E-commerce SEO for Product Category Pages with the help of AI
Learn about category page optimization for e-commerce improving product category pages by using natural language processing.

Building Product Sub-categories (semi)automatically
Manually working on product knowledge graphs and improving data quality on e-commerce websites is extremely time-consuming and impossible for most businesses that cannot afford an army of expert taxonomists.
In this blog post, I will share how we’re seeding and enriching taxonomies for e-commerce websites using natural language processing.
In general with retail products, improving a graph is much more difficult. We typically don’t deal with clearly defined entities but rather we work with unbounded attributes – lenses for glasses, materials for furniture, and so on. Let’s first review a few concepts and some helpful SEO best practices for creating category pages. This will help us understand the workflow and how we can fine-tune it for our needs.
?? Want to jump right to the Colab? It’s here!
SEO best practices for creating and optimizing category pages
- Having a clear goal in mind, SEO needs to be measurable
- Setting a minimum number of products for new categories
- Working on content that helps
- Preventing keyword cannibalization while improving internal links
Overview of the workflow to automate the creation of subcategories
- Keyword extraction techniques
- Analyzing search demand
- Clustering queries (optional)
- Extract keywords
- Analyze the list of products
What is a product taxonomy?
A taxonomy for products acts like shelves in a supermarket. It is the structure that organizes all products in the most accessible way so that customers can easily find them with the least cognitive effort (and the least amount of clicks). Generally, a product taxonomy is a combination of hierarchies of categories and subcategories and product attributes that are specific for each category (e.g. color or size for t-shirts and frame shape for sunglasses).
What are the main challenges in creating a product taxonomy?
In an ideal world, you want to have clean attributes for every product but in reality, this rarely is the case. Data is sparse, incomplete, and of low quality. Structure sparsity is a very common problem to deal with, you would like to have every item clearly classified but you don’t and only a subset of the catalog has been organized correctly. In general, the knowledge domain is also highly sophisticated and attributes tend to be specific for each category. You also need to deal with sub-types, overlapping elements, and synonyms (i.e. “I call it googles but you call them glasses”).
How to create a product taxonomy?
In knowledge organization, taxonomies don’t grow like plants on their own. They are the results of highly specialized human labor and can be created using different approaches: top-down, bottom-up, or a combination of both. We can either rely on domain experts that guide us through the maze of how to turn more abstract concepts like “accessories” into fine-grained subcategories such as “accessories > sunglasses > sports activewear > running” and so on or we can discover these terms by ourselves and playfully combine them by learning how they relate to each other.
As anticipated, we want to automate the creation of these taxonomies by leveraging machine learning and our understanding of core SEO principles. In general with AI, our main focus is not on the technology that we’re going to use, but rather on how we plan to involve and interact with the humans involved in the process. We want to augment our product knowledge graphs and make them helpful to both, the consumer looking for a product to buy and the merchant that is selling that product.
SEO best practices for creating and optimizing category pages
Before reviewing our framework let’s highlight the SEO best practices when creating a product taxonomy. They will help us understand the code and the workflow that we envisioned.
1. Having a clear goal in mind, SEO needs to be measurable
We have two options:
- Work to attract new users from Google by organizing products around search intents.
- Improve the on-site experience by enriching the existing taxonomy with new products and by extending their list of attributes.
We can work with both targets in mind but the steps will be different and in general, it greatly helps to go one step at a time. You want to measure the impact and work against measurable results. Doing too many things at once never helps.
2. Setting a minimum number of products for new categories
There is no golden rule here but you can use your common sense. You want to be relevant for searchers and provide for each new category page a minimum number of products. Establishing the threshold has to do with competition and user experience. If your competitors have 100 different products on average it is unlucky that you will rank with just 10 products for the same intent. At the same time setting this threshold is also highly dependent on the user experience. If you are able to provide more details at a first glance and can always bring to the top the products that people love you can still win the game even with fewer products.
