Future-Proofing Your Content: An Ontology-Driven Approach to Train Your Next SEO Agent
Learn how an ontology-driven strategy can future-proof your content and power the next generation of SEO agents with contextual intelligence.

“You Are Bigger Than SEO” — and So Is Every Other Domain
Rand Fishkin’s opening line at iPullRank’s inaugural SEO Week New York — “You Are Bigger Than SEO” —struck a chord. Rand is absolutely right. His point stretches well beyond search: AI is transforming every knowledge domain, and the only safe path forward is to evolve.
The Intelligence Layer Is Shifting
We’re witnessing a fundamental transformation. By February 2027, AI agents will guide over $1 trillion in annual global e-commerce purchases—representing 10-15% of the $9-10 trillion market. Your next client isn’t human; it’s an AI agent.
Gartner calls this transition SEO 3.0: classic search results give way to agentic experiences where autonomous systems discover, judge, and transact. If we want to remain visible and trustworthy, we must design content and data that these agents can interpret — not just index.

System 1 Meets System 2: The Future of AI Reasoning
In cognitive psychology, we distinguish between System 1 (fast, automatic thinking) and System 2 (slow, deliberate reasoning). Current AI excels at System 1—pattern matching and instant responses. But real expertise requires System 2: the ability to reason, reflect, and connect concepts meaningfully.
Key Characteristics of Reasoning LLMs
Reasoning models generate a structured chain of thought before formulating a response.
- Deliberate Processing: Unlike standard LLMs that generate responses instantly, reasoning models can “pause” to consider multiple approaches or verify their own responses
- Chain-of-Thought Enhancement: They naturally develop structured reasoning chains without requiring specific prompting techniques
- Self-Correction: These models can detect and correct their own errors through internal reasoning processes
- Emergent Capabilities: Through reinforcement learning, they develop reasoning abilities that weren’t explicitly programmed
Models like DeepSeek-R1 and Microsoft Phi-4-reasoning are pioneering this evolution. DeepSeek shared with the broader audience how reinforcement learning can develop emergent reasoning capabilities, while Phi-4-reasoning shows that smaller models can rival larger ones through specialized training approaches. These innovations prove that the breakthrough isn’t about model size—it’s about teaching AI systems to combine System 1’s efficiency with System 2’s depth.
The Domain Knowledge Challenge
Large language models can process text, but they struggle with the nuances that make expertise valuable. This challenge extends beyond SEO and marketing to medicine, law, engineering, and every field where relationships and context matter.
At WordLift we’ve long used knowledge graphs and ontologies to ground content and drive our AI SEO Agent. The next step was clear: teach models with structure, not just data.
Introducing SEOcrate — A Recipe for Domain‑Aligned Reasoning
SEOcrate 01 (SEOcrate_4B_grpo_new_01), now available on Hugging Face, is our proof‑of‑concept: a 4‑billion‑parameter model trained to reason like a seasoned SEO analyst. Although still an early prototype, it demonstrates something striking — a compact, highly efficient model can, through ontology guidance and reinforcement‑based rewards, deliver performance that approaches the practical utility of far larger systems such as GPT‑4o.
| Layer | Role | Key Component |
|---|---|---|
| Foundation | Fast System 1 language ability | Gemma 3 4B (4‑bit, via Unsloth) |
| Structured Knowledge | Formal SEO concepts & relations | SEOntology (seovoc) |
| Learning Strategy | Teach “how to think”, not “what to say” | Ontology‑Guided Reinforcement Learning using GRPO |
| Quality Gate | Reward correct reasoning paths | LLM‑as‑Judge (Gemini 1.5 Pro) |

