The Hidden Entity Layer of ChatGPT: From Named Entities to Products
A deep dive into ChatGPT’s hidden semantic layer. By analyzing its SSE streams, we uncover how OpenAI’s web client structures entities, moderates outputs, and connects to a product graph that mirrors Google Shopping feeds.

What Lies Beneath ChatGPT’s Interface
In my previous exploration, The OpenAI Emerging Semantic Layer, I started to review how GTP-5 organizes knowledge beneath the surface, not through keywords, but through entities.
This time, I took a closer look at the Server-Sent Event (SSE) streams that power ChatGPT’s responses, inspired by the insights shared by the team at PromptWatch.
By recording, parsing, and analyzing these real-time data flows, I uncovered a hidden layer of entity infrastructure that extends far beyond language understanding, now encompassing products, organizations, people, and even moderation logic.
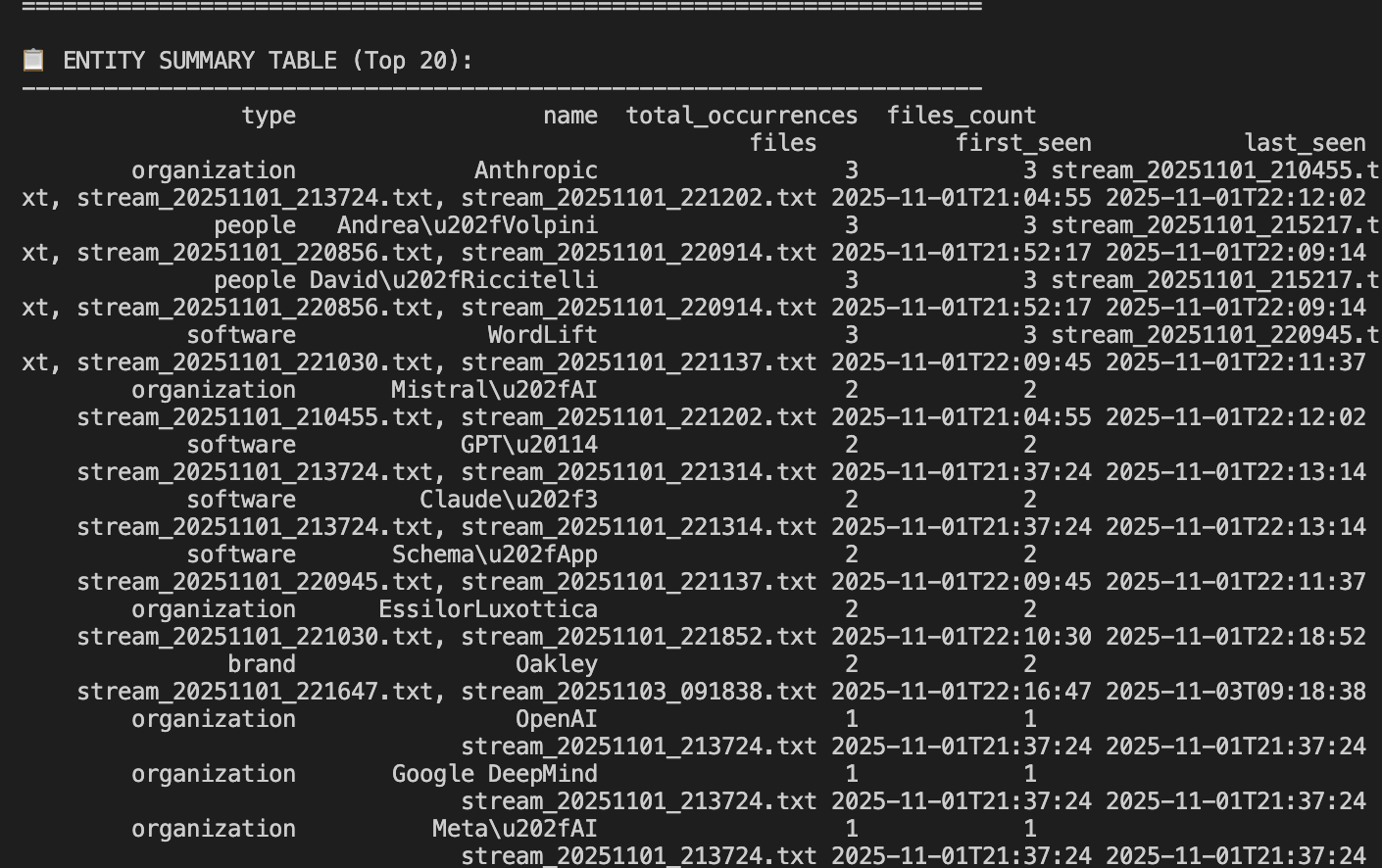
How ChatGPT Streams Knowledge: The SSE Architecture
ChatGPT’s web interface doesn’t operate like an API call that returns a block of text.