3. Working on content that helps
A textual introduction to the listing is vital. It doesn’t need to be too long (that would simply not work especially on mobile), ideally the user should be able to collapse it but you need to be very informative, personalized, and crystal clear. What are we selling? To whom are we selling (what is the target audience)? And what we want people to remember about these products. We have been also successful in demonstrating tractions (in both traffic and sales) when adding, at the bottom of categories pages, relevant question-answer pairs using FAQ markup.
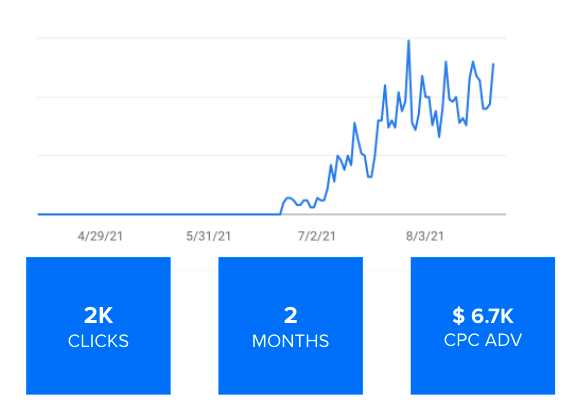
FAQ traffic related to a retail website in the US.
4. Preventing keyword cannibalization while improving internal links
Needless to say, you don’t want to generate traffic in overlap with already existing pages. Quite the opposite, you might want to distribute traffic more evenly across all pages. This basically means that on one side you want to ensure that any new category is not going to overlap with existing pages, and on the other side, you want to ensure that highly-trafficked pages can link to contextually relevant, and less visible, sub-category pages.
Check out the example below. The intro text under home > men > bags of a famous luxury fashion store, provides the user with relevant links to more specific (and less trafficked landing pages).

This is smart as intents are very well defined (1. “I want to buy a designer bag for man” for the main category page and 2 .“I want to buy a Guggi|Off-White’s|Saint Laurent bag for man”) and we can more evenly distribute the link equity from the main page to the sub-pages.
One last note can be added to address concerns on the crawl budget. When creating new pages people are usually afraid of hitting the crawl budget. Now, while it is true that Google tends to be more conservative on indexing the web (also to reduce its carbon footprint) we shall always keep in mind that if you have a million or fewer web pages you shouldn’t worry about a crawl budget. Don’t trust me, read instead what Gary Illyes said on this topic some time ago.
Overview of the workflow to automate the creation of subcategories
The basic idea is the following:
- We begin from a category page and we want to understand our searcher personas. We do that by diving into the queries behind the page. We can collect these queries from either Google Search Console or from SEMrush (sometimes looking at competitors might help gain more insights). We can also choose a timeframe that makes sense for this specific business.
- We can (optionally) cluster the keywords to get a sense of the main intents. We will use BERTopic here.
- We extract the keywords behind these queries (using KeyBERT), remove false positives, low scores, duplicates, oddities of all kinds and other irrelevant terms.
- We re-use these keywords to analyze the titles of the products belonging to our target category.
Finally, choose the terms that will cover the highest number of products as sub-categories.

Keyword extraction techniques
Keyword extraction is a crucial text mining task in our workflow. Provided a search query, the extraction algorithm shall identify a set of terms that represent at best the query. Before choosing KeyBERT, I have tested: YAKE!, an unsupervised keyword extraction library that supports multilingual content (you can give it a quick try here), T Zero, a large language model optimized for zero-shot tasks, and GPT-3. For the sake of this tutorial, we will analyze the category for Ray-Ban on the FarFetch website, a well-established British-Portuguese online luxury fashion retail brand.
