
One of the most fascinating features of deep neural networks applied to NLP is that, provided with enough examples of human language, they can generate text and help us discover many of the subtle variations in meanings. In a recent blog post by Google research scientist Brian Strope and engineering director Ray Kurzweil we read:
“The content of language is deeply hierarchical, reflected in the structure of language itself, going from letters to words to phrases to sentences to paragraphs to sections to chapters to books to authors to libraries, etc.”
Following this hierarchical structure, new computational language models, aim at simplifying the way we communicate and have silently entered our daily lives; from Gmail “Smart Reply” feature to the keyboard in our smartphones, recurrent neural network, and character-word level prediction using LSTM (Long Short Term Memory) have paved the way for a new generation of agentive applications.
From keyword research to keyword generation
As usual with my AI-powered SEO experiments, I started with a concrete use-case. One of our strongest publishers in the tech sector was asking us new unexplored search intents to invest on with articles and how to guides. Search marketers, copywriters and SEOs, in the last 20 years have been scouting for the right keyword to connect with their audience. While there is a large number of available tools for doing keyword research I thought, wouldn’t it be better if our client could have a smart auto-complete to generate any number of keywords in their semantic domain, instead than keyword data generated by us? The way a search intent (or query) can be generated, I also thought, is also quite similar to the way a title could be suggested during the editing phase of an article. And titles (or SEO titles), with a trained language model that takes into account what people search, could help us find the audience we’re looking for in a simpler way.
 |
Jump directly to the code: Interactive textgenrnn Demo w/ GPU for keyword generation |
