
Il brevetto di clustering delle entità è aggiornato
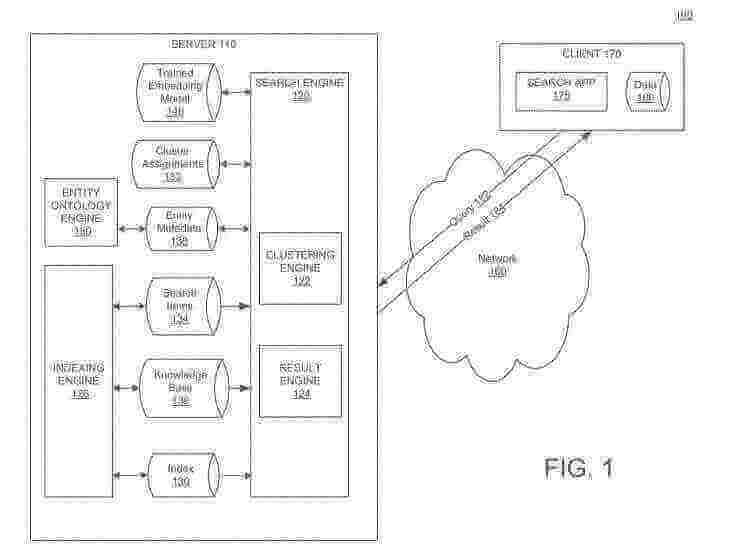
Uno dei miei ultimi post sul blog riguardava Google che raggruppava le notizie per argomento nei risultati di ricerca organici. Google ha raggruppato anche le informazioni sulle entità nei risultati di ricerca. Se ora cerchi persone che hanno recitato con Humprey Bogart in Casablanca, nei risultati puoi vedere anche altri attori di quel film. Puoi anche vedere le domande correlate che includono quegli attori e il film (e quell’ontologia sulle categorie associate al film). Questo nuovo post riguarda il clustering di entità e un cambiamento nel modo in cui Google sta fornendo risultati di ricerca relativi ai diversi cluster così ottenuti.
Ecco un esempio di risultati di ricerca che mostrano connessioni tra attori e il film Casablanca:
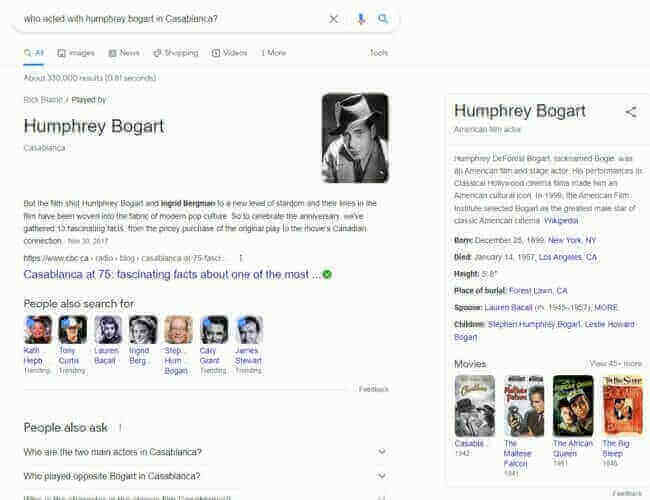
Google ha un brevetto di continuazione dal 3 gennaio 2022. Avevo scritto su una versione precedente di quel brevetto nel 2019 nel post Il Clustering di Entità nei Risultati di Ricerca di Google.
