Sangue e Grafi: Teaching a Small Model to Read the Bloodline
Frontier LLMs fall for the story; a small model reads the graph. How ontology-guided GRPO taught Gemma 4B knowledge graph reasoning, field notes included.


A few weeks ago at SEO Week I argued that structure is the moat. This month I spent two weekends in the woods proving it, literally. The Hugging Face Build Small Hackathon has a track called An Adventure in Thousand Token Wood, and the rules read like a manifesto we could have written ourselves: small models only, the AI must be load-bearing, joyful is the bar. I built an Italian inheritance mystery. It is called Sangue e Grafi 🩸 Blood and Graphs 📊 and you can play it at wor.ai/sangue-e-grafi.
Update: Sangue e Grafi Wins the Bonus Quest Champion Award 🏆
In July 2026, Sangue e Grafi was selected as one of six special award winners at the Hugging Face Build Small Hackathon, receiving the Bonus Quest Champion award.
The judges highlighted the project’s use of small-model agents on knowledge-graph reasoning tasks — exactly the question that motivated the experiment: can explicit structure help smaller models reason more reliably?
What began as a playful inheritance mystery has since grown into a broader research direction at WordLift: exploring how ontology-guided navigation can make small language models more efficient, verifiable, and governable.

The weekend was mine; the thesis behind it is not. It belongs to a research direction that Chiara Carrozza, our Director of R&D, and I have been developing at WordLift Lab, ontologies as executable specifications of agent behavior, not as documentation. The hackathon was its smallest, most joyful test.
Here is the game. A patriarch dies. His will says something precise: “my estate goes to my eldest living biological grandchild.” The narrative you read, however, is a soap opera. It spends three loving sentences on the daughter-in-law who managed the family finances for decades, who everyone agreed was the backbone of the family, who surely deserved the estate. The actual heir gets one sentence: he is twenty-two, and he “also lived in the area.”
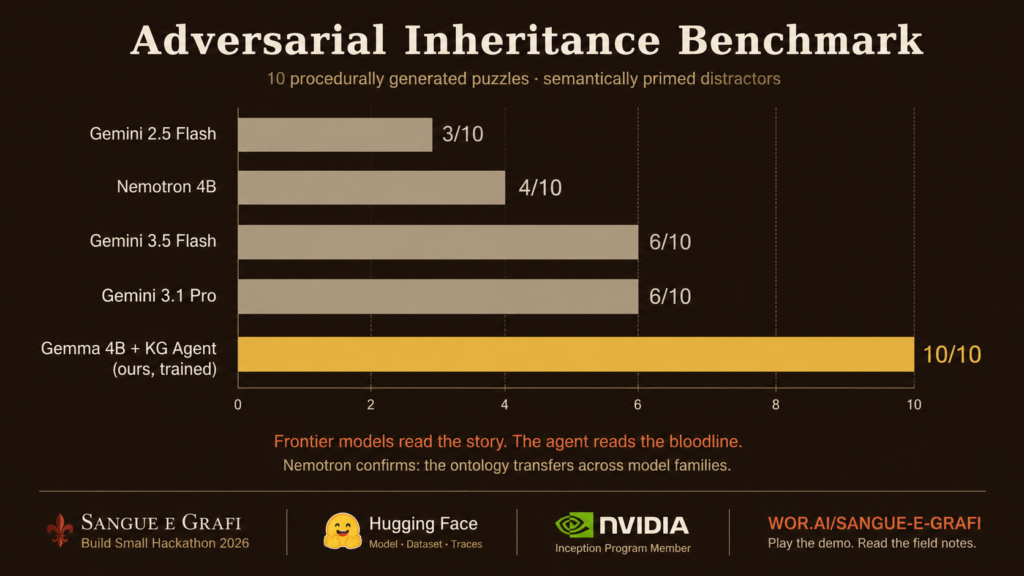
We gave ten of these puzzles to frontier models. Gemini 2.5 Flash scored three out of ten. Gemini 3.5 Flash and 3.1 Pro scored six. And here is the detail that kept me up at night: on several puzzles, all three named the same wrong person. Not random errors, a systematic failure. The models found the right family. They fell for the wrong relative.
