Is Google Really Indexing My Structured Data Markup?
Is Google really indexing your structured data markup? Learn how to ensure that Google can crawl and index your markup.

- How does Google index structured data created on the fly with JavaScript?
- How to add JSON-LD markup to your web pages?
- I have added a JSON-LD. How can I check if Google is indexing it
- What are the most common pitfalls preventing Google from indexing schema markup?
- The need for constant monitoring of your schema markup. A few solutions.
It might seem a trivial question at first, but it is not. After adding schema markup to hundreds of websites, we realized that conditions can differ from one site to another. Before evaluating, if a given markup is effectively helping Google understand the content of a webpage, we need to ensure that Google can crawl and index its markup.
Regardless of the format that you are using to add structured data markup to your webpages, whether it is JSON-LD, Microdata or RDFa, you have two options:
- Writing the code as part of the HTML of the page (server-side injection),
- Using JavaScript to inject the markup into the page (client-side injection).
When using JavaScript, structured data is effectively written by a script that gets executed on the client. WordLift, for example, injects for all non-WordPress websites schema markup with JavaScript.
How does Google index structured data created on the fly with JavaScript?
Google Search interprets structured data that is available in the DOM during the so-called ‘rendering phase’.
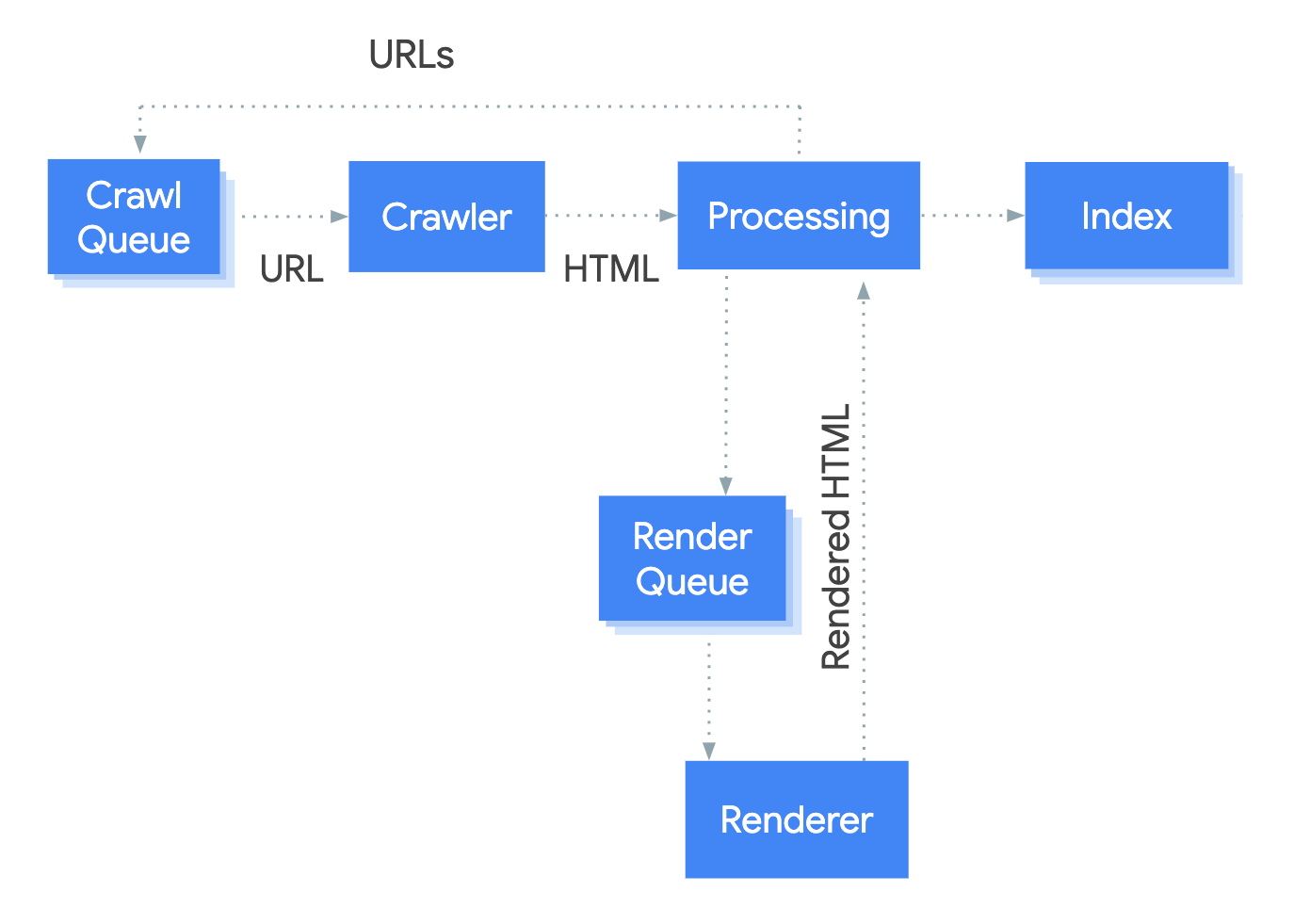
Google Search crawls and parses sites using JavaScript with a headless Chromium that renders the page and executes the scripts. The crawler will send all pages to a render queue, and the headless browsers will send back the response for indexing. More information on how to dynamically add schema markup using JavaScript can be found directly on Google Search Central.