Dichiarazioni del primo brevetto
Poiché questo nuovo brevetto è un brevetto di continuazione, la maggior parte di esso è rimasta identica. Ciò nonostante, nel brevetto sono contenuti alcuni aggiornamenti. La prima dichiarazione della versione 2019 del brevetto Clustering Search Results recita come segue:
1. Un metodo che comprende: determinare gli elementi in risposta a una query; generare cluster di primo livello degli elementi, ogni cluster rappresenta un’entità in una base di conoscenza e include elementi mappati all’entità; calcolare un rispettivo punteggio per ogni cluster di primo livello, dove questo punteggio si basa su un rispettivo punteggio silhouette che misura la coerenza e la separazione del cluster di primo livello e su un rapporto silhouette che rappresenta una percentuale di tutti i cluster di primo livello che hanno un punteggio sopra una soglia; fondendo i cluster di primo livello basati sulle relazioni dell’ontologia delle entità e sui rispettivi punteggi dei cluster calcolati per i cluster fusi, dove il rispettivo punteggio di un cluster fuso rappresenta un punteggio migliore dei rispettivi punteggi dei cluster di primo livello inclusi nel cluster fuso; applicando il clustering gerarchico ai cluster fusi, producendo cluster finali che massimizzano i rispettivi punteggi dei cluster per il clustering gerarchico; e fornendo gli elementi che rispondono alla richiesta di visualizzazione secondo i cluster finali.
Dichiarazioni del brevetto aggiornato
Il post che ho scritto nel 2019 descrive il processo dietro il brevetto sul clustering di entità. Ora, la nuova versione del brevetto dell’inizio del 2022 ha un nuovo linguaggio che ci dice cosa fa il brevetto. La prima serie di dichiarazioni del 1999 ci parlava di un “punteggio di silhouette”, che non è nelle versioni successive. A sua volta, le dichiarazioni del 2022 includono alcuni termini che non sono nella versione del 2019:
1. Un metodo eseguito da un motore di ricerca che comprende: determinare un insieme di elementi che rispondono a una query; per ogni elemento dell’insieme di elementi determinato per rispondere alla query: identificando una o più entità associate con l’articolo e ottenendo un embedding per l’articolo; generando i cluster di primo livello dall’insieme degli articoli, ogni cluster che rappresenta un’entità dell’una o più entità; producendo i cluster finali unendo i cluster di primo livello basati sulle relazioni ontologiche dell’entità e sulle somiglianze dell’embedding determinate usando gli embeddings dell’articolo, in cui le relazioni ontologiche dell’entità includono hypernym, synonym e co-hypernym; e fornendo gli articoli dall’insieme degli articoli rispondenti alla richiesta per esposizione secondo i cluster finali.
2. Il metodo della dichiarazione 1, in cui i cluster di primo livello che sono più piccoli sono fusi prima.
3. Il metodo della dichiarazione 2, in cui la fusione dei cluster di primo livello che sono più piccoli include, per un primo cluster di primo livello: determinare un secondo cluster di primo livello e un terzo cluster di primo livello relativo al primo cluster di primo livello basato sulle relazioni ontologiche delle entità; determinare che il terzo cluster di primo livello e il cluster di primo livello sono più piccoli del secondo cluster di primo livello; e fondere il cluster di primo livello con il terzo cluster di primo livello.
4. Il metodo della dichiarazione 1, in cui i cluster di primo livello che sono più simili sono fusi per primi.
5. Il metodo della dichiarazione 4, in cui la fusione dei cluster di primo livello più simili include, per un primo cluster di primo livello: determinare un secondo cluster di primo livello e un terzo cluster di primo livello relativi al primo cluster di primo livello nelle relazioni ontologiche delle entità; determinare che il cluster di primo livello è più simile al secondo cluster di primo livello rispetto al terzo cluster di primo livello; e fondere il cluster di primo livello con il secondo cluster di primo livello.
La versione più recente ci dice che include “relazioni ontologiche”, cosa che la prima serie di affermazioni non fa. Così, sappiamo dalle SERP che Bogart era nel film “Casablanca”, così come molti altri attori che erano concentrati su quel risultato di ricerca.