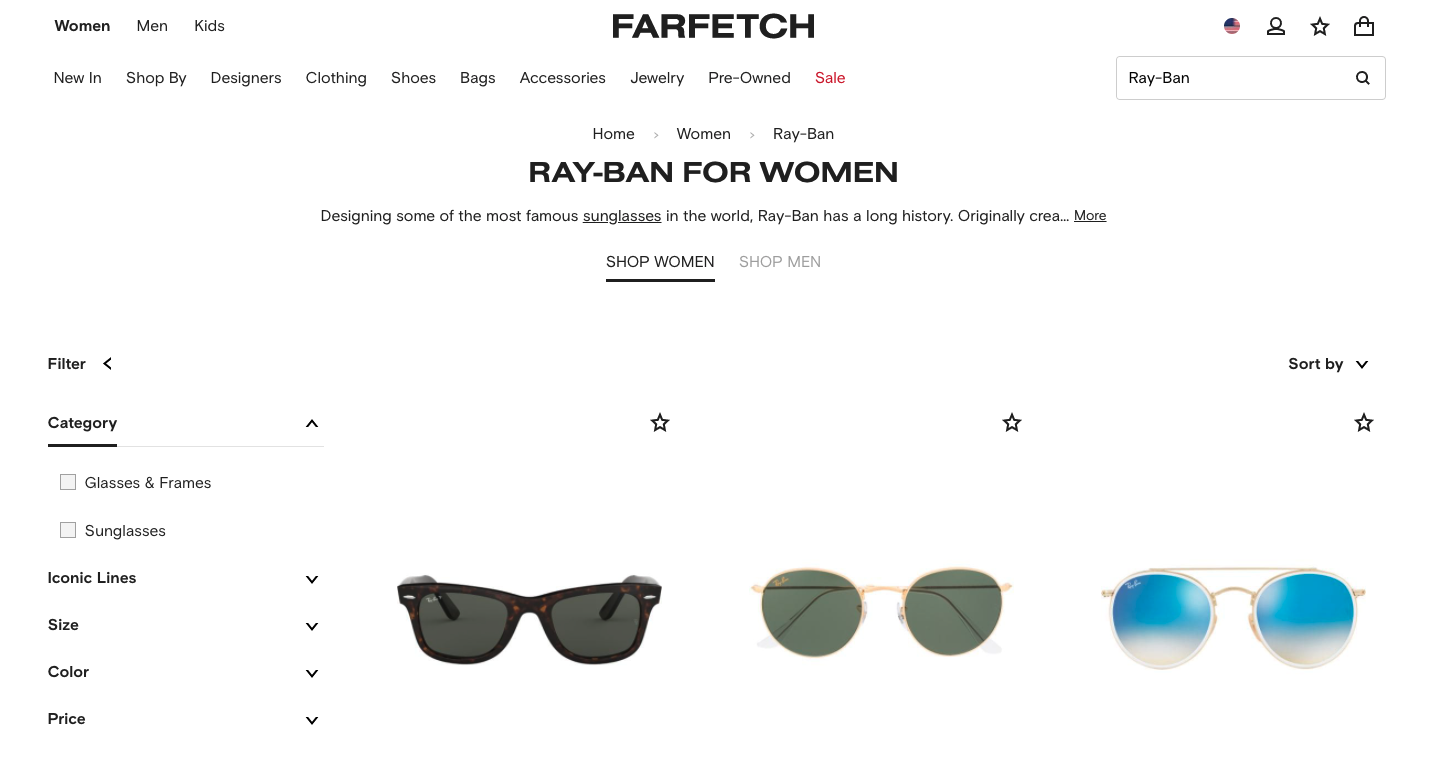
The category for Ray-Ban on FF
1. Analyzing search demand
We always want to use AI to help humans connect and easily find what they are looking for. In other words, we need to use machines to augment human intelligence. To build a taxonomy that makes sense I envisioned the following human-AI interaction. We start by accessing queries from either the Google Search Console or SEMrush. For this tutorial, I have prepared the keyword analysis behind the category page of FarFetch’s Ray-Ban sunglasses in Google Drive (here). We will read this spreadsheet and extract the queries using BERTopic and KeyBERT.