The unfair advantage of Recurrent Neural Networks
What makes an RNNs “more intelligent” when compared to feed-forward networks, is that rather than working on a fixed number of steps they compute sequences of vectors. They are not limited to process only the current input, but also everything that they have perceived previously in time.
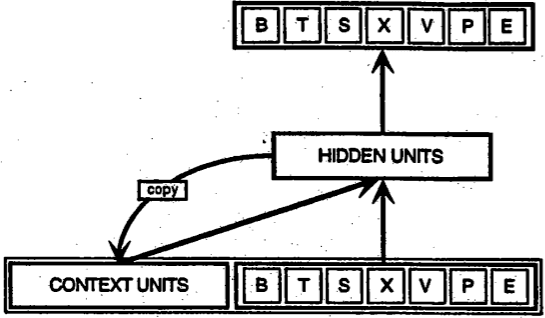
This characteristic makes them particularly efficient in processing human language (a sequence of letters, words, sentences, and paragraphs) as well as music (a sequence of notes, measures, and phrases) or videos (a sequence of images).
RNN, I learned in the seminal blog post by Andrej Karpathy on their effectiveness, are considered Turing-Complete: this basically means that they can potentially build complete programs.
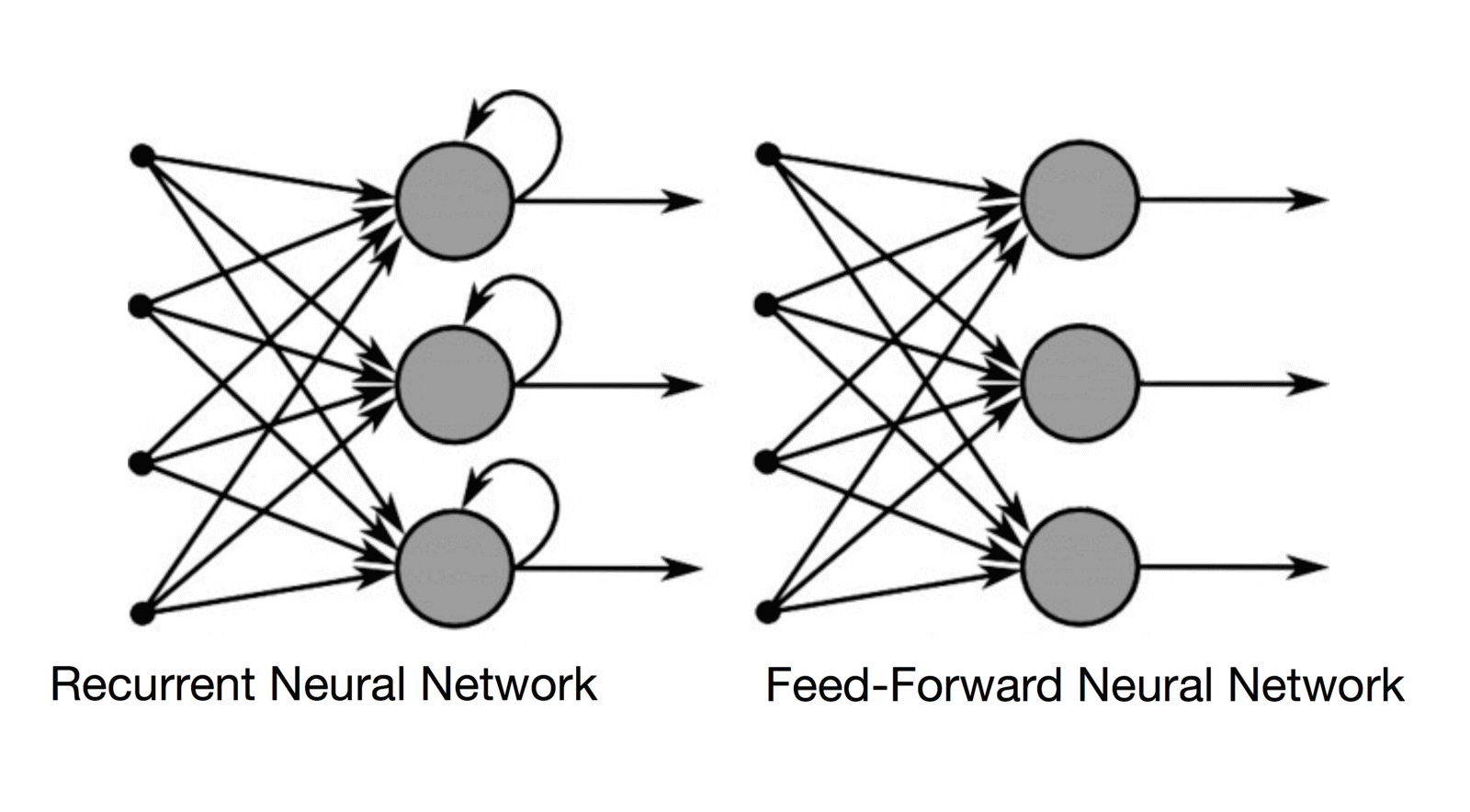
Here above you can see the difference between a recurrent neural network and a feed-forward neural network. Basically, RNNs have a short-memory that allow them to store the information processed by the previous layers. The hidden state is looped back as part of the input. LSTMs are an extension of RNNs whose goal is to “prolong” or “extend” this internal memory – hence allowing them to remember previous words, previous sentences or any other value from the beginning of a long sequence.
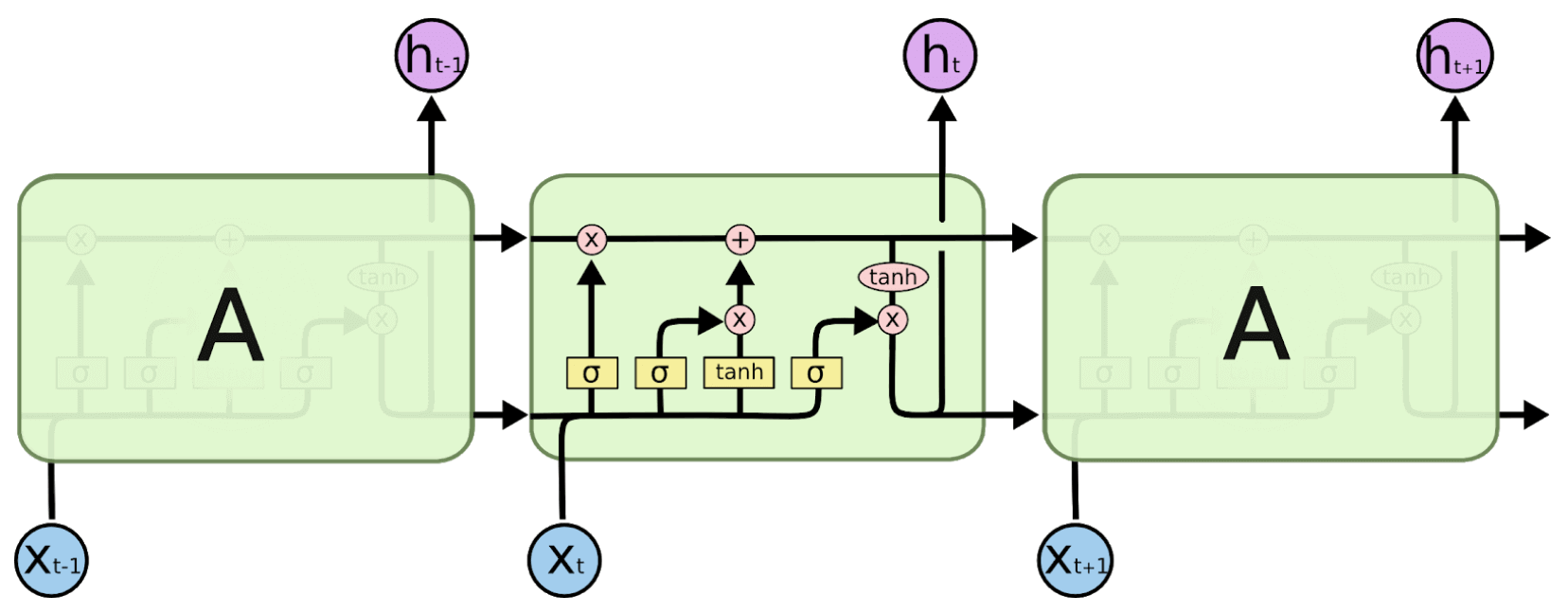
Imagine a long article where I explained that I am Italian at the beginning of it and then this information is followed by other let’s say 2.000 words. An LSTM is designed in such a way that it can “recall” that piece of information while processing the last sentence of the article and use it to infer, for example, that I speak Italian. A common LSTM cell is made of an input gate, an output gate and a forget gate. The cell remembers values over a time interval and the three gates regulate the flow of information into and out of the cell much like a mini neural network. In this way, LSTMs can overcome the vanishing gradient problem of traditional RNNs.
