Do We Need LLM For Every Query? Separating Discovery from Ranking in the Era of Agentic RAG
Optimize Agentic RAG by separating discovery from ranking. Learn how RLM-on-KG and selective escalation scale Knowledge Graph search performance.


The era of ‘static’ AI is ending. We’ve all seen what happens when you ask a standard AI a complex question: it either misses the point or gets lost in the weeds. Even with the recent evolution of AI Search models capable of much deeper analysis – such as the Higher-Quality Verification in GPT 5.4, the fundamental problem isn’t necessarily the AI’s ‘brain’; it’s the way it’s being told to find information.
New research into RLM-on-KG (Recursive Language Models on Knowledge Graphs) suggests a smarter way forward. Instead of treating AI as a passive reader of documents, we are turning it into an autonomous navigator that explores data in real-time.
1. The Controller Continuum: Choosing Your Engine
Not every question requires a high-powered AI “navigator.” Sometimes, a simple search is enough. We’ve identified a spectrum of strategies, balancing speed, cost, and capability:
| Controller | Mechanism | Cost | Best For… |
| Vector-only | Simple keyword/semantic match | Low (~2K tokens) | Single-hop facts |
| GraphRAG-local | 1-hop expansion (neighbors) | Low (~2K tokens) | Moderate complexity |
| Heuristic RLM | Rule-based “breadth-first” search | Medium (~5K tokens) | Predictable connections |
| LLM RLM | Adaptive, AI-driven navigation | High (~50K tokens) | Highly scattered evidence |
2. When Is an LLM Navigator Actually Worth It?
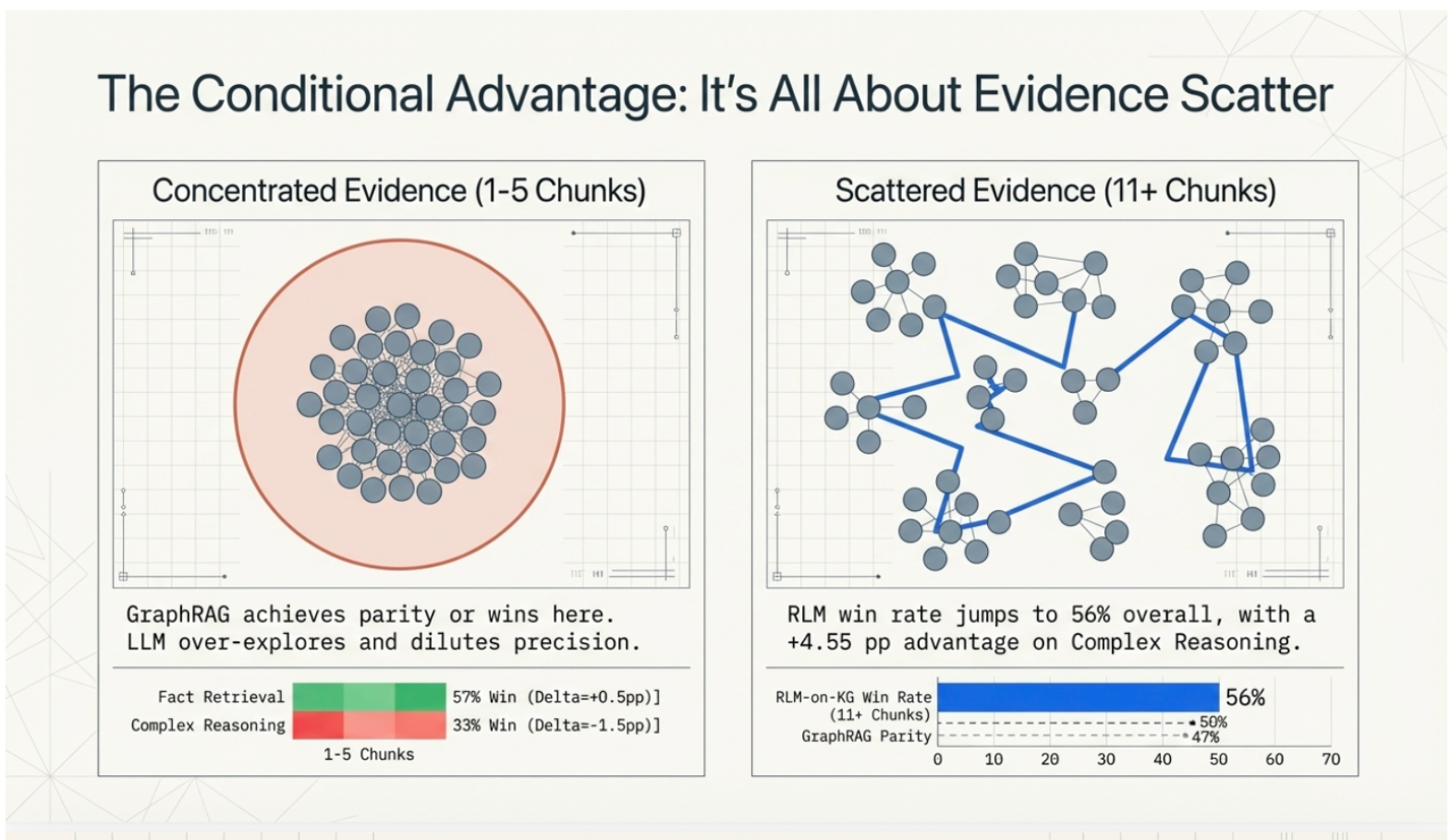
The short answer: When the evidence is scattered.
If the answer to your question is buried in a single paragraph, using a deep-dive AI navigator is like hiring a private investigator to find your car keys in your pocket: it’s a waste of money. However, when “gold evidence” is spread across 6 to 11+ different sections or documents, the AI navigator’s win rate jumps significantly. So, in a nutshell this is the suggested strategy:
- Concentrated Evidence: Use the sub-second, cheaper “static” search.
- Scattered Evidence: Unleash the LLM Navigator to hunt down distant, structurally connected links that traditional search is “blind” to.
3. The Capability Staircase