KeyBERT

The advantages I found in KeyBERT, for this project, are the following:
- It’s faster than T Zero and less demanding in terms of memory (running T0_3B on Colab is challenging and time-consuming even when you set the runtime with high memory and GPU acceleration).
- It’s based on the SentenceTransformers (SBERT) and this gives us the flexibility to replace the underlying model and work with any of the models available in the HuggingFace Model Hub. This helps because it provides us with the flexibility to replace the model based on the language of the website. It also allows us to train our own model to improve performances.
- It’s simple, open source and very easy to use, also it allows us to work on both the analysis of the queries and the match between the terms in our controlled vocabulary and the titles of the products.
If you have used SBERT you will immediately find yourself at ease with KeyBERT. The library uses BERT-embeddings and cosine similarity to extract terms from sentences (queries in our case). KeyBERT is a library by Maarten Grootendorst and you can immediately experiment with the BERT Keyword extractor developed by my dear friend Charly Wargnier ?.
2. Clustering queries (optional)
I used BERTopic to explore the queries. In the end, you can simply skip the clustering part, and directly translate queries into keywords using KeyBERT. The advantage of going through the clustering process is that you will be able to better understand the data. If you don’t have enough knowledge of the domain I would suggest going through this step.
There is another reason for clustering the data, we might want to analyze how queries change over time (this is particularly useful when products are affected by seasonality).
Topic modeling
As anticipated we will also use another well-known library by Maarten called BERTopic for the clustering of the terms. BERTopic also is based on SBERT.

BERTopic is well documented and you can experiment with various settings. What I ended up using is the seed_topic_list parameter to have the model converge around a list of seed terms.
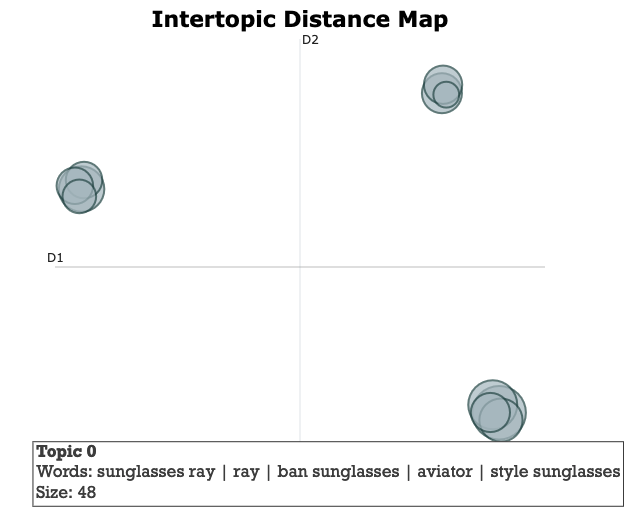
Clusters are visualized in a two-dimensional diagram.
You can use the various visualizations provided by the library to see the queries behind the page. If we look at the diagram below, while not perfectly organized, we can spot some potential subcategories worth creating.
