
This tutorial will use Microsoft ORCAS, a unique click-based dataset that I discovered thanks to Dawn Andersons 🤩. We will expand an initial set of keywords and use embeddings to provide a context around the resulting list of search queries.
Microsoft has curated the dataset in the context of TREC (Text REtrieval Conference), a community, and a series of workshop that focuses on different information retrieval (IR) research areas.
Each record in the dataset connects a query with a web document, where Microsoft provides both the document identifier and the document’s URL:
- QID: 10103699
- Q: why is the sky blue
- DID: D1968574
- U: http://www.sciencemadesimple.com/sky_blue.html
I decided to focus on queries only (Q); I wanted to quickly explore the vocabularies of searches by expanding a set of terms. I wanted to see what people are searching for around a given topic and be able to suggest potential opportunities to our clients.
This data, while static, has excellent potential indeed as we have ten million distinct queries taken from the real world (most probably searches done on Bing).
Feel free to re-use this workflow with any list of queries that you might have from either the Google Search Console, SEMrush, Ahrefs, or any other keyword tool.

Here is the link to the Colab that will generate the embeddings.

Here is the link to the TensorFlow Projector to visualize the embeddings.
Encoding meanings
When we look at a query, we want to understand its meaning and the search intent. We can do this by providing a context around it. We can use word embeddings and pre-trained language models in natural language processing to achieve this goal. An existing language model has been trained on a large corpus of text “to learn” how language is commonly used.
When we create the embeddings, we transfer this knowledge to our dataset. While generating the embeddings for the entire dataset is feasible (it worked up to 4M queries without issues), I decided to work on a specific subset of terms.
Filtering queries
As I was working on this experiment with my dear friend Matteoc (well-known for his addiction to sports cars), I decided to analyze a cluster of intent related to the marvelous world of Porsche AG, the car manufacturer.
You can, of course, choose a different topic.
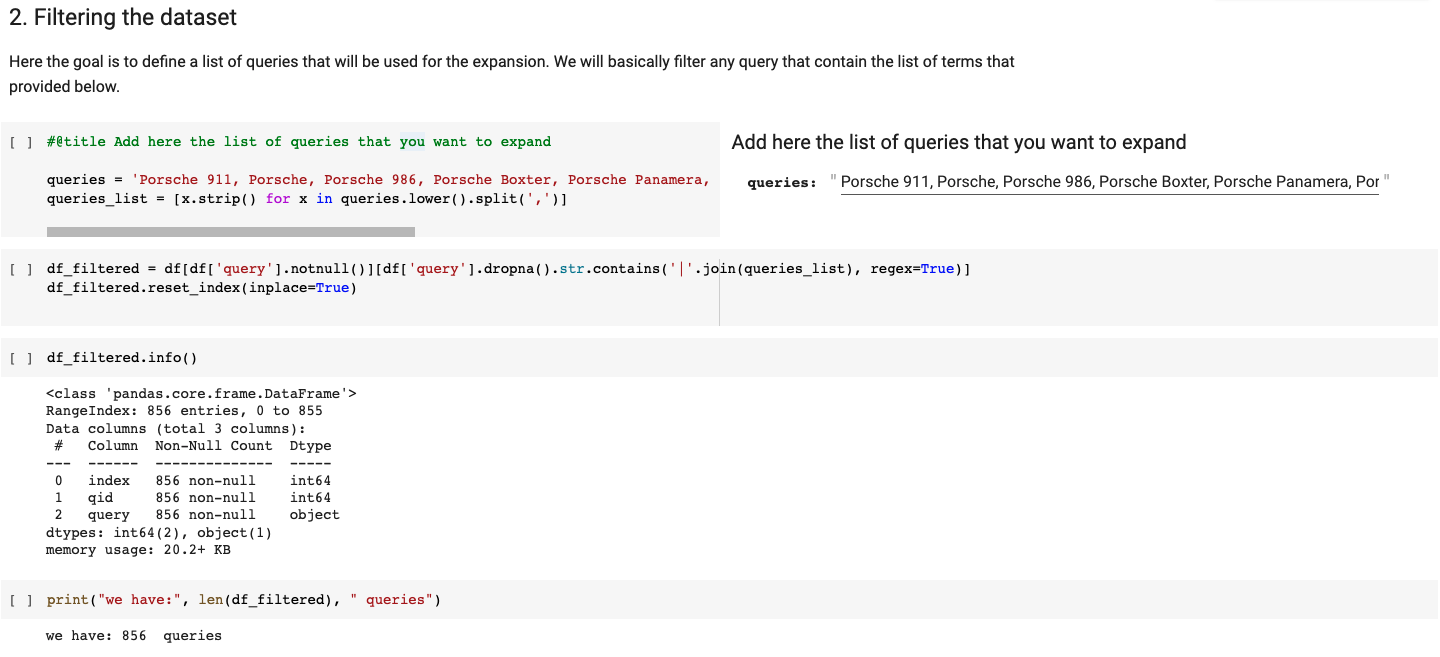
The code is simple and easy to be improved but essentially gets from the ORCAS datasets all the queries that match the list of provided terms. In our Porsche example, we obtained 856 queries.
