When we think of bots, we either think of Star-Wars-like robots or humanoid androids communicating with us.
What are chatbots? Chatbots are computer programs built to communicate with humans using natural language. Usually, they handle customer service tasks, such as answering questions and booking appointments.
The primary purpose of chatbot systems is to retrieve valuable and relevant information from one or multiple knowledge bases by using natural language understanding (NLU) and semantic web technologies.
The problem
The web is packed with the most disparate information; it’s often hard for humans to classify and judge the quality of a source at first sight, so, in order to save time, which is our most valuable asset, we turn to machines to do the searching for us.
Technically speaking
Many chatbot systems are designed to require a lot of training data, which is unavailable and expensive to create. Recently, with the growth development of linked data, increasing progress on chatbots has been seen in research and industry. However, they face many challenges, including user query understanding, intent classification, multilingual aspect, multiple knowledge bases, and analytical queries interpretation.
Knowledge graphs are becoming more and more a standard technology for Companies, people, and publishers. A Knowledge-Graph-based bot is scalable, flexible, and dynamic.
Why Knowledge Graphs
A Knowledge Graph is a structure that portrays information as relationships and concepts connected to each other. Google was the first to mention Knowledge Graphs and the technology behind them back in 2012. You can find out more about why you need a Knowledge Graph, read our blog post.
Back to us now!
So we know that a chatbot needs a domain model in order to understand and answer user questions. In machine learning, we would generate a huge knowledge base of sentences and use cases, wasting time and resulting in a static chatbot, which the web is full of already.
Since a domain model collects information about a particular topic or subject, we can use a Knowledge Graph to store and retrieve information easily.
In this way, our chatbot would be dynamic and always up to date without manually adding and editing the knowledge base.
Advantages of Knowledge Graph-Based Chatbots
A chatbot based on a Knowledge Graph knows how to interpret requests from the users delivering meaningful answers straight away. Moreover, there won’t be a need for lengthy training.
Knowledge Graphs can be updated more efficiently simply by adding data and relationships to other entities.
How To Develop A Knowledge-Based Chatbot
First of all, there is the preparatory work for the Knowledge Graph, in which there should be a clear structure of concepts, entities, and relationships between them.
Then, the chatbot needs to “study” those rules, entities, and relations to answer questions.
These are three main flows that describe how to develop a conversational interface based on a Knowledge Graph:
Pushing contents from the Knowledge Graph (KG) to the website/backend (via GraphQL interface) – the data present in the KG are made available through targeted queries.
Semantic content search on questions-answers (via search API) – the FAQ content is made available through targeted queries that can be consulted performing semantic search, which allows you to manage, if present, the intent associated with specific questions.
Natural language understanding and dialogue management (via NLU for intent management) – the KG data and the semantic search functions are operated by an external dialogue manager application that intercepts the user’s intent and retrieves the answers (accessing content either in the KG or from semantic search).
Knowledge Graph and GraphQL
The Knowledge Graph is fed with content flows from the CMS and through the NLP end-point, which analyzes the unstructured contents and organizes them semantically using the Company’s vocabulary containing the key concepts (entities).
The graph may contain different content types: FAQpages, NewsArticles, Articles, Offers… all useful to sustain a conversation flow that includes different nuances on the same topic, as a user might want to know a definition of a term or articles related to this term.
GraphQL is a query language and execution engine designed to implement API-based solutions that access information in the Knowledge Graph.
We use GraphQL as a query service, and its functions are available for data consultation only. Reading takes place through a different end-point.
GraphQL is used when users want to see all articles related to a topic.
Requests towards GraphQL are executed in the Knowledge Graph via authentication.
Semantic Search
This module integrates the API for semantic search to the knowledge base. A first usage scenario is based on the FAQ content present on the site today.
Later, it will be possible to extend the scope of use of this feature to all web content in the KG through the use of models for open-domain question answering (ODQA).
The search for answers (/ ask)
The answers to user questions are extracted through a semantic content search system.
This way, we can enable a classification algorithm that uses a transformer-based neural network to classify questions based on how “significant” they are in relation to the user’s query.
The use case is based on the following application flow:
The dialogue manager (NLU) identifies an intent that can be satisfied by FAQ content
The user’s question is delivered to the Search API
The Search API identifies the closest question-answer
The result is sent to the dialogue manager (NLU)
The dialogue manager via ECSS sends the response to the end-user
Understanding of natural language and dialogue management
We use a scalable architecture: the two main components are natural language understanding (NLU – Natural Language Understanding) and a dialogue management platform.
NLU deals with managing the classification of intentions, the extraction of entities, and the recovery of responses. In the diagram, it is represented as an NLU pipeline because it processes user expressions using an NLU model generated by the trained pipeline.
The dialogue management component determines the following action in a conversation based on context (the Dialogue Policies indicated in the diagram).
Conclusions
Knowledge Graphs are very powerful databases to develop a conversational marketing strategy, and when it comes to building a conversational interface, they stand out from other technologies in terms of:
Speed
Powerful interrelationships between concepts
Flexibility
Possibility to easily update the graph
Embed potentially unlimited knowledge
The goal of any bot is to provide valuable and relevant information to users, adapting to each context and request. And that’s what Knowledge Graphs do: they move and adjust.
In a world of infinite information, be the KG-powered bot!
On-site search is the functionality by which a user can search for a piece of content or product directly on your website by entering a query in the search bar.
This functionality, also known as internal search, can significantly impact your website: it allows users to find what they are looking for and discover new content or products they are interested in but didn’t know about. It also gives you valuable data and insight into what content or products your audience likes and is most interested in, allowing you to tailor the website to the visitor’s specific needs.
Building an optimized on-site search can get you more conversions and foster brand loyalty. If the user doesn’t have a relevant search experience, they may choose to go to your competitors, risking losing customers.
On-site search is critical, not only if you have an e-commerce store. Any website with a collection of content can reap the benefits of relevant, fast, and easy-to-use site search: better click-through rates, more user engagement, and a better understanding of customer needs.
Why Is On-Site Search Important In SEO?