Instead, it maintains a persistent streaming connection with the server via the text/event-stream protocol, known as Server-Sent Events (SSE).
Every time ChatGPT “types,” the client receives a flow of structured events.
Each event contains not only the visible tokens of the reply but also a rich metadata payload.
First insight: the payload returned by the OpenAI APIs differs from the metadata structure available in the ChatGPT WebUI; and it also varies between free and paid accounts.
A simplified view of the process:
| Phase | Endpoint | Purpose |
|---|---|---|
| 1️⃣ Moderation | /backend-api/moderations | Checks for policy violations before generation |
| 2️⃣ Generation Stream (SSE) | /backend-api/conversation | Streams assistant responses and internal state |
| 3️⃣ Output Moderation | /backend-api/moderations | Re-evaluates AI output for compliance |
Unlike the public API (/v1/chat/completions), which streams only plain text tokens, the private web interface streams complex JSON objects — containing message IDs, metadata, content types, and hidden annotations.
This is where the “semantic layer” lives.
The Method: Reverse-Engineering the Conversation Stream
I built a custom Playwright-based recorder in Python to intercept and log ChatGPT’s internal /backend-api/conversation SSE stream.
Each event is captured as raw text, decoded, and stored for analysis.
Using pattern recognition and entity extraction, I was able to identify multiple layers of structured data hidden in these streams, including:
- System Entities: Internal identifiers such as
message_id,conversation_id, andend_turn, used by the React frontend. - Moderation Entities: Safety classifications (e.g., self-harm, violence, sexual) retrieved from the moderation endpoint.
- Named Entity Recognition (NER) Layer: Lightweight in-text annotations for
Person,Organization,Event, andLocation. - Product Entities: Structured commerce nodes emitted in product-related conversations.
Importantly, these data structures do not appear in:
- the OpenAI API (
api.openai.com/v1/chat/completions), - nor in the free ChatGPT tier (which uses a different backend).
They are exclusive to the ChatGPT web and paid tiers, where richer data pipelines are active.
Inside the Entity Layer
At the heart of the stream, I found that every conversational turn embeds entity placeholders that look like this:
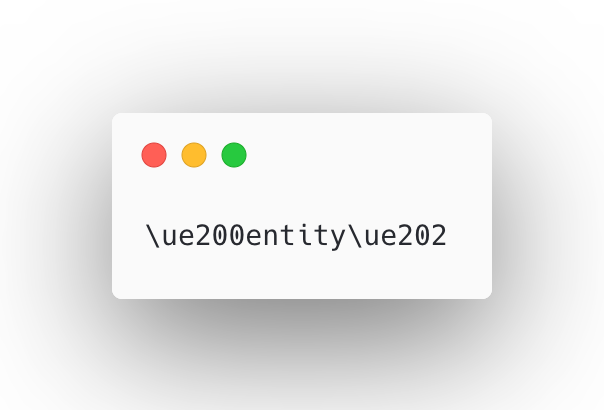
Each placeholder is then replaced dynamically by an object of a specific type —
for instance, organization_entity, person_entity, or event_entity.
This allows ChatGPT to build context-aware memory anchors across turns. When you ask, “What is WordLift?” and then follow with “Who founded it?”, the system already has a reference to the organization entity WordLift in memory.