SentenceTransformers
To create the embedding, I have chosen the SentenceTransformers, a Python framework for state-of-the-art sentence (text and now image) embeddings.
It is a widely used library and works with pre-trained models hosted on the HuggingFace Model Hub.
Clustering and the TensorFlow Projector
Once we have turned every query into a multidimensional vector, we can focus on clustering. We can use a dimensionality reduction algorithm like UMAP and HDBSAN for clustering or directly using K-means. The code used for generating the first charts is the same described in the blog post Topic Modeling with BERT by the great Maarten Grootendorst.
My personal choice for exploring data is, in these cases, to directly plug the embeddings in the TensorFlow Projector. The TensorFlow Projector is a visual tool designed to analyze and explore embeddings (or any form of data in multidimensional space) by projecting them in a 3D environment that you can access from your browser.
Since our embeddings are stored as a pandas data frame, we can export them for the Projector with only a few lines of code.

Reviewing intents around Porsche-AG

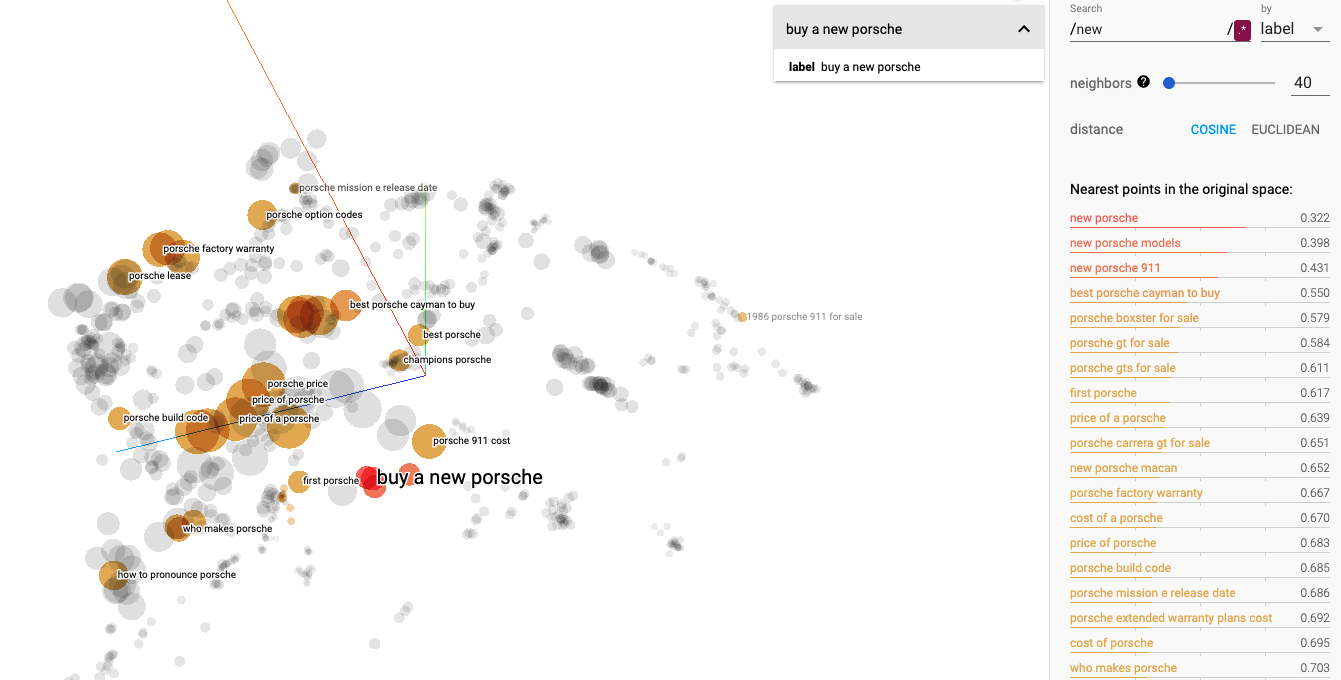
Porsche is one of the most iconic brands of all time, and we can look at search intents from so many different angles. Let’s begin with the buying intent by analyzing the nearest queries around “buy a new porsche”. We can immediately recognize some related queries or patterns of queries in this cluster:
- new porsche models
- best porsche [model name] to buy | for sale
- cost of porsche
- first porsche
- porsche leasing
- porsche factory warrant
- ….
