How knowledge graphs can help your travel brand attract more visitors

For the first time this year we can finally say that knowledge graphs and semantic technologies are hype. People like me, who played with the semantic web stack for several years now, have long predicted that one day we would have a Graph for Everything. We did wait for long and hopefully not in vain ? until recently Gartner finally shout out loud that 2018 is indeed the “Year of the Graph”. We, here at WordLift, are far beyond the hype. We have built technologies, open source frameworks, companies and products on this vision of semantic web, knowledge representation and ontologies.

For many years, way too many, talking with large enterprises or public institutions like the Italian Parliament about the importance of creating taxonomies and labeling information has been extremely frustrating, and yet I am very thankful to everyone who has listened to me and helped us get to the point of writing an article like this one.
Knowledge graphs are real and bring a competitive advantage to large enterprises like Amazon, Google, LinkedIn, Uber, Zalando, Airbnb, Microsoft, and other internet powerhouses but no, this article is not about giant graphs from large enterprises. It is about our direct experience in helping travel brands like bungalowparkoverzicht in the Netherlands, the largest tour operator in Iceland and SalzburgerLand in Austria.
[box]
WHAT IS A KNOWLEDGE GRAPH?
A knowledge graph is a way of representing human-knowledge to machines. In short, you start by defining the main concepts as nodes and the relationships among these concepts as edges in a graph. READ MORE
[/box]
Not all Graph are created equal and each organization has its own business goals and ways of representing relationships between related entities. We model data and build knowledge graphs to create a context, to improve content findability by leveraging on semantic search engines like Google and Bing and to provide precise answers to certain questions. When you have organized your data semantically and you have built your own taxonomy there are many applications that can be implemented: from classifying items to integrating data coming out of different pipelines, from building complex reasoning systems, to publishing metadata on the web. When we built the knowledge graph for a travel brand like bungalowparkoverzicht our main focus was on the type of information that a traveler would need before reaching the destinations.
We model data for the so-called “planning and booking moments”. Planning, accordingly to a research from Google, starts when a digital traveler has chosen a destination and is then looking for the right time and place to stay. Then the booking will follow, and that’s the moment when the travelers move into reserving their perfect hotel, choose a room and reserve it.
Types of Information to model for the planning and booking moments
When modeling hotel-related information in Web content using the schema.org vocabulary you basically work with three core type of nodes (entity types):
- A lodging business, (e.g. a hotel, hostel, resort, or a camping site): essentially the place and local business that houses the actual units of the establishment (e.g. hotel rooms). The lodging business can encompass multiple buildings but is in most cases a coherent place.
- An accommodation, i.e. the actually relevant units of the establishment (e.g. hotel rooms, suites, apartments, meeting rooms, camping pitches, etc.). These are the actual objects that are offered for rental.
- An offer to let a hotel room (or other forms of accommodations) for a particular amount of money and for a given type of usage (e.g. occupancy), typically further constrained by advance booking requirements and other terms and conditions.
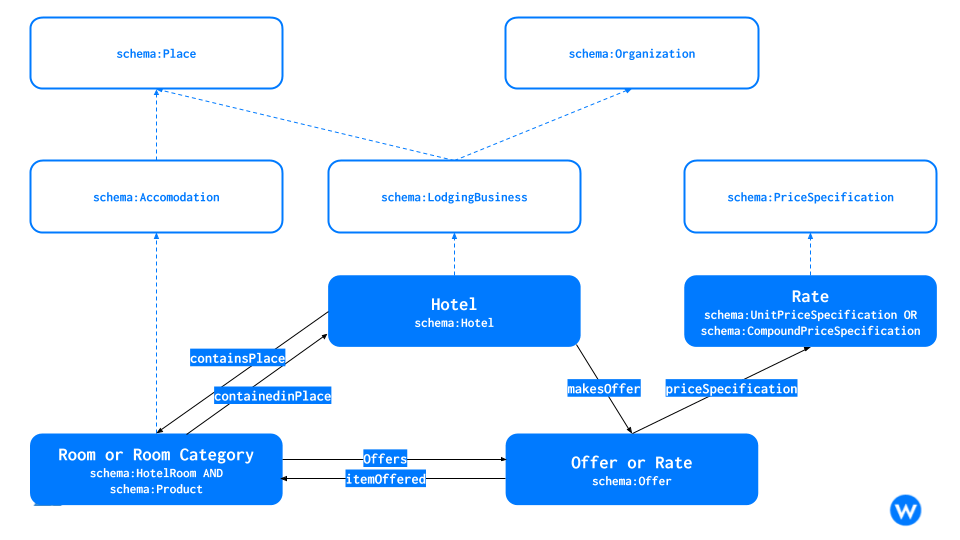
Relationships (edges in the graph) between these entities are designed in such a way that several potential conversations between a lodging business and a potential client become possible. We simply:
a) encode these relationships using an open vocabulary and, by doing so,
b) easily enable search engines and/or virtual assistants to traverse these connections in multiple ways.