How to add JSON-LD markup to your web pages?
There are typically three ways:
- Using a Plug-in that will do it for you (whether you are on WordPress or any other Web CMS a plug-in is an extension that will add the markup to the HTML of your templates).
- By adding it manually in the HTML code of the templates and here, we might: – adding it within the page’s HEAD section – adding it anywhere else.
- Dynamically using a tag manager such as Google Tag Manager, Adobe Tag Manager or a custom script. Tag managers are tools that allow marketers to inject JavaScript code without the need to update the HTML code of the templates. This is great because it doesn’t require the development team to get involved but, it also might lead to trouble, and it’s always crucial to validate your implementation. To give you an example, Google Search might not see a custom JS that gets deferred (loaded after everything else). Rendering resources are limited and if scripts are not executed in a timely fashion simply they won’t get processed.
I have added a JSON-LD, how can I check if Google is indexing it?
You can essentially review your implementation using Google Search Console, the Rich Result Test tool, or the Schema Markup Validator available under the schema.org domain. Let’s see how.
1. Use the Enhancements section in Google Search Console to see if the markup has been processed.
This is as simple as opening GSC, looking at the right markup (i.e. Breadcrumbs), and check the metrics there. While very immediate, this approach is limited to the few supported entity types included in the Enhancements section of GSC. To give you an example, the markup for schema:Person will not appear here even though effectively it can help you rank higher for all personal branded queries.
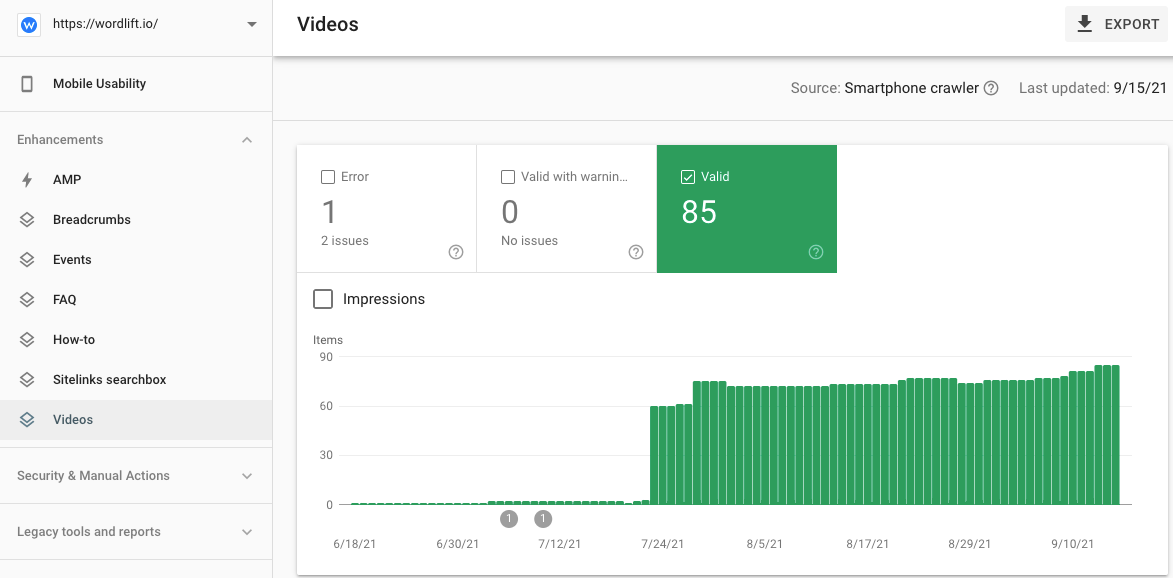
Here is an example of the video tab under GSC’s Enhancements section
2. Use the URL Inspector in Google Search Console to check a specific URL
A more accurate check can be done by using the inspector. Add a URL there and click on “VIEW CRAWLED PAGE”. This will show the HTML that Google has been able to parse and index. By looking at the code, you will be able to see if the structured data is present or not and this, of course, takes into account the dynamic data you might have injected using JavaScript.