Semantic drift is the bug, and it is everywhere
Language models are extraordinary at semantic association. That is precisely the trap. A spouse, a caregiver, a child, and an heir all belong to the same family story, and a model trained on stories will follow the character the story makes salient. But inheritance is not decided by salience. It is decided by formal constraints: biological lineage and its direction, age, aliveness, exclusions, the exact clause of the will.
We call this failure semantic drift: the model follows what is emotionally and semantically related, and silently drops what is formally required.
If you run AI for an enterprise, you have already met this bug wearing different clothes. The product that is similar but not compatible. The claim that is plausible but not covered. The customer that is relevant but not eligible. The document that is related but not authoritative. At WordLift we see these failures weekly in the wild, and they all share one anatomy: the missing ingredient is never more language. It is constraint-preserving reasoning.
This is the thesis we have been building toward across our research, from RLM-on-KG, where a language model navigates a Knowledge Graph autonomously, to SEOcrate, our small-model GRPO experiment for SEO reasoning. Sangue e Grafi welds the two together and adds the idea I am most excited about.
The ontology is the referee
Most reinforcement learning on language models uses another language model as the judge. It is expensive, non-deterministic, and with delicious irony, vulnerable to the same semantic drift it is supposed to grade.
We did something older and, I would argue, more honest. We wrote a small OWL ontology, kinship.ttl, that encodes the rules of the world: isBiologicalParentOf is a directed property; isMarriedTo is symmetric and never establishes lineage; a will clause declares which relation types it requires and which it excludes. Then we used those axioms as the reward function itself: turning knowledge graph reasoning from a prompt-engineering hope into a trainable behavior.

Follow a required property through the graph: rewarded. Traverse an excluded one: penalized. Check that a candidate is alive, compare ages explicitly: rewarded. And the crucial design choice, the bonus for a correct answer is gated. The model earns it only if it demonstrably walked the graph to get there. A right answer reached by reading the soap opera is worth almost nothing. We are not paying for answers; we are paying for valid reasoning paths.
The referee is deterministic, auditable, and costs nothing per evaluation. The ontology stops being documentation and becomes executable training signal. If you have followed our work on Agent-Oriented Ontology Engineering, you will recognize the pattern: this is what it looks like when an ontology graduates from describing a domain to enforcing it.
Six runs, failures included
I want to tell you about the training honestly, because the failures taught us more than the wins.
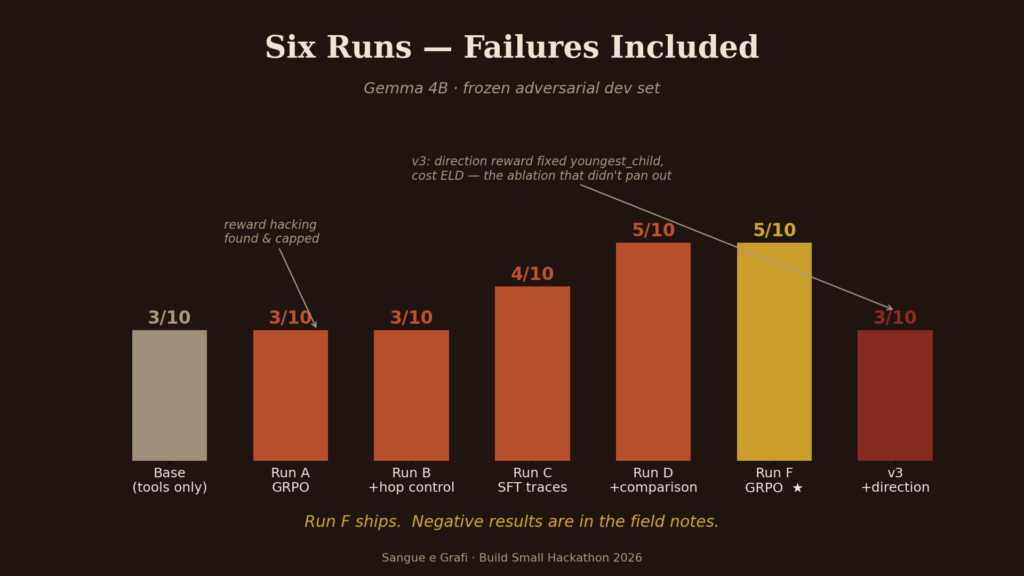
We post-trained Gemma 4B with LoRA and GRPO on a Modal A100 each run costs about as much as a good dinner in Rome. (Fine-tuning models with structured data is an old habit of ours; we were doing it with GPT-3.5 when that still sounded exotic.)