There is a relevant connection between SEO and on-site search. SEO allows you to increase organic traffic to your website. On-site search makes sure that visitors to your website find what they are looking for quickly and easily. SEO focuses on creating quality content that is relevant to your audience. But the more content you have on your site, the harder it is to get it found. That’s why there’s an internal search. It makes it easy for users to find your content, whether they’re looking for information or products, or services.
In addition, analyzing data on searches made by visitors to your site helps you understand which content or products are most popular and if there are any gaps in your content marketing, sales, or product development strategies. Knowing this data allows you to define more effective strategies and actions to optimize your website for both content and user experience.
How Can You Optimize On-Site Search with AI?
The Knowledge Graph is the key to your on-site search optimization. And below I will show you why.
The Knowledge Graph is the dynamic infrastructure behind your content. It allows your website to speak the native language of search engines, allowing Google and others to understand what you do and what you’re talking about. In this way, you build well-contextualized, related content that contains consistent information and addresses the needs of your audience. By providing users with a relevant experience, you get higher rankings on Google and more organic traffic to your website.
Not only that. We’ve seen that Google search is changing, moving from information retrieval to content recommendation, from query to dialogue. So the search engine is not only answering the user’s questions, but it’s also capable of discovering new content related to the user’s interests. Training the Knowledge Graph allows us to go in this direction, showing the user new content related to his search.
If Knowledge Graph makes Google search smart, it can make your on-site search smarter.
Creating a custom Knowledge Graph and then adding structured data allows your website to better communicate with Google and other search engines, making your content understandable to them. The same will happen for your website’s internal search engine. So, when a user enters a query, the results will be more consistent and respond to the user’s search needs. Also, through Knowledge Graph, you will be able to build landing page-like results pages that include FAQs and related content. In this way, the user will have relevant content, and their search experience will be more satisfying.
By answering users’ top search queries and including information relevant to your audience, these pages can be indexed on Google, also increasing organic traffic to your website.
For example, this is the result for the query vakantieparken met subtropisch zwembad (trad. “vacation parks with subtropical swimming pool”). As you see, we have a page with all the solutions offered by the brand and a FAQ block that will help give the user additional answers for what he is looking for.
If we search the same query on Google we will have the same page as a first result in the SERP.
Search engines use entities and their relationships to understand human language. A generic occurrence of the term ‘delivery’ on the website of a logistic company might indicate the more specific concept of ‘last mile delivery’- using structured data the term is lifted as it gets uniquely identified by a Machine-Readable Entity ID that references a similar concept in public graphs like Wikidata or DBpedia (ie last mile in this example). When a term is semantically enriched (or lifted in our jargon) a search engine is also able to leverage its synonyms and neighboring terms. A user making a search for ‘last mile delivery’ or even ‘last mile’ on that website will be able to find that page.
With WordLift, you can build your Knowledge Graph and add structured data to your website content. Together, we can optimize your site search if you already have it or make it in a way that your customers will love.
On-Site Search Best Practices
To have on-site search optimization, you can follow some best practices.
Make the search box user-friendly
Make sure the search bar is visible from any device and long enough to contain the user’s query. Usually, it will be at least 27 characters long. Remember to place search bars on your site’s primary pages, but not on all of them. Putting it on the checkout page or landing pages may be inappropriate and distract the user from other required actions, such as purchasing a product. Insert a clear call-to-action in the search bar and encourage research with phrases like “insert product, code or brand” or “what are you looking for?”, etc.
Analyze your search data
Analyzing data on internal searches on your website allows you to understand what users are interested in, what they’re looking for, and what content, products, or services are most popular. Also, you can see there may be search intents that aren’t covered with existing content, so work needs to be done to create it. (For example, if a user searches for “how to add FAQ markup” on wordlift.io, we know we are missing that content, and it needs to be created).
Improve imperfect inputs
Facilitates on-site search by improving imperfect inputs and making them predictive. Use autocomplete, autocorrect, filters, and facets to assist the search. Users will appreciate it.
Make the results page intuitive, helpful, and inspiring
Semantic search analyzes the context and searches intent behind the query to deliver relevant results to the user. Also, take advantage of “No Results Pages” to make suggestions to the user about other similar content or in line with their search, so they don’t miss out.
Always redirect the user to the right page (when you have already one)
Bypassing the search result page will make the customer journey smoother. If you have a laser target page on “outdoor speakers” and the user is searching for that, make sure to redirect him/her directly there without passing by the results page.
Not all result pages need to be the same, you can curate some of these pages to cover long-tail intents that really matter. You can do this by adding intro text and FAQ content on these pages. Now, these “enriched” result pages will also work well in search (provided that you add them to the sitemap).
A good-looking search box doesn’t mean anything if the results aren’t helpful to the searcher. And that’s where structured data and the Knowledge Graph come in, as we showed you above.
Knowledge validation is an important task in the curation of knowledge graphs. Validation (also known as fact-checking) aims to evaluate whether a statement in a knowledge graph (KG) is semantically correct and corresponds to the so-called “real” world.
In this article, we describe our proposed approach for validating knowledge graphs (KGs).