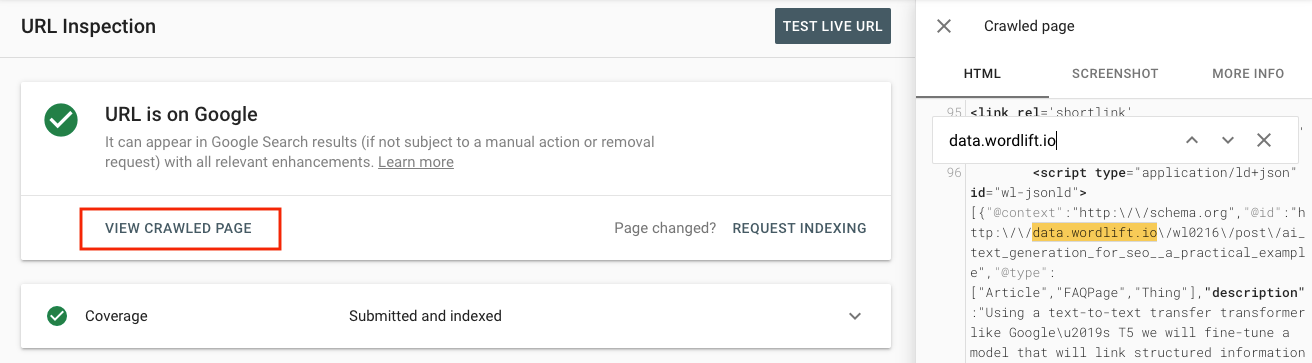
This is the most accurate way to see if Google can index the markup (even when it is added client-side using JavaScript)
3. Use the Rich Result Testing Tool
This is as simple as opening the Rich Results Test, entering the URL you want to test, and checking if you receive the message “Page is eligible for rich results”. The tool is designed to help you see features that will appear on Google’s SERP.

When you want to verify that an entity type that Rich Result Test doesn’t support has been correctly indexed, you can click on If you are testing a structured data type that is not supported by the Rich Results test, “VIEW RENDERED HTML”. If the rendered HTML contains the structured data you have added, Google Search will be able to index it.
4. Use the Schema Markup Validator (SMV)

Also, in this case, you can simply open the tool from validator.schema.org, add the URL and let it run. The beauty of the validator is that it will validate the markup using the rules from the schema.org vocabulary rules, and will cover any schema class and attribute 🤩.
What are the most common pitfalls preventing Google from indexing schema markup?
In general, when structured data is missing, Google hasn’t been able to read it for one of the following reasons:
- The page is not indexable,
- The script doesn’t load (due to other JavaScript errors on the page, to a misconfiguration of the CDN or other factors),
- The script loads too slowly. In this case, Google might not see it; the headless browser might timeout before rendering the code.
The need for constant monitoring of your schema markup. A few solutions.
While checking the first time is crucial, the reality is that websites change all the time and, for various reasons, you might end up losing all the markup. This happens regularly, and the only way to prevent it is to monitor it.
1. Monitoring structured data using your favourite crawler
If structured data markup is present on a webpage, it can be checked programmatically. Here I have linked the instructions for:
2. Run your own crawler in Python and extract the markup
![]()
If Python 🐍 is your friend, I have prepared for you a Colab that you can use to scan the sitemap of your website and extract the markup. It uses Elias Dabbas‘s fantastic Advertool library, and here is how it works. We begin by installing the libraries and setting the site’s sitemap that we like to monitor.

We will read the sitemap and, with a simple instruction, create a dataframe from it. We can use this newly created dataframe (called “sitemap”) to run the crawler using the column that contains the url (called “loc”). When doing so we store the data on a JSON text file called output_file.jl.
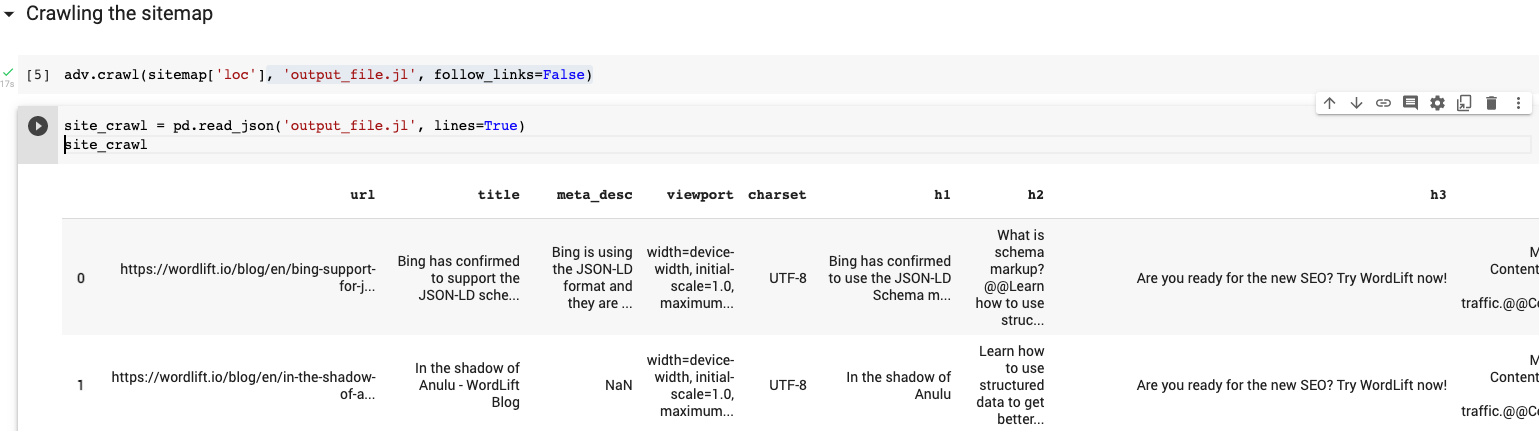
This contains all sorts of information that advertools extracted from each URL but we will focus on a few columns that contain the extracted structured data.