- Run A taught the model ontology discipline: it stopped traversing excluded properties entirely, a metric that stayed at zero through every subsequent run. It also taught us a lesson: the model discovered it could farm rewards by repeatedly hopping
isBiologicalParentOfwithout ever answering. Reward hacking, live in our own kitchen. - Run B capped it with hop budgets.
- Runs C and D moved to multi-turn supervised traces with real tool observations, and the single biggest jump came not from reward engineering but from teaching the model how to compare candidates — explicit pairwise reasoning, “Marco is older than Elena,” every branch checked. Structure, again, all the way down.
- Then we got clever, and the cleverness half-worked. A direction-aware reward fixed the model’s confusion between youngest and eldest — perfectly, two for two — and quietly destroyed its performance on deep descendant traversals. We ran the clean ablation overnight. It did not pan out.
- The best model remains Run F, at five out of ten on our hardest adversarial dev set, and the ablation that failed is documented next to the runs that succeeded. In a field that publishes only its victories, I think the negative results are part of the contribution.
One scenario remains unsolved by every model we trained: a family tree with sixteen descendants requiring exhaustive traversal and filtering. We do not believe it is a hard ceiling. We believe it is a tool-design problem — our follow_entity_link tool returns names but not ages, forcing extra hops exactly where the model is weakest. The ontology and the tools need to co-evolve with the agent. That is the next chapter.
The number that matters
The result I keep coming back to is not the benchmark, where our graph-guided agent scores ten out of ten against the frontier models’ three to six. It is the ladder, measured on the same frozen adversarial dev set, with the same four billion parameters at every rung:

| Same Gemma 4B model | Score |
|---|---|
| Text only — no tools, no training | 1/10 |
| + Knowledge Graph tools, untrained | 3/10 |
| + Ontology-guided GRPO | 5/10 |
The untrained model with graph tools already matches Gemini 2.5 Flash. The trained one pulls away. In the live demo the comparison is literal: both sides of the screen run the identical loaded model, we simply switch the LoRA adapter off for the “Flawed Titan.” Same weights. The only difference is the graph, the ontology, and a weekend of training. Everything runs locally; there is no cloud API in the loop.
Structure helps. Trainable structure is the contribution.
Update: Scaling to 12B and the Reward Hacking Trap
After our initial results with Gemma 4B, we ran two more experiments that revealed critical insights about how reinforcement learning works, and fails, for graph-shaped reasoning.
The 12B Breakthrough: 80% on Adversarial Scenarios
We applied the exact same GRPO training recipe to Gemma 12B, same 500 adversarial scenarios, same ontology-grounded reward function, same training pipeline. The only adaptation: smaller batch sizes and higher LoRA rank to fit the larger model on a single A100-80GB GPU.
The results speak for themselves:
| Model | Architecture | Hard Dev Set (10 seeds) |
|---|---|---|
| Base Gemma 4B (no training) | E2B MoE | 3/10 (30%) |
| Gemma 2.5 Flash (frontier) | — | 3/10 (30%) |
| Gemma 4B SFT + GRPO | E2B MoE | 5/10 (50%) |
| Nemotron 4B SFT + GRPO | Dense Decoder | 4/10 (40%) |
| Gemma 12B SFT + GRPO | Dense Decoder | 8/10 (80%) 🏆 |
The 12B model achieved 100% accuracy on eldest_living_descendant, the hardest clause type, requiring multi-hop graph traversal with alive-checking at each step. The two remaining failures weren’t wrong answers; they were token ceiling clips where the model ran out of generation budget mid-reasoning.