Knowledge Graphs
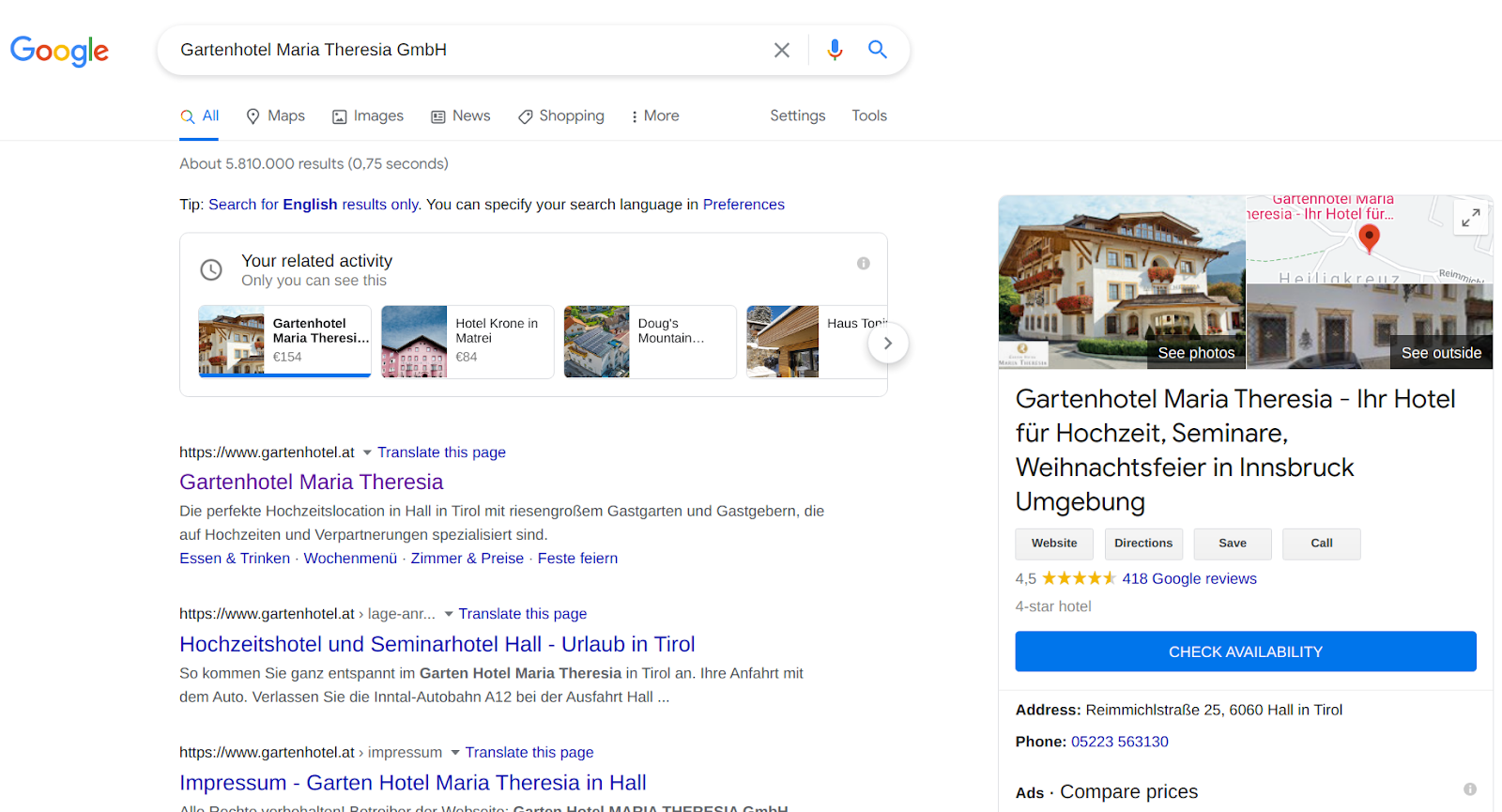
Nowadays, various KGs have been created. For instance, DBpedia and Wikidata KGs have been created semi-automatically and through crowdsourcing respectively. However, those KGs might have errors, duplicates, or missing values. Moreover, KGs are used in search engines and personal assistants applications. For example, Google shows the fact “Gartenhotel Maria Theresxia GmbH’s phone is 05223563130” that might be wrong to advertise because the main switchboard of the hotel can be reached under “0522356313”. See Fig. 1.
Fig. 1: Knowledge Panel of Garten hotel.
Knowledge Sources
Apart from KGs mentioned above, there are various knowledge sources that collect and store content and data of the Web. For instance, Google places is a service offered by Google and it provides data about more than 200 million businesses, places, points of interest, and more. Furthermore, there are other knowledge sources, such as Yandex Places or Open Street Maps (OSM) that provide data about places, restaurants, point of interests, and much more. Those knowledge sources can be used to validate statements of KGs.
Knowledge Validation
To ensure that a KG is of a high quality, one important task is knowledge validation: it measures the degree to which statements are correct. For instance, knowledge validation measures to which degree information about a hotel (e.g. Hotel Alpenhof’s phone number is+4352878550) is correct based on comparing information of the same hotel in a set of knowledge sources. See Fig. 2.
Fig. 2: Validating information about the Hotel Alpenhof.
KG validation carried out by human experts is a time-intensive and non-scaleable task. Therefore, an approach to validate data semi-automatically is needed. There are some approaches that can help with this process, see Fig. 3.
Fig. 3: Overview of validation approaches [Huaman et al., 2020]
Further, we present our approach to validate KGs based on weighted sources.