Building on the innovations from DeepSeek-R1, Phi-4-reasoning, and o1, we’re asking different questions: How do we create reasoning models aligned with specific knowledge domains? How do we effectively combine System 1’s efficiency with System 2’s depth within domain constraints?
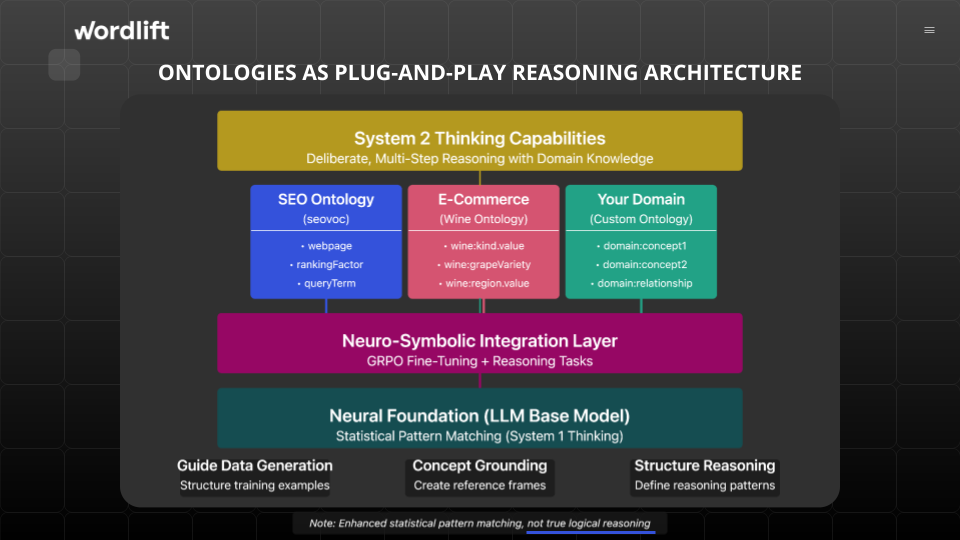
Our answer is SEOcrate—a 4-billion parameter model trained through ontology-guided reinforcement learning. The name spells like “Sòcrate” (the Greek philosopher), blending SEO expertise with deep reasoning. Available on Hugging Face (https://huggingface.co/cyberandy/SEOcrate-4B_grpo_new_01), SEOcrate demonstrates how domain-specific ontologies can teach AI systems to reason like SEO experts rather than just pattern-match.
This proof-of-concept shows that ontology-driven training can achieve breakthrough performance with minimal resources. It’s not about the size of the model—it’s about the structure of its learning.
A Glimpse at What’s Possible
The difference between pattern matching and domain expertise becomes clear when we compare how AI systems make recommendations.
Standard AI systems lack contextual judgment: they provide generic SEO advice drawn from statistical patterns without understanding why certain strategies work in specific contexts. When pressed to explain their reasoning, they fall back on memorized correlations, unable to adapt when nuances or edge cases arise. Traditional AI agents face a fundamental dilemma: they either follow rigid decision trees (losing adaptability) or make unexplainable choices based on pattern matching. SEOcrate solves this by using ontological reasoning to make tool selection both strategic and transparent.
Domain-aligned AI operates differently: it reasons through ontological relationships, explaining why schema markup enhances semantic understanding in your specific content context. It transparently shows its decision-making process, connecting each recommendation to verified domain principles. Crucially, it selectively applies the right tools for each challenge, guided by structured knowledge rather than probabilistic patterns.
This is where human expertise becomes irreplaceable. Domain experts don’t just label data—they shape the ontological core that defines how AI agents reason. By curating concepts, relationships, and inference rules, human experts control which tools agents use and how they navigate complex decisions. The result? AI systems that augment human judgment rather than compete with it.
The Road Ahead
While knowledge graphs and ontologies have laid the groundwork for semantic search, SEOcrate represents the next frontier: training AI agents to reason within domain constraints. The full methodology—combining ontology design, reinforcement learning, and human expertise—offers a blueprint for organizations ready to move beyond traditional SEO.
This isn’t about replacing human intelligence—it’s about creating systems that amplify it. As AI agents become primary decision-makers in search and commerce, the organizations that can train domain-aligned AI will have a crucial advantage. The future belongs to those who recognize that structured knowledge, guided by human experts, is the foundation for trustworthy AI reasoning.
Acknowledgments
This work wouldn’t exist without:
- Google Cloud for providing the computational resources through their credits program
- Unsloth AI for making quantized Gemma 3 4B accessible
- Knowledge Graph Conference for hosting our presentation
- iPullRank for creating an inspiring platform for exchange at SEO Week
Rand was right—you are bigger than SEO. Together, we can ensure AI reasoning aligns with human expertise.