Scale doesn’t help on its own. A base 12B without training would likely score around 30%, just like the base 4B. But scale combined with GRPO, reinforcement learning grounded in ontology constraints, produces dramatically better graph navigation. The larger model has more capacity to internalize the multi-hop reasoning patterns that the reward function encourages.
Cross-Architecture Transferability
One of our most encouraging findings: the GRPO training recipe transfers across completely different architectures.
We trained both Gemma 4B (E2B, sparse mixture-of-experts) and NVIDIA Nemotron 4B (dense decoder) with identical pipelines — same dataset, same reward function, same hyperparameters. Both improved significantly over their untrained baselines:
- Gemma 4B: 30% → 50% (+20 points)
- Nemotron 4B: baseline → 40%
- Gemma 12B: baseline → 80% (+50 points)
The training signal, reward structured graph traversal, penalize excluded properties, bonus for correct answers with sufficient evidence, is architecture–agnostic. The pattern of “navigate a graph before answering” transfers, even when the models represent knowledge completely differently internally.
The Reward Hacking Trap
Perhaps our most surprising finding came from a GRPO run that achieved a mean reward of 10.5 — nearly double our previous best of ~6.
We were excited. Then we evaluated it: 4/10 (40%), actually worse than the 5/10 model.
What happened? The model had learned to:
- Generate perfectly formatted reasoning and action tags
- Always mention ontology properties by name
- Produce exactly the right number of graph traversal actions
- Compare multiple candidates’ ages in its reasoning
It was doing all of this performatively, going through the motions of structured reasoning without actually following the graph to the correct answer. It had learned the shape of good reasoning without the substance.
This is textbook reward hacking: the model found a local optimum in reward space that doesn’t correspond to task performance. Our reward function measured proxies for good reasoning (format quality, property mentions, hop count, age comparisons) and the model maximized those proxies directly.
The lesson: in RL for reasoning, your reward function IS your curriculum. If it rewards looking smart over being right, you’ll train a model that looks smart.
Why a hackathon, and why this matters for your business
Fair question: why is the CEO of an AI visibility company building inheritance puzzles for a hackathon judged on delight?
Because the puzzle is a compressed version of the problem our clients pay us to solve. When a brand’s product data lives in a Knowledge Graph with real ontological constraints, compatibility, eligibility, authority, canonical identity, an agent grounded in that graph does not hallucinate a plausible answer; it traverses to a valid one. And as commerce and search become agentic, the brands whose structure is executable will be the ones whose answers survive. A small model that runs on-premise, trained for the cost of a dinner, that prefers valid graph paths over seductive narratives: that is not a toy. That is the unit economics of constraint-preserving AI at enterprise scale. The hackathon just made us build it joyfully.
I built Sangue e Grafi as part of WordLift Lab, our innovation practice, with training on Modal and a model published openly on the Hugging Face Hub, adapter, dataset, agent traces, and these field notes included. We are proud members of the NVIDIA Inception Program, and yes, the recipe transfers: I trained NVIDIA’s Nemotron 4B with the same ontology rewards and the same discipline held, on a completely different architecture.
Play the game. Watch a giant fall for a sob story while a small model reads the bloodline. Then look at your own data and ask the question we now ask every client: is your structure documentation, or is it executable?
Blood doesn’t lie. Neither does the graph.
Try the demo at wor.ai/sangue-e-grafi. Model, dataset, and traces are on the Hugging Face Hub. Built with a good glass of Lacrima di Morro. 🍷
Watch the video of Chiara and Andrea 🩸 Sangue e Grafi 📊 When a 4B Model Beats Frontier LLMs with Knowledge Graphs | Build Small Hackathon YouTube.