Approach
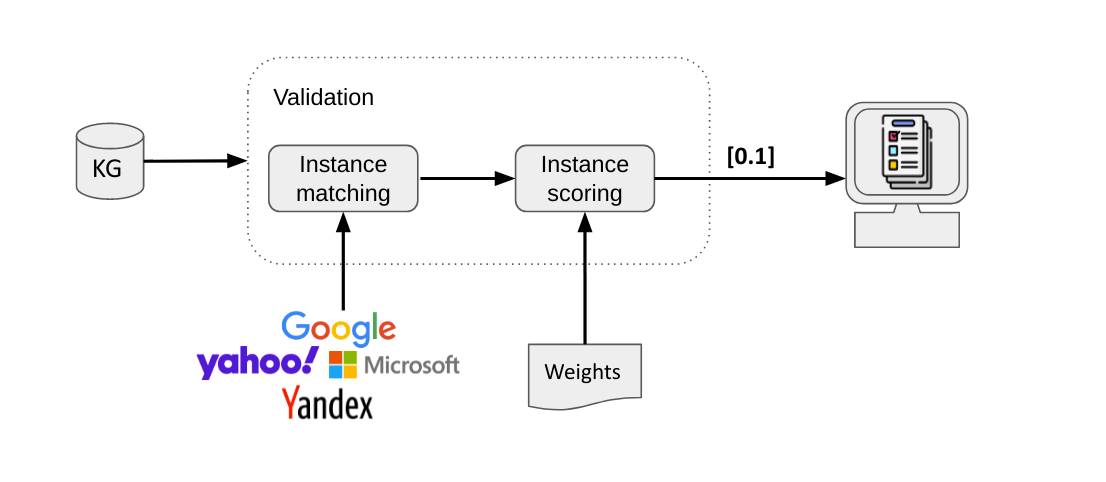
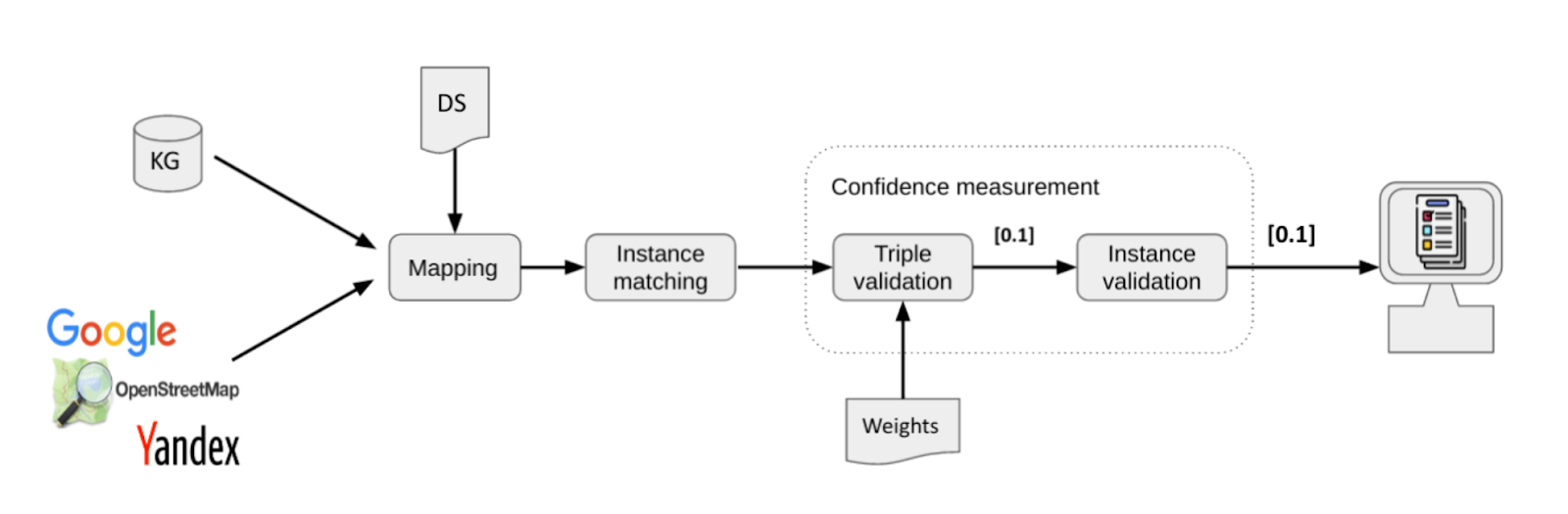
The process overview of the Validator is shown in Fig. 4. At first, users have to set their KG as input to the Validator. Internally, the Validator retrieves data from external knowledge sources (e.g., Google Places, Yandex Places), the Validator performs instance matching to identify which instances (e.g., hotels) refer to the same “real-world” entity, for example, it retrieves Alpenhof hotel from external sources.
Fig. 4: KG Validation process overview.
Later on, the instance scoring process is triggered and the properties (e.g., name, phone number, address) of the same instances are compared with each other. For example, the address of Alpenhof Hotel from the user’s KG is compared with the address value of the Alpenhof Hotel from Google Places, Yandex Places, and so on. Note that each external source is weighted according to its importance: a user can set the weight of (his or her personal) importance for Google Places, Yandex Places, and so on. 0 is the minimum degree of importance and a value of 1 is the maximum degree.
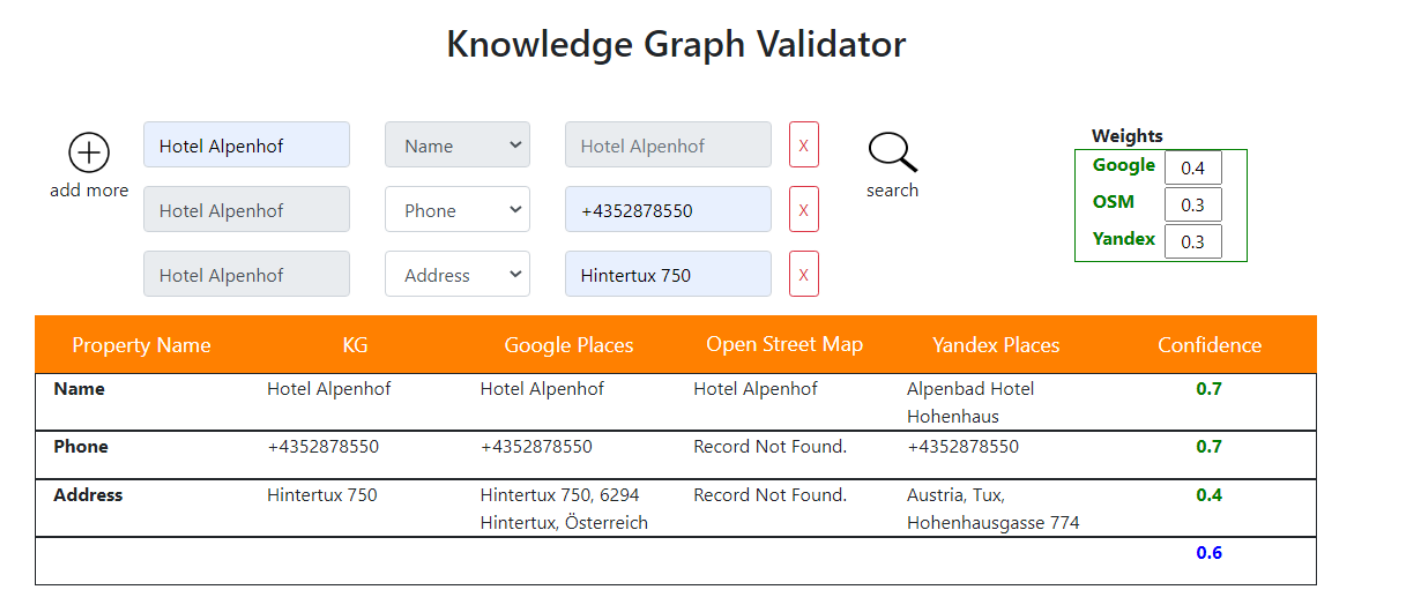
Fig. 5: Screenshot of the Validator [Huaman et al., 2021].