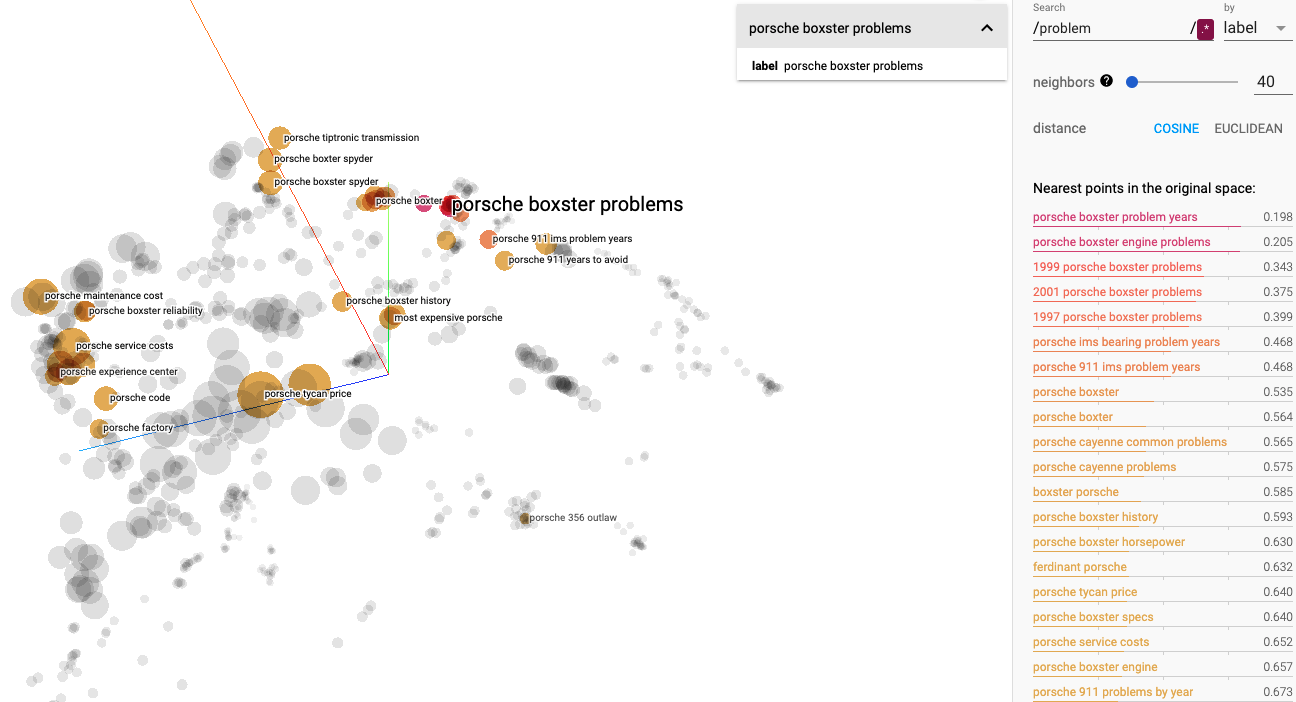
We can also immediately perceive that, as any car manufacturer, they have to deal with various problems and that the Boxter model seems to be the most critical, as we can see from the chart below. Interesting to see that most of the editions of the Boxter throughout the years have had some issues.
Conclusions and next steps
Organic growth highly depends on the correct information architecture of a website. Clustering queries is strategic to determine what intent we can target with a given web page, what intents should be part of a content hub, and how informational and transactional intents can be split between blog pages, category, and product pages.
We can achieve these goals by analyzing the clickstream and adding the relevant context using language modeling and embeddings.
I also plan to add entity recognition to expand further the metadata that we are sending to the TensorFlow Projector to determine what concepts are associated with what queries quickly. It will also be helpful to use competition and volume to highlight the opportunities further. Happy holidays and happy fun coding!
To learn more about keyword research using AI and try the TensorFlow Projector, see our web story.