If you want to learn more in-depth on the mathematics behind recurrent neural networks and LSTMs, go ahead and read this article by Christopher Olah.
Let’s get started: “Io sono un compleanno!”
After reading Andrej Karpathy’s blog post I found a terrific Python library called textgenrnn by Max Woolf. This library is developed on top of TensorFlow and makes it super easy to experiment with Recurrent Neural Network for text generation.
Before looking at generating keywords for our client I decided to learn text generation and how to tune the hyperparameters in textgenrnn by doing a few experiments.
AI is interdisciplinary by definition, the goal of every project is to bridge the gap between computer science and human intelligence.
I started my tests by throwing in the process a large text file in English that I found on Peter Norvig’s website (https://norvig.com/big.txt) and I end up, thanks to the help of Priscilla (a clever content writer collaborating with us), “resurrecting” David Foster Wallace with its monumental Infinite Jest (provided in Italian from Priscilla’s ebook library and spiced up with some of her random writings).
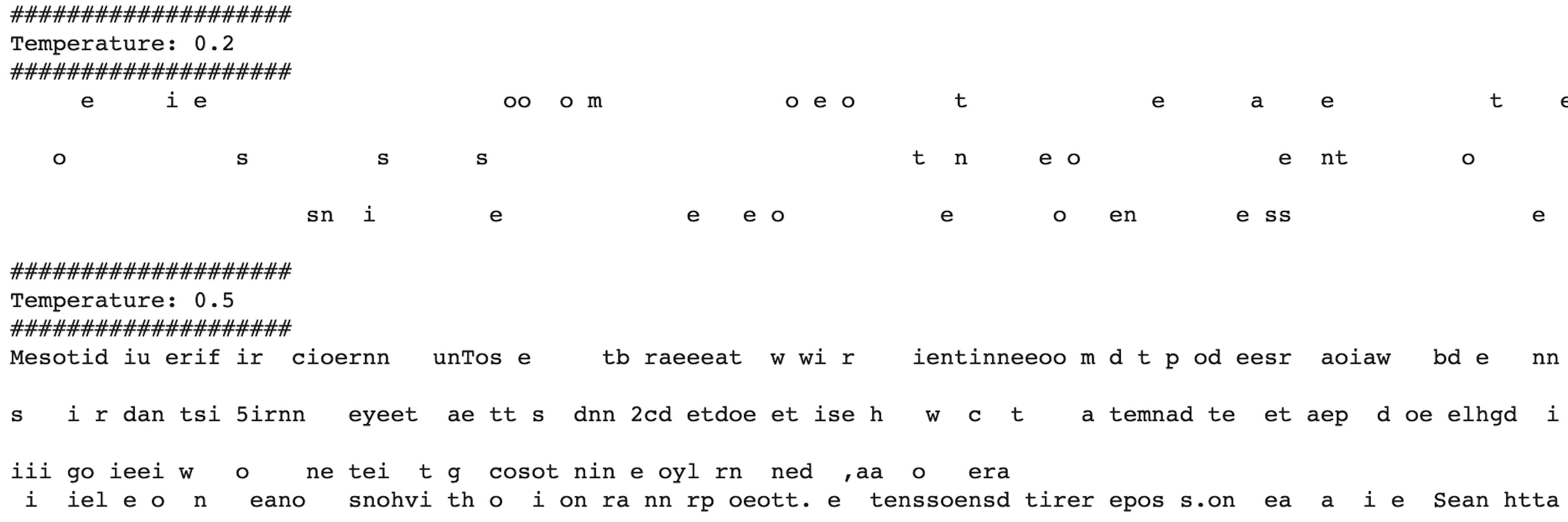
At the beginning of the training process – in a character by character configuration – you can see exactly what the network sees: a nonsensical sequence of characters that few epochs (training iteration cycles) after will transform into proper words.