Finally, the computed scores are shown via a graphical user interface (see Fig. 5). It allows users to select multiple properties (e.g. address, name, and/or phone number) to be validated, users can assign/change weights to external sources.
Full details about the approach, implementation, and evaluation are provided at [Huaman et al., 2021].
Where can you use it?
A user can check whether the information for his or her hotel or other business provided by Google Places, Yandex Places, and other sources are correct and up-to-date.
A user could want to validate if the provided information is correct based on different knowledge sources.
The approach might be used to link user’s KG with Google Places, Yandex Places, and so on.
Tools and Technology
The Validator was developed by three students from the University of Innsbruck, in the context of the Eurostars co-funded project WordLift Next Generation.
Summary
Conceptualization of a new KG Validation approach and a first prototypical implementation thereof.
Showcasing use cases where it can be used.
Validating KGs ensures that major search engines show the correct information about your business.
References
[Huaman et al., 2021] Huaman E., Tauqeer A., Fensel A. (2021) Towards Knowledge Graphs Validation Through Weighted Knowledge Sources. In: Villazón-Terrazas B., Ortiz-Rodríguez F., Tiwari S., Goyal A., Jabbar M. (eds) Knowledge Graphs and Semantic Web. KGSWC 2021. Communications in Computer and Information Science, vol 1459. Springer, Cham. https://doi.org/10.1007/978-3-030-91305-2_4
[Huaman et al., 2020] Huaman E., Kärle E, and Fensel D. (2020) Knowledge Graph Validation https://arxiv.org/abs/2005.01389
Deep neural networks are powerful tools with many possible applications at the intersection of the vision-language domain. One of the key challenges facing many applications in computer vision and natural language processing is building systems that go beyond a single language and that can handle more than one modality at a time.
These systems, capable of incorporating information from more than one source and across more than one language, are called multimodal multilingual systems. In this work, we provide a review of the capabilities of various artificial intelligence approaches for building a versatile search system. We also present the results of our multimodal multilingual demo search system.
What is a multimodal system?
Multimodal systems jointly leverage the information present in multiple modalities such as textual and visual information. These systems, aka cross-modal systems, learn to associate multimodal features within the scope of a defined task.
More specifically, a multimodal search engine allows the retrieval of relevant documents from a database according to their similarity to a query in more than one feature space. These feature spaces can take various forms such as text, image, audio, or video.
“A search engine is a multimodal system if its underlying mechanisms are able to handle different input modals at the same time.”
Why are multimodal systems important?
The explosive growth in the amount of a wide variety of data makes it possible, and necessary, to design effective cross-modal search engines to radically improve the search experience in the scope of a retrieval system.
One interesting multimodal system is building a search engine that enables users to express their input queries through a multimodal search interface. As the goal is to retrieve images relevant to the multimodal input query, the search engine’s user interface and the system under the hood should be able to handle the textual and the visual modalities in conjunction.
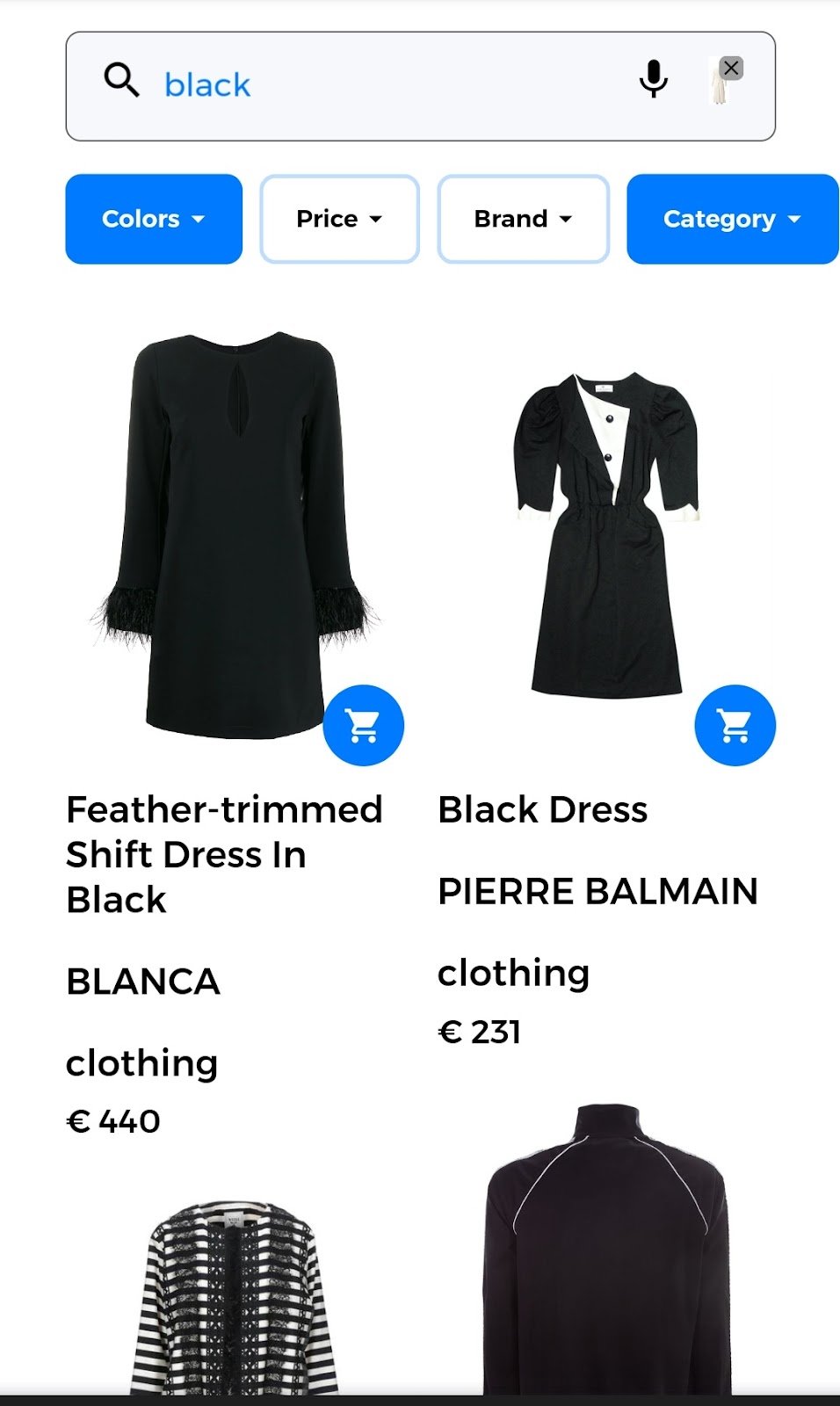
For instance, a search query could take the form of “give me something like this image but I want it to be black”. As shown in the image below, the user provides to the search engine 1) an image of the dress that she’s looking for and 2) a text, or another input form, to indicate the desired color. This way of expression, comparable to how humans communicate, would promote a much better search experience.