As seen above we can map – using the vocabulary – all the hospitality infrastructures as schema:Organization and create a page listing all the different companies behind these businesses or we can list these hotels and lodging facilities using their geolocation and the properties of the schema:Place type.
Making it happen
The content management system in the back-end uses a relational database, and this is just great as most of the data needs to be used with transactional processes (versioning, reviews are all based on efficiently storing data into tables). Our work is to apply to each data-point the semantics required to:
- publish metadata on the web using structured data that machines can understand
- index each item of the property inventory (i.e. all the proposed hotels, all the locations, …) with a unique identifier and a corresponding representation in an RDF knowledge graph
- semantically annotate editorial content with all the nodes that are relevant for our target audience (i.e. annotating an article about a camping site in the Netherlands with the same entity that connects that location with the related
schema:LodgingBusiness) - have a nice and clean API to query and eventually enrich the data in the graph using other publicly available data coming from Wikidata, GeoNames or DBpedia
- provide search engines and virtual assistants with the booking URL using
schema:ReserveAction(see the example below) to make this data truly actionable.
1. Publishing metadata on the Web: data quality becomes King
Since major search providers (including Google, Microsoft, Yahoo, and Yandex) joined forces to define a common language for semantic markup, semantic web technologies became an important asset of online business of all sort. At the time of writing this article, 10 million websites use Schema.org to mark up their web pages.
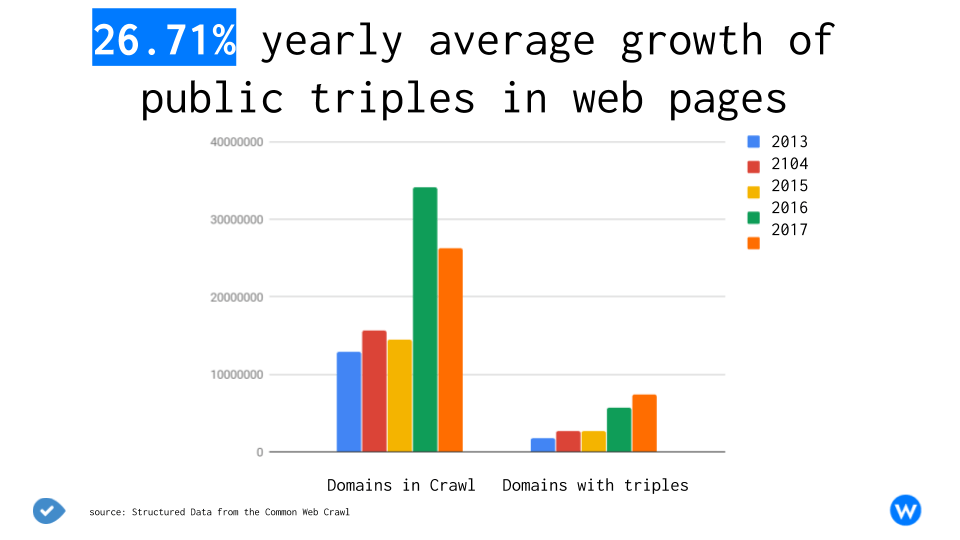
While there is a growing interest in adding structured data in general, the focus is now shifting from providing whatever form of structured data to providing high-quality data that can have a real impact on the new entity-oriented search.
[box]
WHAT IS ENTITY-ORIENTED SEARCH?