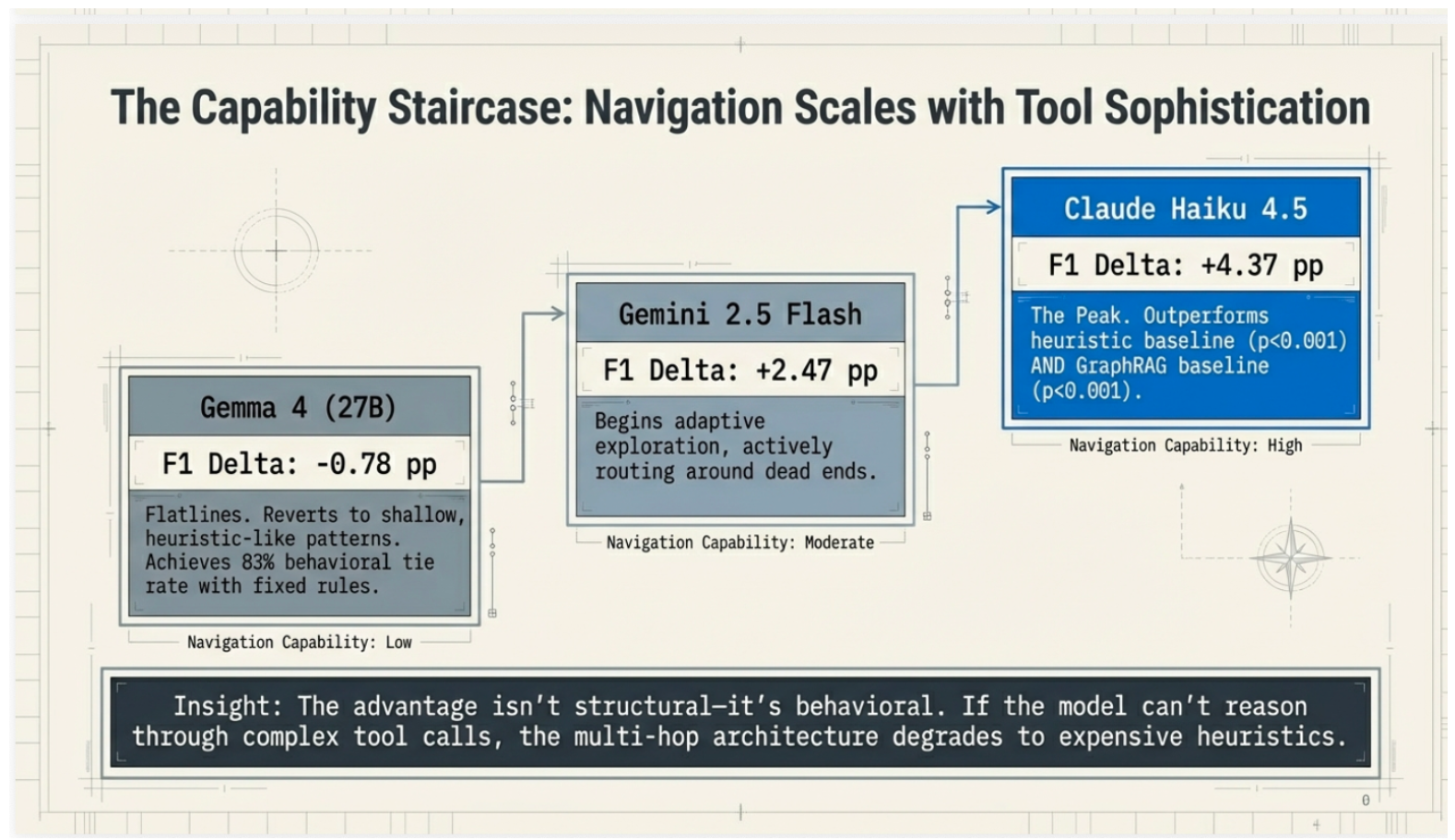
It turns out that navigation is a skill that scales with the intelligence of the model. Not all AI “brains” can handle the wheel:
- The Peak (Claude Haiku 4.5): Currently the gold standard, showing the strongest statistical advantage in finding scattered data.
- The Navigator (Gemini 2.5 Flash): Capable of adaptive exploration and routing around “dead ends” in the data.
- The Flatline (Gemma 4): Smaller models often revert to shallow, rule-like patterns, losing the “adaptive” edge.
4. The Cardinal Rule: Separate Discovery from Ranking
One of the most important lessons from this research is that you shouldn’t ask the AI to do everything. We’ve found that the best results come from a division of labor:
- The AI Explores: Let the LLM use its “intuition” to discover a broad pool of candidate information across the graph.
- The Math Decides: Once the pool is gathered, let pure vector math (cosine similarity) handle the final ranking.
Trying to make the AI handle the final scoring often leads to “noise” and actually degrades performance. Let the LLM explore, but let the vectors decide.