When running this search, the input image is a white dress that is shown in the image below. This is the first part of the query which corresponds to the visual part of the multimodal query.
The second part of this query consists of the desired color which is the textual input. In this case, the user is looking for dresses that are “black”. The returned results are images of the dresses that are available at the e-commerce store. The result of the multimodal query is shown in the image below.
Given the richness and diversity within each modality, designing a multimodal system requires efforts to bridge the gap between the various modality, including image, text, video, and audio data. Encoding the textual and the visual modalities into a joint embedding space is one way for bridging the worlds of varying modalities.
While the image is language agnostic, the search terms are language-specific. Monolingual vision-language systems limit the usefulness of these systems in international applications. In general, these monolingual systems are English-only. Let’s now examine cross-lingual approaches in the context of textual and visual retrieval systems.
What is a multilingual system?
Let’s examine one of many key challenges at the intersection of computer vision and natural language processing. We quickly observe the limitation of the current systems to expand beyond a single language.
“A search system is multilingual if the system is able to retrieve relevant documents from the database by matching the document’s captions written in one language with the input text query in another language. Matching techniques range from syntaxical mechanisms to semantic search approaches.”
The task of designing a multilingual system boils down to building language models that support the addition of new languages. Consequently, a large number of additional parameters is required each time a new language is added. In reality, these parameters support the word embeddings that represent the newly added language’s vocabulary.
The primary use case of our multimodal multilingual system is an image-sentence retrieval task where the goal is to return relevant images from the database given a query image and a sentence at the same time. In this vein, we’ll explore the multimodal path and address the challenge of supporting multiple languages.
Towards multimodal and multilingual systems
Learning a good language representation is a fundamental component of addressing a vision-language task. The good news is that visual concepts are interpreted almost in the same way by all humans. One way is to align textual representations to images. Pairing sentences in different languages with visual concepts is a first step to promote the use of cross-lingual vision-language models while improving them.
It has been demonstrated that such approaches can accomplish better performance compared to traditional ones, i.e. text-only trained representations, across many vision-language tasks like visual question answering or image-sentence retrieval. However, many of these promising methods only support a single language which is, in most cases, the English language.
“A multimodal multilingual system is a combination of each of the multimodal and multilingual systems that are described in the previous sections.”
A large number of cross-modal approaches require much effort to pre-train and fine-tune multiple pairs of languages. Many of them have hand-crafted architectures that are dedicated, or at least, perform best at a specific vision-language task. In addition, many of these existing systems are able to handle one modality at a time. For instance, retrieve a relevant sentence from a corpus given an image or retrieve a relevant image from the database given a sentence.
BERT has paved the way for the large adoption of representation learning models based on transformers. BERT follows a two-fold training scheme. The first consists of pre-training a universal backbone to obtain generalizable representations from a large corpus using self-supervised learning. The second one is a fine-tuning task for specific tasks via supervised learning.
Recent efforts, such as MPNet build upon the advantages of BERT by adopting the use of masked language modeling (MLM). In addition, MPNet novel pretraining takes into consideration the dependency among the predicted tokens through permuted language modeling (PLM) – a pre-training method introduced by XLNet.
While these approaches are capable of transferring across different languages beyond English, the transfer quality is language-dependent. To address this computational roadblock, some approaches tried to limit the language-specific features for just a few by using masked cross-language modeling approaches.
Cross-modal masked language modeling (MLM) approaches consist of randomly masking words and then predicting them based on the context. On the one hand, cross-language embeddings can then be used to learn to relate embeddings to images. On the other hand, these approaches are able to align the embeddings of semantically similar words nearby, including words that come from different languages. As a result, this is a big step towards the longstanding objective of a multilingual multimodal system.
Training and fine-tuning a multilingual model is beyond the scope of this work. As BERT and MPNet have inspired de-facto multilingual models, mBERT, and mMPNet, we’re using such available multilingual pre-trained word embeddings to build the flow of a multilingual multimodal demo app.
Demo app: multilingual and multimodal search
The end goal of the search engine is to return documents that satisfy the input query. Traditional information retrieval (IR) approaches are focused on content retrieval which is the most fundamental IR task. This task consists of returning a list of ranked documents as a response to a query. Neural search, powered by deep neural network information retrieval (or neural IR), is an attractive solution for building a multimodal system.
The backbone of this demo app is powered by Jina AI, an open-source neural search ecosystem. To learn more about this neural search solution you get started here. Furthermore, don’t miss checking this first prototype that shows how Jina AI enables semantic search.
To build this search demo, we modeled textual representations using the Transformer architecture from MPNet available fromHugging Face (multilingual-mpnet-base-v2 to be specific). We processed image captions and the textual query input using this encoder. As for the visual part, we used another model made available and called MobileNetV2.