Entity-oriented search, as defined by Krisztian Balog in his book, is the search paradigm of organizing and accessing information centered around entities, and their attributes and relationships.
[/box]
Ranking high on long tail intents like the ones we see in the travel sector is – in several cases – about providing consistent and reliable information in a structured form.

The importance of geocoding the address
To give you a practical example, when making explicit the data about the address of the lodging business for the Dutch website, we realised that the data we had in the CMS wasn’t good enough to be published online using schema and we decided to reverse geocode the address and extract the data in a clean and reliable format, using an external API. A simple heuristic like this one improves the quality of the data describing thousands of lodging businesses that can now be unambiguously ranked for various type of searches.
Using well-known datasets to disambiguate location-specific characteristics
In schema, when describing most of the hotel-related types and properties – e.g. telling hosts that the hotel might have a WiFi Internet connection – we can use the amenityFeature property that is derived from the STI accommodation ontology (our friends in Innsbruck at the Semantic Technology Institute that have greatly contributed to the travel extension of Schema).
Unfortunately, there is not common taxonomy yet for describing these properties (the wifi or the presence of a safe in the room). In order to help search engines and virtual assistants disambiguate these properties at best, in WordLift we’re providing a mapping between these hotel-related properties and entities in Wikidata. In this way, we can add an unambiguous pointer to – let’s say – the concept of WiFi, that in Wikidata corresponds to the entity Q29643.
2. Creating unique IDs for entities in the graph
When representing the nodes in our graph we create entities and we group them in a catalog (we call it vocabulary). All the entities we have in the catalog belong to different types (i.e. Lodging business, Organization, Place, Offer). The entity catalog defines the universe we know and each entity has its own unique identifier. The fact that we can have an ID for each node turns out to be surprisingly useful as it allows us to have a one-to-one correspondence between a node (represented by its ID) and the real-world object it represents.
An accommodation like the Strand Resort Ouddorp Duin in the South of Holland, for example, has its own unique ID in the graph on http://data.wordlift.io/wl0760/vakantiepark/strand_resort_ouddorp_duin.
3. Bridging text and structure
Combining structured and unstructured information is key for improving search breadth and quality from external search engines like Google and Bing. It also becomes very important to provide a consistent user experience within the site. Let’s say that you are referring, in an article from the blog, to South of Holland or to the Landal Strand Resort we talked about before: you want your users to see the latest promotions from this resort and/or offers from other properties nearby. Connecting editorial content from the blog using the data in the graph is called entity-linking. It is done by annotating mentions of specific entities (or properties of these entities) being described in a text, with their own unique identifiers from the underlying knowledge graph. This creates a context for the users (and for external search engines) and a simple way to improve the user experience by suggesting a meaningful navigation path (i.e. “let’s see all the resorts in the region” or “let’s see the latest offers from the Strand Resort”).

4. Discovering new facts by linking external data
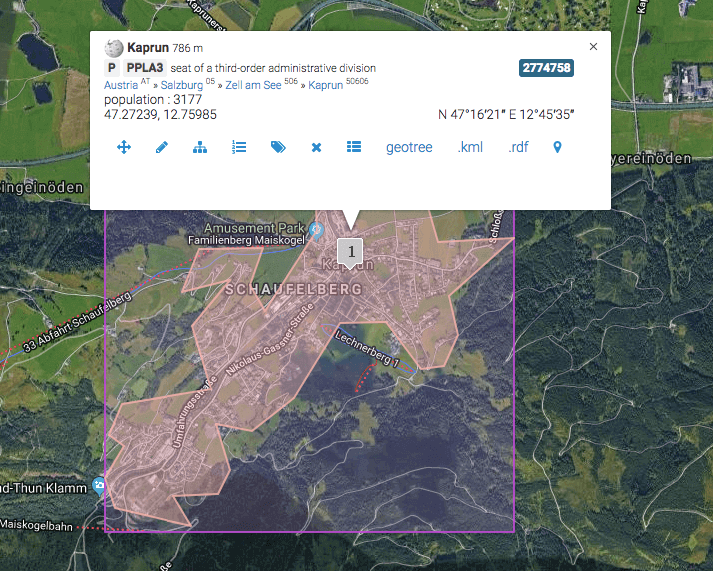
Having a graph in RDF format is also about linking your data with other data. A great travel destination in Salzburgerland like Kaprun has its own entity ID in the graph http://open.salzburgerland.com/en/entity/kaprunbuilt by the Region of Salzburg using WordLift. This entity is linked with the equivalent entities in the Web of data. In GeoNames it corresponds to the entity http://sws.geonames.org/2774758/ (GeoNames is a freely available geographical database that contains a lot more properties about Kaprun that what we store in our graph). We can see from GeoNames that Kaprun is 786m above sea level and belongs to the Zell am See region in Salzburgerland. These informations are immediately accessible to search engines and can be also stored in the index of the website internal search engine to let users find Kaprun when searching for towns in Zell am See or destination in Salzburgerland close to a lake. This wealth of open data, interlinked with our graph, can be made immediately accessible to our users by adding attributes in Schema that search engines understand. An internal search engine with these information becomes “semantic” and we don’t need to maintain or curate this information (unless we find it unreliable). Wow!
