The Reasoning Web
The Reasoning Web is coming. Learn how context graphs power agentic AI, as the web shifts from search engines to reasoning engines, with interoperable, actionable, machine-readable context.

How the web evolves from pages to memory, and from search to action
In 2025 as I was preparing for the G50 Summit, it became obvious that the web was no longer just a place where information is published and retrieved. The web has become a substrate where AI systems build context, connect facts, and increasingly take actions. In this shift, we are moving from search engines that retrieve documents to reasoning engines that assemble context, evaluate evidence, and execute workflows.
I call it the Reasoning Web: an ecosystem where content is still essential, but where value compounds around interoperable memory, structured meaning, and callable interfaces that let agents move from “find” to “decide” to “do”.
This blog post is both a personal recap of what we built at WordLift in 2025 and a positioning statement for what comes next: a standards-led, dereferenceable, multi-layered knowledge infrastructure that serves humans and machines at once.
2025, from “knowledge graph + SEO” to a memory layer for the agentic web
In 2025 we switched the narrative around our product, from scaling structured data and automating SEO, to building an interoperable dereferenceable memory layer for an agentic web. That shift came from a simple observation.
AI systems do not just need “more content”. They need dense, reliable context that can be referenced, recomposed, verified, and reused across tasks. Text alone struggles with that. Graphs are designed for it.
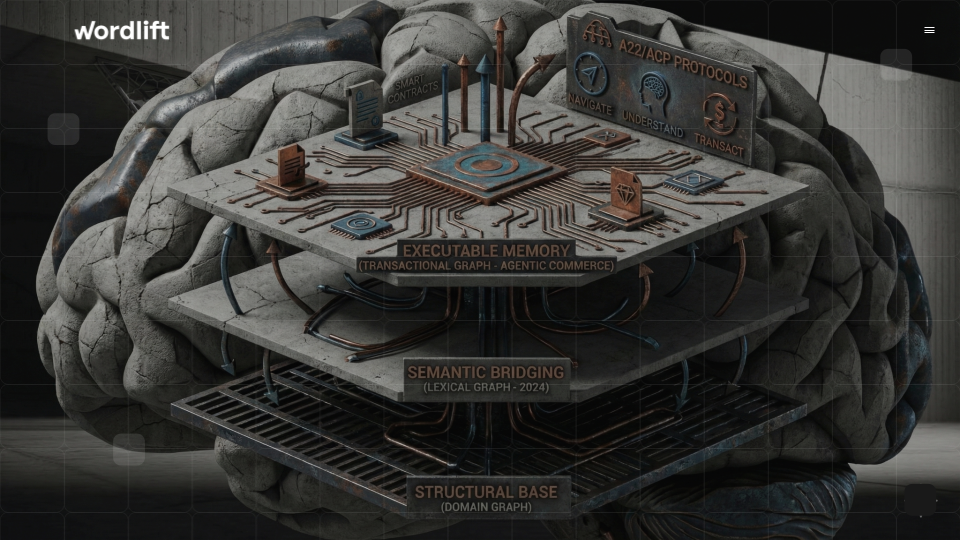
What changed in 2025 is that “the graph” stopped being a single object in our narrative. It became a multi-layer system:
- Domain graph: entities and relations, stable identifiers, dereferenceability, interoperability
- Lexical layer: embeddings and language signals attached to entity attributes, programmable and governance-friendly
- Transactional layer: agent-ready actions grounded in ACP/AP2-style patterns, where products and services become callable. This is the core idea of the Reasoning Web: a web of memory plus interfaces, not just a web of documents.
Why “Reasoning Web” Now
For twenty years, search dominated information access. The operating model was: publish pages, get crawled, rank, earn clicks.