The context
In what follows, we present a series of experiments to validate the results of the multilingual and multimodal demo search engine. Here are the two sets of experiments:
The first set of tests aims to validate that the search engine is multimodal. In other words, the search engine should be able to handle textual and images features simultaneously.
The second set of tests aims to validate that the search engine is multilingual and able to understand textual inputs in multiple languages.
Before detailing these tests, there are a few notes to consider:
The database consists of 540 images related to Austria.
Every image has a caption that is written in English.
Each modality can be assigned a weight that defines the importance of each modality. A user can assign a higher weight to either the textual or the visual query input (the sum of the weights should always be 1). By default, both modalities have an equal weight.
The following table summarizes these experiments.
Test
Setting
Test 1A
Multimodal inputs with equal weights
Test 1B
Multimodal inputs with a higher weight for the image
Test 1C
Multimodal inputs with a higher weight for the text
Test 2A
Multimodal inputs with a textual query in English
Test 2B
Multimodal inputs with a textual query in French
Test 2C
Multimodal inputs with a textual query in German
Test 2D
Multimodal inputs with a textual query in Italian
The results
For the first set of tests (Test 1A, 1B, and 1C), we use the same multimodal query made of an image and a text as shown below. This input query consists of:
An image: a church in Vienna and
The textual input: Monument in Vienna
Test 1A – Multimodal inputs with equal weights
In Test 1A, the weight of the image and the textual input are equal. The returned results show various monuments in Vienna like statues, churches, and museums.
Test 1B – Focus on the image input
Test 1B gives more weight to the image and completely ignores the textual inputs. The intention is to test the impact of the input image without the text. In practice, the search result is composed of various monuments that, most of them, contain buildings (no more statues). For instance, we can see many churches, the auditorium, city views, and houses.
Test 1C – Focus on the textual input
Test 1C is the opposite of Test 1B. All the weight is given to the textual input (the image is blank, it is ignored). The results are aligned with input sentence monuments in Vienna. As shown in the image below, various types of monuments are returned. The results are no longer limited to buildings. We can see statues, museums, and markets in Vienna.
Test 2A – Multilingual queries
As mentioned earlier, the captions associated with the images are all in English. For the sake of this test, we chose the following 4 languages to conduct the multilingual experiments:
English (baseline)
French
German
Italian
We translated the following query to each of these four languages: grapes vineyards. As for the weight, the textual input has a slightly higher weight (0.6) in order to eliminate potential minor noise signals.
For each of the 4 languages, we run a test using the English version of the MPNet transformer (sentence-transformers/paraphrase-mpnet-base-v2) and then its multilingual version (multilingual mpnet). The goal is to validate that a multilingual transformer is able to grasp the meaning of the textual query in different languages.
Test 2A – English + monolingual textual encoding
The query is in English: grapes vineyards and the encoder is monolingual.
Test 2B – English + multilingual textual encoding
The query is in English: grapes vineyards and the encoder is multilingual.
Test 2B – French + monolingual textual encoding
The query is in French: raisins vignobles and the encoder is monolingual.
Test 2B – French + multilingual textual encoding
The query is in French: raisins vignobles and the encoder is multilingual.
Test 2C – German + monolingual textual encoding
The query is in German: Trauben Weinberge and the encoder is monolingual.
Test 2C – German + multilingual textual encoding
The query is in German: Trauben Weinberge and the encoder is multilingual.
Test 2D – Italian + monolingual textual encoding
The query is in Italian: uva vigneti and the encoder is monolingual.
Test 2D – Italian + mono lingual textual encoding
The query is in Italian: uva vigneti and the encoder is multilingual.
Insights and discussions
Comparing the edges cases (Test 1B and Test 1C) with the test where the two modalities have the same weight (Test 1A) show that:
The results of Test 1A take into consideration both the image and the text. The first two images refer to churches and at the same time the result set contains other types of monuments in Vienna.
Test B that focuses on the image returns only images in the category of buildings, ignoring every other type of monument in Vienna.
Test C that focuses on the text returns various types of monuments in Vienna.
As for testing the multilingual capabilities across four languages. We can clearly see that for the English language, the mono and multilingual performance are good and are almost similar. This is expected as both encoders are trained on a corpus language. A small note regarding the monolingual encoder for the French language, the first three results are surprisingly good for this specific query.
As for the three remaining languages, the multilingual encoder returns much more relevant results than the monolingual encoder. This shows that this multimodal multilingual search demo is able to understand queries written in one language and return relevant images with captions written in English.
The future of neural search
Neural search is attracting widespread attention as a way to build multimodal search engines. Deep learning-centric neural search engines have demonstrated multiple advantages as reported in this study. However, the journey of building scalable and cross-domain neural search engines has just begun.
On July 5th and 6th the team at WordLift reached Salzburg to meet the Consortium partners for the WordLift Next Generation project. As you may know, WordLift received a grant from the EU to bring its tools to any website and to perfect anyone’s semantic SEO strategy [link].
WordLift Next Generation is made up of WordLift, Redlink GmbH, SalzburgerLand Tourismus GmbH and the Department of Computer Science of the University of Innsbruck.The aim is to develop a new platform to deliver Agentive SEO technology to any website, despite its CMS, and to concretely extend the possibilities of semantic SEO in a digital strategy. The work started in January 2019 and is being developed in a 3-year timeframe.
The project started with a clear definition of the roles and responsibilities of each partner in the scope to improve WordLift’s backend to enrich RDF/XML graphs with semantic similarity indices, full-text search and conversational UIs. The main goals for the project are: being able to add semantic search capabilities to WordLift, improved content recommendations on users’ websites and the integrations with personal digital assistants.
Here is an example of the initial testing done with Google’s team on a mini-app inside Google Search and the Google Assistant that we developed to experiment with conversational user interfaces.
Artificial Intelligence is leading big companies’ investments, and WordLift NG aims at bringing these technologies to small/mid sized business owners worldwide.
In order to accomplish these ambitions goals the consortium is working on various fronts:
Development of new functionalities and prototypes
Research activities
Community engagement
What is WordLift NG?
