that, when possible, the structured data behind your pages are providing the answer unambiguously. For a “When” that is referred to an event (and a webinar is indeed an online event), using the schema.org vocabulary we can use a specific property that indicates the starting time of the event. It’s called startTime and it can be expressed using date times in UTC format. This information shall be available on the page of the event (the webinar page on my site) but it can also be injected in other articles where I’m mentioning this upcoming webinar. At the metadata level, every concept like our event will have its own unique ID to ensure consistency in the data across multiple web pages (or even multiple websites). So every time I’m mentioning the webinar I can add a reference to the unique ID of the event in my linked data graph and I can repurpose the startDate.
The importance of Rank Zero results
 Since the introduction of the Featured Snippets in 2014, Google is trying to answer to users’ searches with quick organic answers and not only with the list of links we used to see before.
Since the introduction of the Featured Snippets in 2014, Google is trying to answer to users’ searches with quick organic answers and not only with the list of links we used to see before.
These answers are the so-called Rank Zero results: they are composed by an extracted answer (which takes data from other websites around), a display title and an URL. Sometimes they happen to be enriched with images, tables, bulleted lists and more.
Thanks to their position on the SERP, Rank Zero results tend to have a very high CTR.
3. Build content around your answer to provide a context
We want to prepare content that fits into a specific moment (or micro-moments as Google would call it). It’s clear that we need to provide an immediate answer in some cases (i.e. a “When” question demands a clear date in the response) but at the same time, we want to entice the user to find out more. We need a narrative that brings additional value to our users.
We do it all the time when we converse among humans.
One asks a question, and while providing the answer the other moves the conversation one step ahead by adding more details. The same applies to human-to-computer interactions. While you expect an answer you are also usually happy to discover more semantically related content that gravitates around your primary request.
To do so I created a very simple content model that was indeed informed by the same schema.org vocabulary that search engines use to describe online content. It’s called entity-based content model and the principle is simple:
Everything is an entity (a data point describing a thing that exists in the real world with all its attributes), every entity has a corresponding web page and entities are connected one to another in a meaningful way – yes, you get to decide, in your graph, what connects to what.
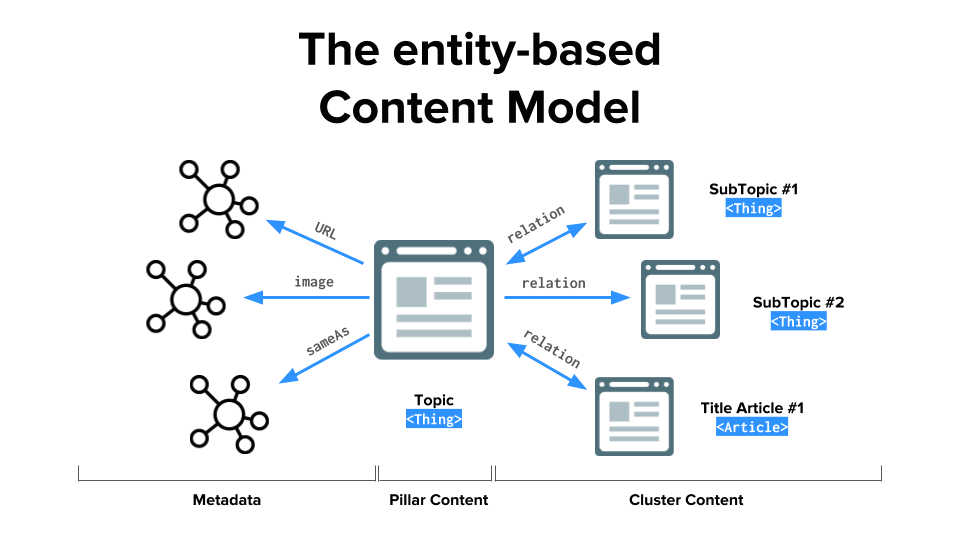
The pillar content sits at the center of the diagram, this is the main page that describes the event with all its corresponding properties (as seen above for, the startDate it is one of them). Linking to and/from here there are other entities and their equivalent web pages. An entity-page about the host of the webinar Scott Abel, an entity-page related to voice search optimization and an entity-page for WordLift. These pages are considered “Cluster content” – they provide both a context and a way to entice the user to discover more about the webinar.
4. Page Load Time is a great SEO opportunity
PageSpeed appears to play a major role in voice search SEO. The average voice search result page loads in 4.6 seconds.