As I became more accustomed to the training process I was able to generate the following phrase:
“Io sono un compleanno. Io non voglio temere niente? Come no, ancora per Lenz.”
“I’m a birthday. I don’t want to fear anything? And, of course, still for Lenz.”

Unquestionably a great piece of literature ?that gave me the confidence to move ahead in creating a smart keyword suggest tool for our tech magazine.
The dataset used to train the model
As soon as I was confident enough to get things working (this means basically being able to find a configuration that – with the given dataset – could produce a language model with a loss value equal or below 1.0), I asked Doreid, our SEO expert to work on WooRank’s API and to prepare a list of 100.000 search queries that could be relevant for the website.
To scale up the number we began by querying Wikidata to get a list of software for Windows that our readers might be interested to read about. As for any ML, project data is the most strategic asset. So while we want to be able to generate never-seen-before queries we also want to train the machine on something that is unquestionably good from the start.
The best way to connect words to concepts is to define a context for these words. In our specific use case, the context is primarily represented by software applications that run on the Microsoft Windows operating system. We began by slicing the Wikidata graph with a simple query that provided us with the list of 3.780+ software apps that runs on Windows and 470+ related software categories. By expanding this list of keywords and categories, Doreid came up with a CSV file containing the training dataset for our generator.

After several iterations, I was able to define the top performing configuration by applying the values below. I moved from character-level to word-level and this greatly increased the speed of the training. As you can see I have 6 layers with 128 cells on each layer and I am running the training for 100 epochs. This is indeed limited, depending on the size of the dataset, by the fact that Google Colab after 4 hours of training stops the session (this is also a gentle reminder that it might be the right time to move from Google Colab to Cloud Datalab – the paid version in Google Cloud).


Rock & Roll, the fun part
After a few hours of training, the model was ready to generate our never-seen-before search intents with a simple python script containing the following lines.
Here a few examples of generated queries:
| where to find google drive downloads |
| where to find my bookmarks on google chrome |
| how to change your turn on google chrome |
| how to remove invalid server certificate error in google chrome |
| how to delete a google account from chrome |
| how to remove google chrome from windows 8 mode |
| how to completely remove google chrome from windows 7 |
| how do i remove google chrome from my laptop |
You can play with temperatures to improve the creativity of the results or provide a prefix to indicate the first words of the keyword that you might have in mind and let the generator figure out the rest.
Takeaways and future work
“Smart Reply” suggestions can be applied to keyword research work and is worth assessing in a systematic way the quality of these suggestions in terms of:
- validity – is this meaningful or not? Does it make sense for a human?
- relevance – is this query really hitting on the target audience the website has? Or is it off-topic? and
- impact – is this keyword well-balanced in terms of competitiveness and volume considering the website we are working for?
The initial results are promising, all of the initial 200+ generated queries were different from the ones in the training set and, by increasing the temperature, we could explore new angles on an existing topic (i.e. “where is area 51 on google earth?”) or even evaluate new topics (ie. “how to watch android photos in Dropbox” or “advertising plugin for google chrome”).
It would be simply terrific to implement – with a Generative Adversarial Network (or using Reinforcement Learning) – a way to help the generator produce only valuable keywords (keywords that – given the website – are valid, relevant and impactful in terms of competitiveness and reach). Once again, it is crucial to define the right mix of keywords we need to train our model (can we source them from a graph as we did in this case? shall we only use the top ranking keywords from our best competitors? Should we mainly focus on long tail, conversational queries and leave out the rest?).
One thing that emerged very clearly is that: experiments like this one (combining LSTMs and data sourcing using public knowledge graphs such as Wikidata) are a great way to shed some light on how Google might be working in improving the evaluation of search queries using neural nets. What is now called “Neural Matching” might most probably be just a sexy PR expression but, behind the recently announced capability of analyzing long documents and evaluating search queries, it is fair to expect that Google is using RNNs architectures, contextual word embeddings, and semantic similarity. As deep learning and AI, in general, becomes more accessible (frameworks are open source and there is a healthy open knowledge sharing in the ML/DL community) it becomes evident that Google leads the industry with the amount of data they have access to and the computational resources they control.
Credits
This experiment would not have been possible without textgenrnn by Max Woolf and TensorFlow. I am also deeply thankful to all of our VIP clients engaging in our SEO management services, our terrific VIP team: Laura, Doreid, Nevine and everyone else constantly “lifting” our startup, Theodora Petkova for challenging my robotic mind ?and my beautiful family for sustaining my work.