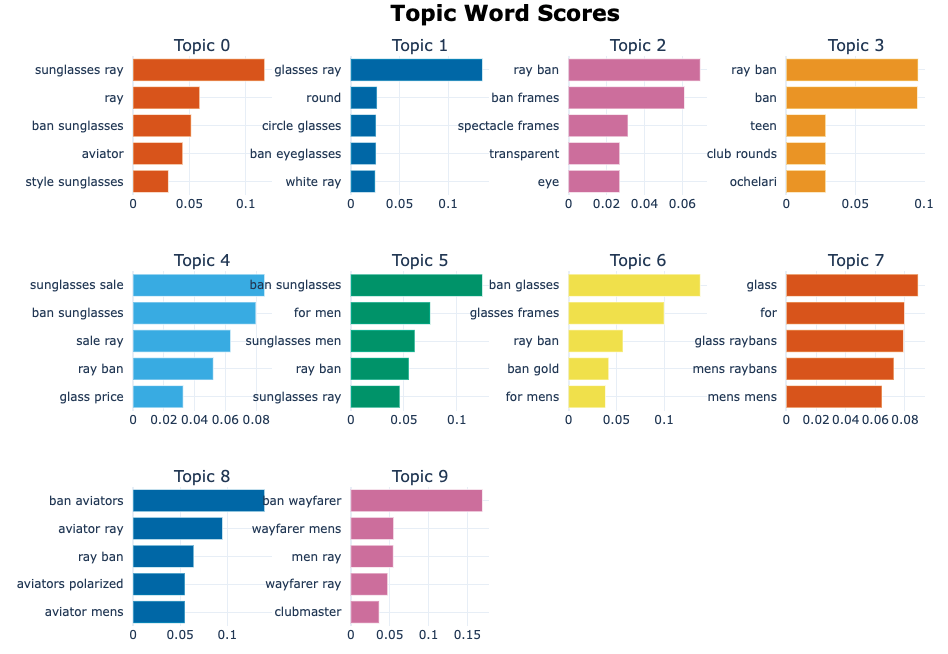
A barchart of the clusters.
The iconic wayfarer versus the classic aviators but also the shapes of the frames (round, circle glasses, etc.) seem to be valuable subcategories to be created.
 |  |
| James Dean wearing the wayfarer | Tom Cruise in Top Gun wearing the aviator |
3. Extract keywords
The core of the workflow, once we have gained a first insight using BERTopic, is really the extraction of keywords from the list of queries that we have obtained from SEMrush.
We do this by using the extract_kw function that will iterate through a pandas data frame and extract keywords using KeyBERT and its useful set of parameters. KeyBERT is relatively fast (depending on the size of the dataset) and runs well on CPU and provides the accuracy we need for this kind of task.

We obtain from extract_kw a new data frame with two terms (top_n=2) for each query and we can also:
- remove stop word for English (_stop_words=”english” is the default),
- decide the length in words of the extracted keywords (_ngram_range=(1,2)),
- set the diversity of the extracted keywords (only works when use_mmr=True),
- use a list of terms to guide the extraction – as we did previously with BERTopic (_seeded_keywords),
- use a list of terms to match the keywords (_candidates), this will be particularly helpful in the next phase of our workflow.
Data cleanup – the steps
Before using the keywords and analyzing the products in our category we’ll need to do some cleanup of the extracted terms. We do this by:
- Matching only terms above a certain threshold (prob_filter >= .7)
- Combining all terms into a single list and remove any duplicated term
- Excluding stop words. These are site-specific and have to do with what people search for and what is relevant for faceting the products. We’ll need to remove branded queries like “ray ban”, things like “eye sunglasses” but also irrelevant keywords like “decal sunglasses”.

4. Analyze the list of products
We can visualize the resulting terms using a word cloud and we can finally use them to review the list of products in our category.

A word cloud of the extracted keywords.
For this tutorial, a subset of the products is listed on the same Google Sheet (here) under the tab “Products”. We can run the extraction using, once again KeyBERT, but this time we will use the _candidates parameter to let the model match the text with any of the previously identified keywords.
We can run this analysis using either the title of the product page, the description of the product, or a combination of both.
We will test it, first using the description of a pair of aviator sunglasses with hexagonal lenses.