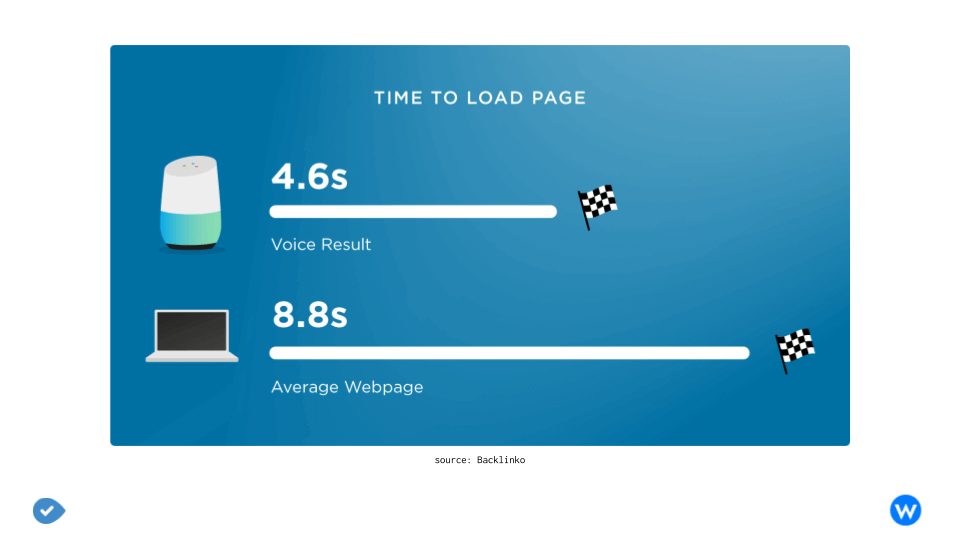
The relationship between website loading speed and voice search is pretty clear since the PageSpeed of the results has been analyzed from Backlinko. The result? The typical loading speed of a voice search result was much faster than most web pages (52% faster than the average page).
People want Google’s answers to be precise but also as fast as possible, an that also applies for Voice Search results. When you ask a question to your Personal Assistant, the answer should be fast: no one likes to wait for a device that lazily spits out an answer. Therefore, it’s plausible that Google’s voice search algorithm would use PageSpeed as a key ranking signal. So that’s what you need to do: just make sure your site loads as quickly as possible.
5. Make sure that both the answer and the content are easily accessible via APIs
When using WordLift a semantic layer is added to your pages that transforms them into entity-pages (this means that a corresponding data point is created off-page and it is referenced on-page using structured data markup and a specific format called JSON-LD). This layer can be accessed by crawling each page (search engines, fact-checking bots crawl your page, look at the metadata and, when available, process it to gain more information about the page). A file with all the metadata is delivered asynchronously using the JSON format and it is accessible in a programmatic way. Just to give you an example if you run from your terminal window this command:
curl 'https://wordlift.io/blog/en/wp-admin/admin-ajax.php' … --data 'action=wl_jsonld&id=5175'
You are going to receive the metadata that describes the page about the webinar from our website with all its corresponding properties.
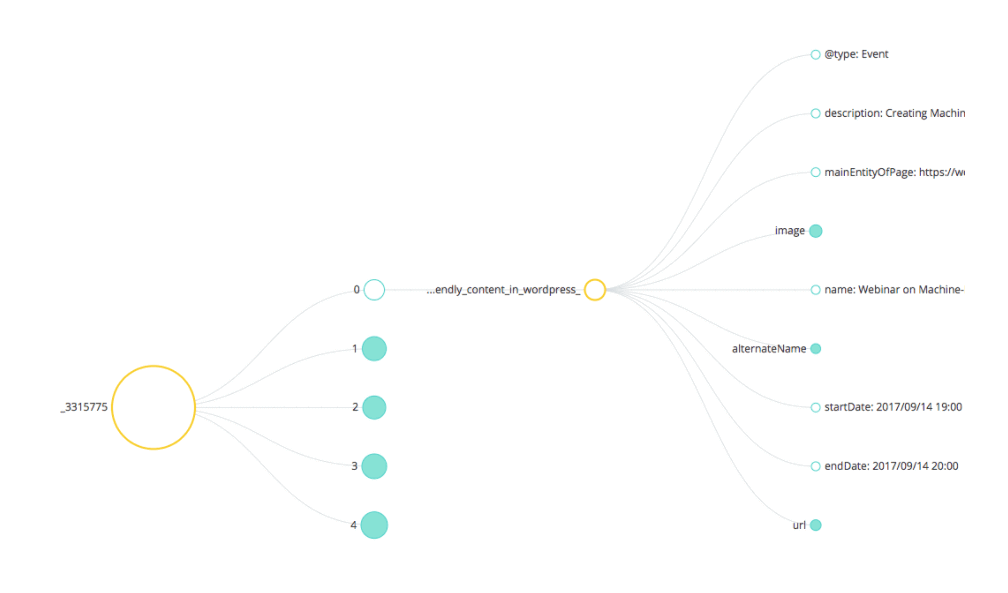
This is extremely useful if you know from your CMS what page contains the information you need and it’s fairly easy to use if you know your way around JSON parsing. This simple JSON-LD file also includes a reference to all the other entity-pages that might be used in the conversation (i.e. the entity-page about Scott Abel, the entity-page on voice search optimization and the entity-page about WordLift).