5. Selective Escalation: A Production Blueprint
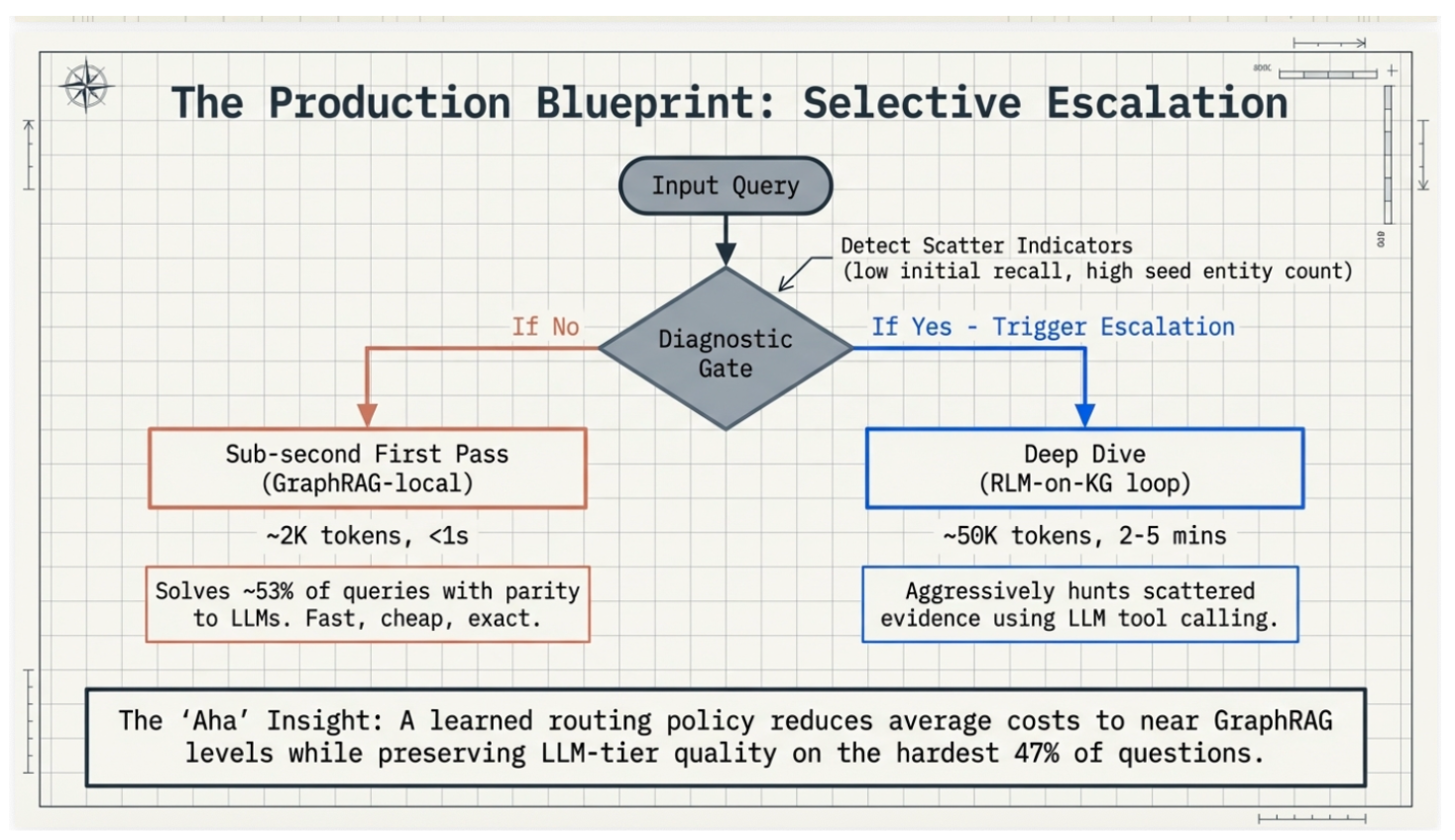
You don’t need to choose between “cheap” and “smart.” In a production environment, we use Selective Escalation:
- Step 1: Run a sub-second “First Pass” using GraphRAG-local. This solves about 53% of queries perfectly.
- Step 2: Use a “Diagnostic Gate” to look for “Scatter Indicators” (like a high number of entities mentioned in the query).
- Step 3: Trigger the expensive, high-powered Deep Dive only for the hardest 47% of questions.
6. The “Hidden” Benefit: KG Diagnostics
Beyond answering questions, these AI navigators act as a high-intensity stress test for your data. By watching where an AI navigator “stalls” or “trips,” we can diagnose the health of your Knowledge Graph:
- Coverage Gaps: If the AI falls back to general search, you’re missing specific entities or aliases.
- Connectivity Failures: If the AI gets stuck a few “hops” in, your data neighborhoods are too isolated.
- Provenance Errors: If the AI pulls the wrong info, your “links” are low-precision.
This makes RLM-on-KG not just a search tool, but an automated “clean-up crew” for enterprise data.
This blogpost is based on the research paper: “RLM-on-KG: Heuristics First, LLMs When Needed” by Andrea Volpini and Elie Raad.