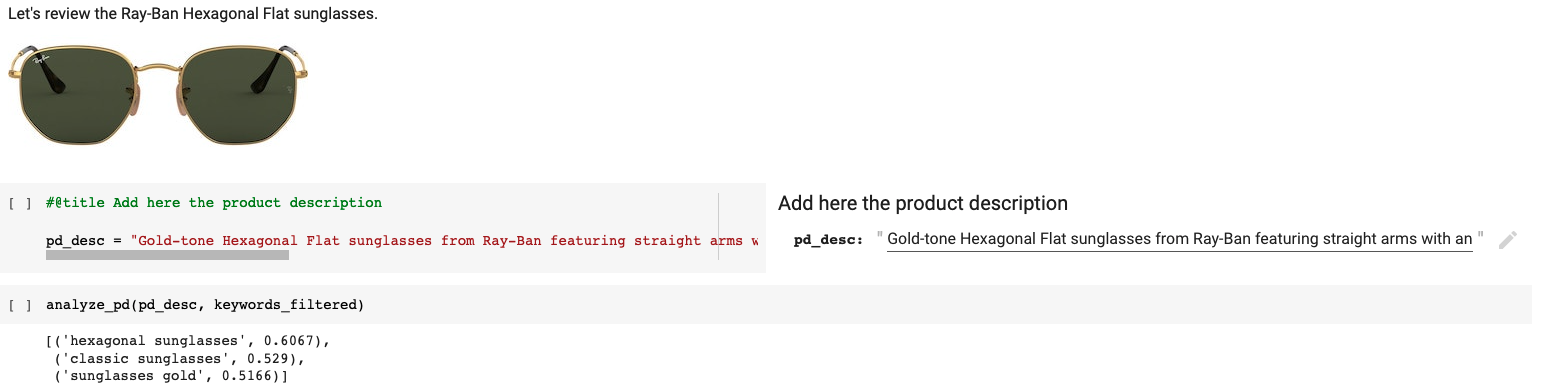
Results are relevant as we obtain for this pair the following terms that well identify this product:
[(‘hexagonal sunglasses’, 0.6067),
(‘classic sunglasses’, 0.529),
(‘sunglasses gold’, 0.5166)]
Using now one single line of code we can process all the products at once and, in our example, we will analyze the title only. Finally, we can look at the resulting data frame and, by looking, at all the terms extracted from the products list we will get:
- Top N terms from the first extracted keyword (kw_1)
- Above a certain threshold ([‘prob_1’] >= 0.5)
- Sorted by count of associated products
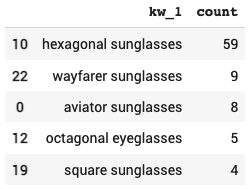
While numbers are irrelevant as we’re dealing with a small subset of the products in our original category we can immediately see that we could add the following subcategories:
- Hexagonal sunglasses
- Wayfarer
- Aviator
- Octagonal sunglasses
- Square sunglasses
If we look at the secondary terms being extracted we might also find it useful to add:
6. Prescription glasses
Conclusions and future work
While I am happy with this initial version of this workflow there are a lot of areas of potential improvement and iteration. Let’s review them:
- Differentiating between hierarchized categories (ie. eyeglasses > prescription glasses) and facets (product attributes like hexagonal or octagonal lenses).
- Adding key business metrics to the selection of the terms. We can weight some queries higher based on their likelihood of ranking. We can add a calculated score that factors multiple weighted inputs (i.e. the likelihood of ranking, the products we have stock, the expected conversion rate etc.).
- Checking first how new products would fit within the existing categories. While we explained how to detect new sub-categories, we can re-use the same methodology to match new products with categories that we already have. Before adding new sub-categories we shall always evaluate if, among the existing categories, there is already a good match.
- Considering a seasonality input, we might decide, for example, to highlight a sub-category related to skiing accessories during the winter and hide it during the summer.
- Matching the detected terms with already existing taxonomies. A category, in a Product Knowledge Graph (PKG), becomes an entity. But in a PKG we already have, in most cases, entities for materials, styles and other product-related attributes. So in these cases, turning terms into entities will be very useful.
- Working, using these detected terms, to instruct an NLG pipeline and create or improve introductory text paragraphs that can match the searcher intent. If we create the sub-category for the wayfarer we will also need a compelling intro text. We can generate this text to respond at best to queries we gathered around the wayfarer.
Once again, always remember the magic is not in the technology that we use but in creating effective and continuous human-AI interactions.