6. Develop a chatbot, stand out on search results or do both to plug your content into your favorite personal digital assistant
As your content is now semantically-rich and properly structured using the schema.org vocabulary you can basically connect with your audience in two ways:
- you let search engines and personal assistants do their work and you hope to be featured on their voice-enabled results (competition here can be fierce as you can imagine)
- you create your own intent for your own favorite personal digital assistant to make sure users will be able to interact with the content from your website.
I succeeded in doing both. The enriched webinar page was featured as #1 result in Google for the intent that I was optimizing for. This also means that when the question was asked to the Google Assistant the webinar page was provided as the first result and you can see in the example below that the structured data has been essential in providing the user with the actual date of the webinar (as a nice side effect you can see the result had two links instead of just one).
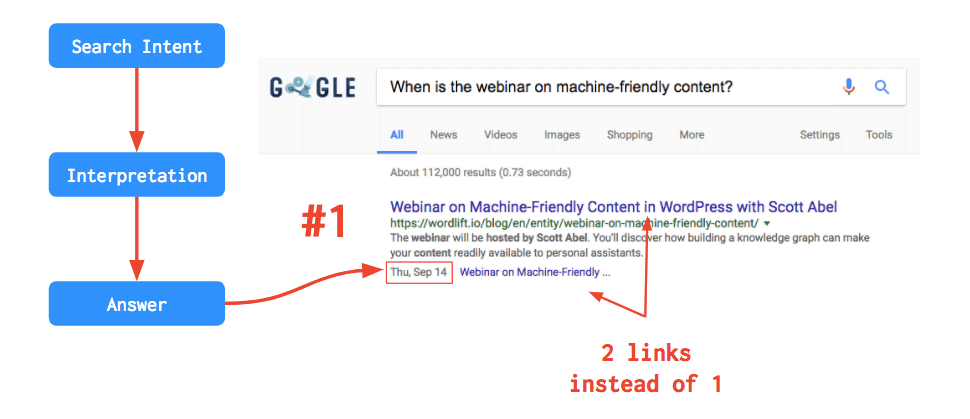
I also created a conversational experience for the Google Assistant using the data from the website along with API.AI, one of the many chatbot platforms, that helped me glue the intents, the context and package the answers. Here below a diagram of the workflow: the Messaging Platform, in this case, is the Google Assistant and API.AI is the NLP & Bot framework that I used.
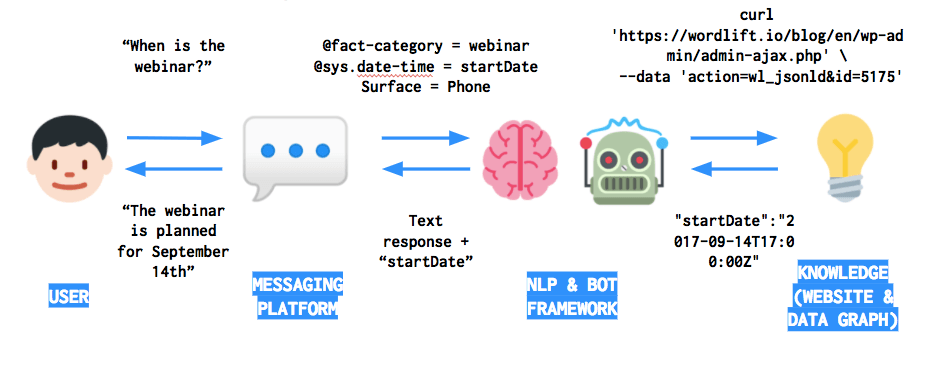
In this way, starting from the same entity-based content model I was able to reach a wider audience and to give a new life to my content.
If you’re interested in knowing more about making your website talk, watch this 1-hour webinar with me and Nils from WooRank. It’s free!
Wanna talk with us? Just drop us an e-mail.