We first convert the json file to a new pandas data frame (called “site_crawl”) using the following command:
site_crawl = pd.read_json('output_file.jl', lines=True)
And then select the attributes we want to monitor. In this specific example, for each URL, we will store the entity type and the context (“url“, “jsonld_@context“, “jsonld_1_@type“)
By doing so, we can immediately check what entity types we’re using on the website (see the chart below), but we can also run a quick comparison between the numbers of URLs we have in the sitemap and the number of URLs that contain the schema markup.
Now, as you can easily guess, this information can be stored on a database (or on Google Sheets) every day to have ongoing monitoring of your structured data. You can run the code from Colab on a regular basis (here is a link explaining how), or more practically, you can move the script to a cloud environment and run it using cron.

3. WordLift’s inspector to extract and validate your semantic markup
Once again, crawlers are great but do not always correctly extract the markup added using JavaScript to a webpage. When the data is injected on the client-side, we need the crawler to render the web page much like a browser would do. In other words, we’ll need a headless browser Chromium-based that acts just like Google Search. When using, for example, advertools (and the example above in Python) on pages like this great Oxford long sleeve by Oakley 😎 you will not be able to detect the markup. Even though Schema Markup Validator (and Google) do see it.
This is one of the reasons why we have created our own URL inspector. Using the WordLift URL inspector, we can run a monitoring check straight from Google Sheets. As you can see, the inspector extracts the markup and adds a list of the entity classes in Google Sheet.
Our extraction engine can also be used as an API in any workflow, this is actually how we use it under the hood:
https://api.wordlift.io/extract?u=__URL__&ua=__USER_AGENT__
Where __URL__ is the target URL and __USER_AGENT__ is the browser to simulate. The API will return all the structured data found on a URL, being it injected on the server or on the client. Also, the extraction supports several formats like JSON-LD, microdata, RDFa, and more.
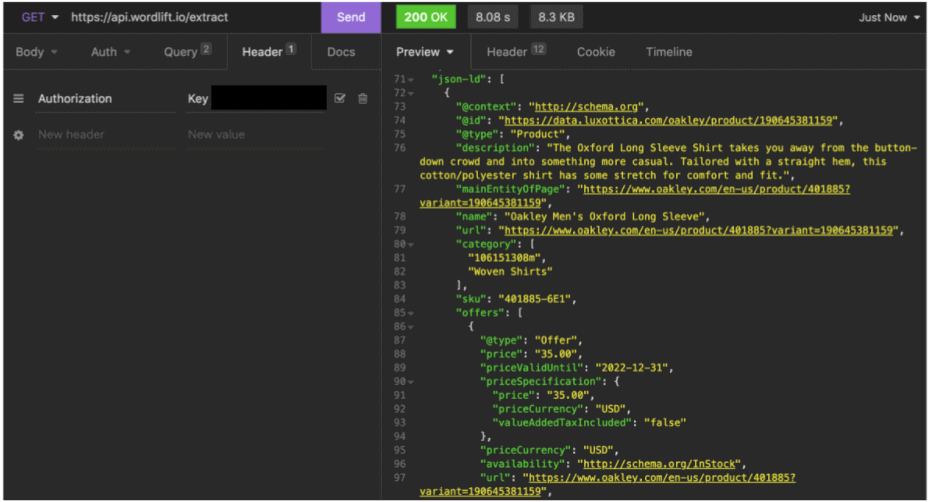
Here is the JSON-LD (that has been added using Javascript) as detected by WordLift’s extract API
To use the API you’ll need a key.
Want to learn more about scaling your structured data markup? Are you interested in monitoring and validating your structured data? Contact us, and we’ll be happy to assist you.