The study for the new platform for WordLift’s clients started with a whole new user journey, including an improved UX. New features, developed with content analysis, include automatic content detection, specific web page markup, and knowledge graph curation.
The main benefit of this development is to exploit long tail queries to be featured as speakable (voice) tagging for search helpers. The new backend lets users create dedicated landing pages and applications with direct queries in GraphQL.
The new platform also provides users with useful information about data shared in the Knowledge Graph, including traffic stats, Structured Data reports.
The development of NG involves features to bring WordLift’s technology to any CMS, the new on-boarding WebApp is part of that.
Envisioning a brand new customer journey, built to help publishers get their SEO done with a few easy steps, the new on-boarding web app guides the setup for users not running their websites on WordPress.
The workshop held various demos for applications developed by partners.
WordLift showcased a demo for semantic search, a custom search engine that uses deep learning models while providing relevant results when queried. With semantic search one can immediately understand the intent behind customers and provide significantly improved search results that can drive deeper customer engagement.
This feature would have a major impact on e-commerces.
WordLift applied semantic search to the tourism sector and to e-commerce.
The backend of the platform is being developed by RedLink, on state-of-the-art technologies.
The services are issued within a cloud microservice architecture which makes the platform scalable, and the data that today are published with WordLift is hosted on Microsoft Azure.
It will provide specific services and endpoints for the text analysis (Named Entity Recognition and Linking) data management (public and private knowledge graphs and schema, data publication), search (full text indexing) and conversation (natural language understanding, question answering, voice conversation) for its users.
GraphQL was selected to facilitate access to data in the Knowledge Graph by developers. Tools for interoperability between GraphQL and SPARQL were also tested and developed.
Data curation and Validation
An essential phase of the project is the collection of requirements and state of the art analysis in order to guarantee a perfectly functioning and functional product.
The requirements for WordLift NG were developed by SLT, the partner network and STI.
The results of the research activities are aimed at:
enhancement of content analysis – read more about this here
analysis of the methodologies for the identification of similar entities (in order to allow, on the basis of the analysis of the pages in the SERP, the creation or optimization of relevant content already present in the Knowledge Graph)
the algorithms for data enrichment in the Knowledge Graph and reconciliation with data from different sources
On this front, the Consortium is currently working on the definition for SD verification and validation of Schema markup.
This phase will ensure all statements are:
Semantically correct
Corresponding to real world entities (annotations must comply with content present and validated on the web)
and that annotations are compliant with given Schema definitions (correct usage of schema.org vocabulary).
Community Engagement
Part of the project is the beta testing and the presentation of the platform to WordLift’s existing customers.
We’d be thrilled to share our findings on structured data with the SEO community and very happy to support open sharing of the best practices also from Google and Bing (both seem to be willing to share in machine-readable format the guidelines for structured data markup).
WordLift is an official member of the DBPedia community and will actively contribute to DBpedia Global. Find out more.
If you’re willing to know more about it, and to be included in the testing of the new features contact us or subscribe to our newsletter!
With the rise of knowledge graphs (KGs), interlinking KGs has attracted a lot of attention. Finding similar entities among KGs plays an essential role in knowledge integration and KG connection. It can help end-users and search engines more effectively and easily access pertinent information across KGs.
In this blog post, we introduce a new research paper and the approach that we are experimenting with within the context of Long-tail SEO.
Long-tail SEO
One of the goals that we have for WordLift NG is to create the technology required for helping editors go after long-tail search intents. Long-tail queries are search terms that tend to have lower search volume and competition rate, as well as a higher conversion rate. Let me give you an example: “ski touring” is a query that we can intercept with a page like this one (or with a similar page). Our goal is twofold:
helping the team at SalzburgerLand Tourismus (the use-case partner of our project) expand on their existing positioning on Google by supporting them in finding long-tail queries;
helping them enrich their existing website with content that matches that long-tail query and that can rank on Google.
In order to facilitate the creation of new content we proceed as follows:
analyze the entities behind the top results that Google proposes (in a given country and language) for a given query.
find a match with similar entities on the local KG of the client.
To achieve the first objective WordLift has created an API (called long-tail) that will analyze the top results and extract a short summary as well as the main entities behind each of the first results.
Now given a query entity in one KG (let’s say DBpedia), we intend to propose an approach to find the most similar entity in another KG (the graph created by WordLift on the client’s website) as illustrated in Figure 1.
Figure 1. The interlinking problem over the knowledge graphs
The main idea is to leverage graph embedding, clustering, regression and sentence embedding as shown in Figure 2.
Figure 2. The proposed approach
In our proposed approach, RDF2Vec technique has been employed to generate vector representations of all entities of the second KG and then the vectors have been clustered based on cosine similarity using K medoids algorithm. Then, an artificial neural network with multilayer perceptron topology has been used as a regression model to predict the corresponding vector in the second knowledge graph for a given vector from the first knowledge graph. After determining the cluster of the predicated vector, the entities of the detected cluster are ranked through the sentence-BERT method and finally, the entity with the highest rank is chosen as the most similar one. If you are interested in our work, we strongly recommend you to read the published paper.
Conclusions and future work
To sum up, the proposed approach to find the most similar entity from a local KG with a given entity from another KG, includes four steps: graph embedding, clustering, regression and ranking. In order to evaluate the approach presented, the DBPedia and SalzburgerLand KGs have been used as the KGs and the available entity pairs which have the same relation, have been considered as training data to train the regression models. The absolute error (MAE), R squared (R2) and root mean square error (RMSE) have been applied to measure the performance of the regression model. In the next step, we will show how the proposed approach leads to enriching the SalzburgerLand website when it takes the main entities from the long-tail API and finds the most similar entities in the SalzburgerLand KG.
Reference to the paper with full details: Aghaei, S., Fensel, A. „Finding Similar Entities Across Knowledge Graphs“, in Proceedings of the 7th International Conference on Advances in Computer Science and Information Technology (ACSTY 2021), Volume Editors: David C. Wyld, Dhinaharan Nagamalai, March 20-21, 2021, Vienna, Austria.































Recent Comments