ChatGPT Entity Classes
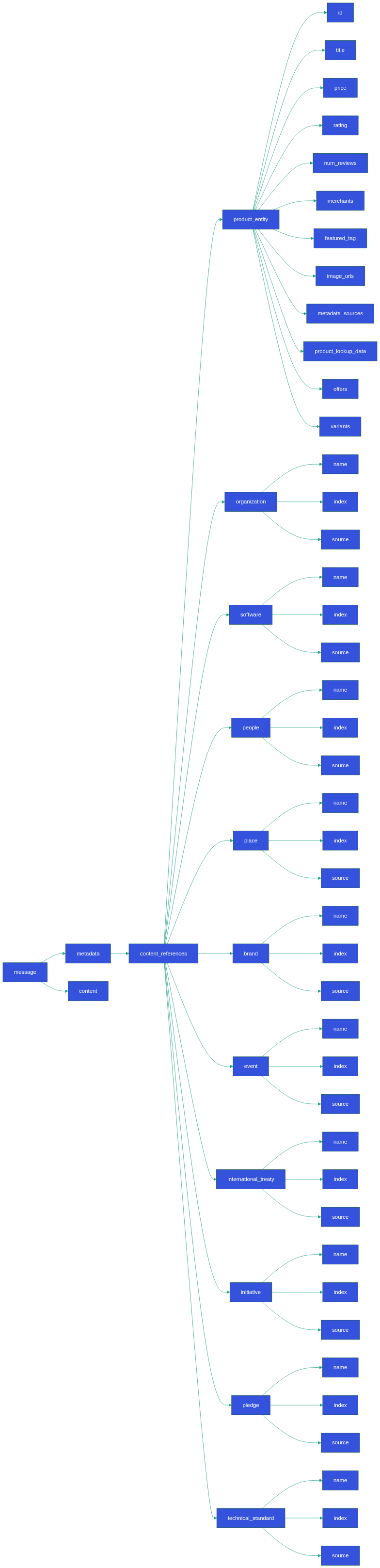
| Type | Description | Purpose |
|---|---|---|
entity | Generic placeholder for untyped entity references | Lightweight mention linking |
person_entity | Individuals, founders, public figures | Used in biographies and relationships |
organization_entity | Companies, institutions | Used for corporate and contextual queries |
event_entity | Events, conferences, historic moments | Temporal grounding |
product_entity | Products, devices, commercial items | Structured product layer for commerce |
moderation_entity | Policy categories (violence, hate, etc.) | Internal safety classification |
Each component serves a specific purpose in how ChatGPT organizes, filters, and enriches its responses. Beyond inference, these entities may also hold value for pre-training tasks, forming the semantic layer that characterize every conversation.
The Product Knowledge Graph of ChatGPT
If you follow our work on agentic commerce and product feeds, this section will feel like the next logical step. Building on:
I was able to analyze the product_entity objects. They behave differently from other entity types: instead of just being named references, they carry fully structured product metadata, much like a JSON-LD Product object.
Here’s a simplified example extracted from the stream:
{
"id": "2997526925583449256",
"title": "Bialetti Moka Express (classic size)",
"price": "€23.90",
"rating": 4.7,
"num_reviews": 5900,
"merchants": "Unieuro + others",
"featured_tag": "classic everyday model",
"image_urls": ["https://...jpg"],
"metadata_sources": ["p2"]
}
Key findings:
- Product IDs are 18–20 digit numeric codes — matching Google Shopping catalog IDs, not GTINs.
- All product URLs are empty strings — ChatGPT renders them internally, without external navigation.
- The provider field (
"p2") is consistent — suggesting a single, centralized product data source.
These objects represent a hidden product graph, connecting user intent to structured commerce data — effectively turning ChatGPT into a semantic front-end for product discovery.
Why These Entities Matter
The presence of entity annotations and product schemas inside the ChatGPT stream indicates a shift from generative text toward structured reasoning.
This architecture enables:
- Context persistence across turns (via entity IDs).
- Memory-level grounding (via internal references).
- Hybrid search + reasoning (via entity-typed nodes).
- Commerce experiences (via the
product_entitylayer).
In other words, ChatGPT’s semantic layer functions like a private, evolving knowledge graph, updated in real time as users interact with the model.
SSE entities reveal how the UI reasons in terms of typed nodes. Publishing the matching Schema.org JSON-LD makes those same nodes machine readable for AI search and shopping. Use the table below to translate each SSE entity into concrete markup, then the product attribute map to wire your feeds.