That model is being rewritten. Agents are becoming the interface. In practice this means:
- Queries get decomposed into sub-questions
- Multiple sources get combined
- Outputs become personalized, structured, and increasingly executable
- Trust and provenance become part of the product, not an afterthought
This shift is not coming out of nowhere. The intellectual lineage of the Reasoning Web is in the original Semantic Web framing. In 2001, the Semantic Web anticipated agents negotiating meaning through shared vocabularies: “The Semantic Web is more flexible. The consumer and producer agents can reach a shared understanding by exchanging ontologies… Agents can even ‘bootstrap’ new reasoning capabilities when they discover new ontologies” Berners-Lee, Hendler, and Lassila also noted that agents can “bootstrap” new reasoning capabilities as they discover new ontologies, which is basically the early blueprint for an agent ecosystem that learns new skills by adopting new schemas and contracts.
The Reasoning Web is the Semantic Web’s trajectory, upgraded with new primitives: embeddings as a controllable lexical layer, standard tool interfaces that make knowledge operational, and transactional protocols that turn entities into safe, callable actions.
What’s new in 2025 is that the prerequisites are finally landing at scale: smaller models that can follow and refine reasoning traces, standardized tool interfaces, and enterprise demand for machine-readable, actionable context. This enables an explicit form of ontology-led reinforcement learning, that we tested with SEOcrate and we’re further refining now by shaping reward from constraint satisfaction (logical consistency, type correctness, policy compliance), evidence coverage (supporting subgraphs for claims), and action validity (callability and post-condition checks). This direction aligns with recent work showing that structured graphs can provide intermediate supervision that improves knowledge comprehension and reasoning faithfulness. For example, Knowledge Graph-Driven Supervised Fine-Tuning (KG-SFT) proposes augmenting standard Q&A supervision with graph-derived explanations, generated by extracting and using reasoning subgraphs that make the latent correlations and logic underlying an answer explicit.
The three-layer graph: memory, meaning, and action
In 2025, I learned that the most useful way to explain our infrastructure is not “we have a graph”. It is “we have a context graph” and this context graph is made of layers.
Layer 1: Domain graph (canonical meaning)
This is where the world is modeled as entities and relations with stable identifiers. The non-negotiables here are:
- Interoperability: built on shared vocabularies and contracts (Schema.org, GS1 Digital Link, and domain semantics)
- Dereferenceability: identifiers that resolve to machine-consumable representations, not just internal database keys
- Governance: explicit ownership, update rules, and change tracking
Layer 2: Lexical layer (language and similarity, under control)
This is where we attach language signals to the domain graph in a disciplined way:
- Embeddings linked to specific attributes, not free-floating vectors
- Programmable retrieval behaviors (what fields matter, what is boosted, what is filtered, is it a single or multiple chunks)
- A path to personalization and re-ranking without corrupting the canonical model
Layer 3: Transactional layer (callable entities)
This is where the Reasoning Web becomes a system of action. A product or service is no longer just a description. It becomes an interface with constraints, policies, and functions: availability checks, price retrieval, booking, purchasing, returns, support. We are seeing the market converge on standardizing this layer. At WordLift, we will focus on mapping Agentic Commerce Protocol (ACP) and Agentic Payment Protocol (AP2) to make entities actionable, measurable, and safe to call, not only easy to read.
What this means for your team?
If you are building for the next web, here is where you should start:
- Make identifiers real: stable, dereferenceable entity IDs
- Model meaning explicitly: entities, relations, constraints, and provenance
- Attach language carefully: embeddings tied to governed attributes
- Expose interfaces: APIs and tools that agents can call safely
- Adopt standards: Schema.org, GS1 Digital Link, and emerging agent protocols where relevant
- Instrument workflows: time-to-publish, update latency, consistency, conversion impact
- Continuously audit: machine-readability is not a one-time project
Conclusion: the web that thinks through your data
The Reasoning Web is the next practical step in how digital systems work:
- from documents to memory
- from retrieval to reasoning
- from content to workflows
- from description to action
My 2025 was about capability: evolving WordLift into agent-ready infrastructure through layered graphs, shared standards, and governed action surfaces.
In 2026, the goal is to establish WordLift as a system of record for context. We are building the enduring layer: a context graph that preserves the reasoning lineage of web workflows, from publishing to discovery to transactions. When context is captured as structured decision traces, the Reasoning Web is no longer a concept. It is the natural upgrade to how the web stores meaning and executes action.