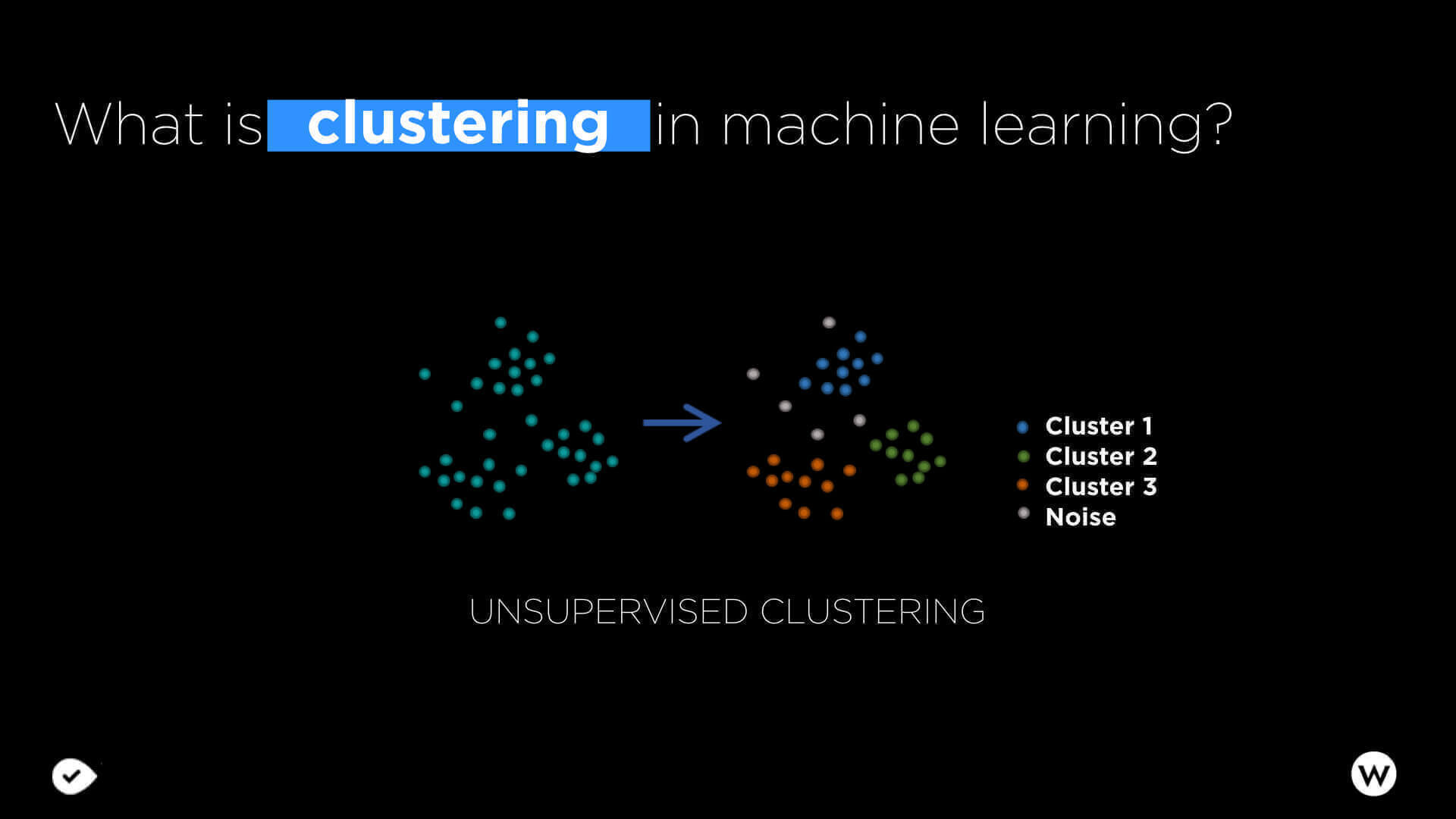
Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called cluster) are more similar (in some sense or another) to each other than to those in other groups (clusters). It is a main task of exploratory data mining, and a common technique for statistical data analysis used in many fields, including machine learning, pattern recognition, image analysis, information retrieval, and bioinformatics.
We can work with cluster analysis using machine learning to analyze queries. In this case, we can use different techniques to cluster queries.
Let’s review them together:
- Supervised text classification when we know the correct output class for each text in a sample dataset.
- Unsupervised text classification zero-shot is one of these techniques where the algorithm observes samples from classes that were not observed during training and needs to predict the class they belong to, we use it for instance for intent classification. You can try it out from here using a WordLift’s key.
- Named Entity Recognition we can extract entities from queries as we do on longtail.wordlift.io
- K-Means clustering one of the simplest and most popular unsupervised machine learning algorithms. K-Means averages the data by identifying a centroid for each group and by grouping all records in a limited number of clusters. A centroid is the imaginary center of each cluster. We used K-Means here to analyze GSC data
- Word Embeddings. Embedding encode the meaning of words using, real-valued vectors so that words that are closer in the vector space are expected to be similar in meaning, once meanings are turned into math we can use K-means to group them, we can use cosine similarity to evaluate how close they are or algorithms like PCA, UMAP and t-SNE to visualize them in a 2D or 3D space.