SSE entity → Schema.org map
| SSE entity class | Primary Schema.org type | Key JSON-LD properties to include | Where it helps |
|---|---|---|---|
| person_entity | Person | name, sameAs, url, image, jobTitle, worksFor | Author panels, citations, E-E-A-T surfaces |
| organization_entity | Organization | name, url, logo, sameAs, brand, contactPoint | Brand cards, site links, knowledge answers |
| place_entity | Place or LocalBusiness | name, address, geo, openingHours, telephone, sameAs | Local AI results, maps, travel panels |
| event_entity | Event | name, startDate, endDate, location, organizer, offers | What’s on, ticketing answers |
| brand_entity | Brand | name, url, logo, sameAs, aggregateRating | Product clustering, brand overviews |
| product_entity | Product + Offer | name, description, image, brand, color, material, weight, category, inProductGroupWithID, sku, gtin*, isVariantOf; offers.price, offers.priceCurrency, offers.availability, offers.itemCondition, offers.inventoryLevel | AI shopping answers, price and availability, product comparisons |
Product attribute map
Mapping detected attributes and ChatGPT Shopping feed fields to Schema.org for the example item.
| Feed field or detected attribute | Example value | Schema.org property | Notes |
|---|---|---|---|
| id | shopify_US_9020023177513_47811512729897 | sku | Use variant id as sku |
| item_group_id | shopify_US_9020023177513 | inProductGroupWithID | Stable group id across variants |
| title | Slim Ski Bag Martian Red | name | Keep variant-level name |
| description | Travel light and stylishly… | description | Plain text preferred |
| link | https://myblackbriar.com/… | url | Canonical PDP URL |
| image_link | https://cdn.shopify.com/…png | image | Array supports multiple images |
| additional_image_link[] | …01.jpg, …03.jpg | image | Append to image array |
| price | 199.99 USD | offers.price and offers.priceCurrency | priceCurrency from suffix |
| sale_price | 163.99 USD | offers.priceSpecification or a second Offer | Use UnitPriceSpecification or separate Offer for sale |
| availability | in_stock | offers.availability | Map to InStock, OutOfStock, PreOrder |
| inventory_quantity | 2 | offers.inventoryLevel | QuantitativeValue with value 2 |
| condition | new | offers.itemCondition | NewCondition, UsedCondition, etc. |
| brand | Black Briar USA | brand.name | Wrap in Brand object when possible |
| color | Martian Red | color | Free text ok |
| material | N/A | material | Omit if unknown |
| weight | 10 lb | weight | QuantitativeValue if you can parse unit |
| product_category | luggage & bags > backpacks | category | Use your site taxonomy or GPC |
| age_group | adult | audience.audienceType | Or PeopleAudience with audienceType |
| gender | unisex | audience.suggestedGender | Or audienceType “unisex” |
{kind=link}
The Limits of Access: Why You Won’t See It in the API
The public OpenAI API — even with streaming enabled — provides only lightweight text deltas (choices[].delta.content).
It does not expose any of the rich metadata, entity references, or moderation categories visible in ChatGPT’s private SSE stream.
This means:
- Developers using the API are working with surface-level tokens, not the structured entity layer underneath.
- The richer layer is reserved for OpenAI’s own interfaces, such as ChatGPT and GPTs.
- The free ChatGPT version also lacks this infrastructure; the entity layer is observable only in paid or “Pro” tiers.
This reinforces that ChatGPT is not just an interface to a model — it’s an orchestrated system combining models, moderation services, entity linkers, and product indexes.
From Knowledge Graphs to Product Graphs
We now see the semantic layer evolving in real time: from basic NER to structured product representation.
The pattern is unmistakable:
OpenAI is aligning its internal knowledge representation with web-standard ontologies like Schema.org and GS1, creating a private, operational Product Graph.
This has deep implications for SEO, e-commerce, and digital marketing.
For brands and publishers, the only way to appear in this new conversational economy is to publish structured, machine-readable data.
WordLift’s mission, to make content and products understandable by machines, has never been more relevant.
Conclusion: The Rise of the Semantic Infrastructure
ChatGPT’s entity layer is not theoretical; it’s operational.
From people to products, it builds a real-time knowledge graph beneath every conversation.
And just like the web, it relies on structured identifiers, metadata, and linked data patterns to function.
This new layer is invisible in the API, absent in the free version, and yet central to how modern AI systems perceive, reason, and recommend.
It’s the missing semantic infrastructure that connects human language to machine understanding, and soon, to transactions.
We are witnessing the birth of the reasoning web, where every entity, from a person to a product, becomes a structured node in a machine-readable conversation.
Note on methodology
I captured ChatGPT’s Server-Sent Events (SSE) from the web client using Playwright’s request routing. The script below logs the full SSE payload to disk and extracts the internal content_references blocks into JSON. This is a point-in-time, UI-level observation for research. Only record your own sessions, avoid sensitive prompts, and respect the site’s Terms of Use and your local laws. Entity field names and shapes can change without notice. The code of the recorder is available on Gist.