[box]
WHAT IS RDF?
The Resource Description Framework (RDF), is a W3C standard for describing entities in a knowledge base. An entity such as a hotel can be represented as a set of RDF statements. These statements may be seen as facts or assertions about that entity. A knowledge graph is a structured knowledge repository for storing and organizing statements about entities. READ MORE
[/box]
5. From answering questions to making it all happen: introducing Schema Actions
We use nodes and edges in the graph to help search engines and virtual assistants answer specific questions like “Where can I find a camping site with a sauna close to a ski resort in Germany?”. These are informational intents that can be covered by providing structured data using the schema.org vocabulary to describe entities.
In 2014 Schema.org, the consortium created by the search engines to build a common vocabulary introduced a new extension called Actions. The purpose of Schema Actions is to go beyond the static description of entities – people, places, hotels, restaurants, … and to describe the actions that can be invoked (or have been invoked) using these entities.
In the context of the knowledge graph for a travel brand, we’re starting to use Schema Actions to let search engines and virtual assistants know what is the URL to be used for booking a specific hotel.
Here is an example of the JSON-LD code injected in the page of a camping village providing the indication of the URL that can be used on the different devices (see the attribute actionPlatform) to initiate the booking process.
"potentialAction": {
"@type": "ReserveAction",
"target": {
"@type": "EntryPoint",
"urlTemplate": "/boek/canvas-belvedere-village/",
"inLanguage": "nl-NL",
"actionPlatform": [
"http://schema.org/DesktopWebPlatform",
"http://schema.org/IOSPlatform",
"http://schema.org/AndroidPlatform"
]
},
"result": {
"@type": "LodgingReservation",
"name": "Reserveren of meer informatie?"
}
}
Next steps and final thoughts
As we’re continuing to explore new ways to collect, improve and reuse the information in the knowledge bases we are building with our clients in the travel industry, a new landscape of applications is emerging. Data is playing a pivotal role in the era of personal assistants, content recommendations and entity-oriented search. We are focusing on making knowledge as explicit as possible inside these organizations, to help searchers traverse it in a meaningful way.
The semantic web is a branch of artificial intelligence specifically designed to transfer human knowledge to machines. Human knowledge, in the travel sector, is really what creates a concrete business value for the travelers.
When planning for a next vacation we are constantly looking for something new, sometimes even unusual, but at the same time we need full reliability and we want to complete the planning and booking process in the best possible way, and with the least amount of effort.
For travel brands, destinations, online travel agencies, and resorts building a knowledge graph is truly the best way to improve the traveler experience, to market the travel offers and to prepare for the “AI-first world” of voice search and personal assistants.
Are you ready to build your travel-oriented knowledge graph? Contact us
Credits
Thanks to Rainer Edlinger and Martin Reichhart that this year invited me to the Castel Kamp in Kaprun where every year the travel community from Austria, Germany, and Südtirol gathers to share their experiences, best practices and challenges in the digital marketing world. I have been also very happy to meet again Reinhard Lanner with whom I started this journey back in 2014. A great “Grazie” also to our wonderful team that is constantly working to improve our technology and to help our clients get the most out of our stack.
Feel free to connect if you want to know more about SEO for travel websites and if you have any more questions about my experience with Knowledge Graphs for your travel brand!