Clustering risultati di ricerca
Inventori: Jilin Chen, Dai; Lichan Hong, Tianjiao Zhang, Huazhong Ning e Ed Huai-Hsin Chi
Cessionario: Google LLC
Brevetto USA: 11,216,503
Concesso: 4 gennaio 2022
Archiviato: 26 novembre 2019
Abstract
Le implementazioni forniscono un sistema migliorato per la presentazione dei risultati di ricerca basati sul clustering di entità degli elementi di ricerca. Un metodo di esempio include la generazione dei cluster di primo livello degli articoli che rispondono ad una domanda, ogni cluster che rappresenta un’entità in una base di conoscenza e che include gli articoli mappati all’entità, fondendo i cluster di primo livello basati sulle relazioni dell’ontologia dell’entità, applicando i cluster gerarchici ai cluster fusi, producendo i cluster finali ed iniziando la visualizzazione degli articoli secondo i cluster finali. Un altro metodo di esempio include la generazione dei cluster di primo livello dagli articoli che rispondono ad una richiesta, ogni cluster che rappresenta un’entità in una base di conoscenza e che include gli articoli mappati all’entità, producendo i cluster finali fondendo i cluster di primo livello basati su un’ontologia dell’entità e su uno spazio di incorporazione che è generato da un modello di incorporazione che usa la mappatura e iniziando la visualizzazione degli articoli che rispondono alla richiesta secondo i cluster finali.
Se torni al mio articolo originale su questo brevetto del 2019, vedrai che menziono “ontologie” molte volte quando scrivo di entità. La versione 2022 del brevetto sul clustering delle entità aggiunge quel linguaggio direttamente nelle dichiarazioni. Sono nelle SERP senza discutere la relazione tra il film e i suoi attori.
Clustering di entità e notizie
Dopo questo cambiamento, quando cerchiamo un’entità specifica e una notizia, vediamo anche lì risultati di ricerca raggruppati:
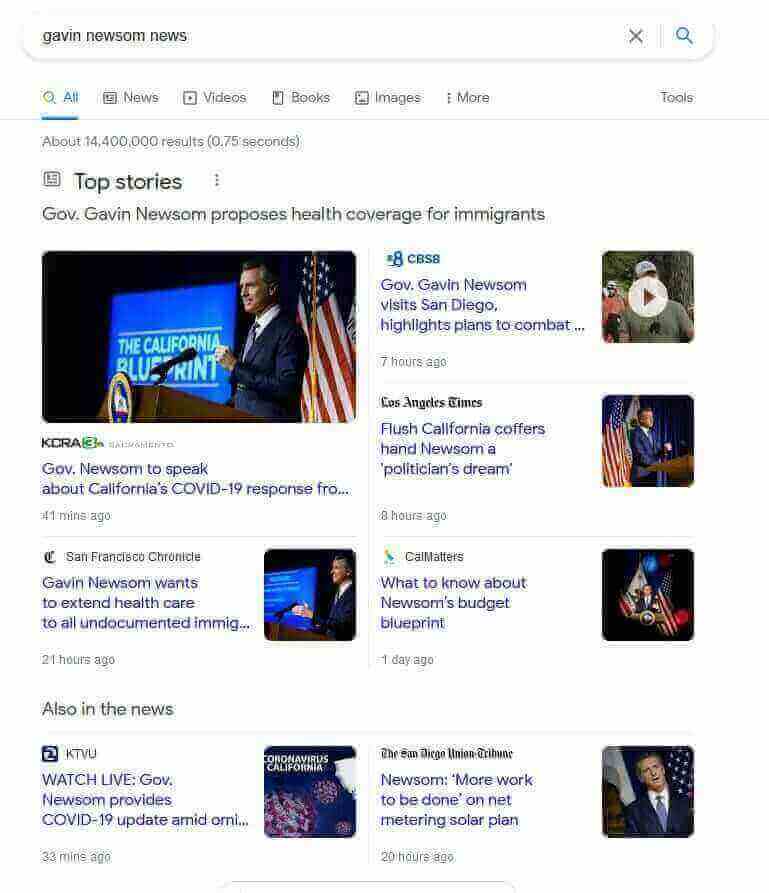
Così Google non sta più ordinando le SERP in base a quanto bene i documenti corrispondono ai termini della query – Google sta raggruppando gli argomenti e le relazioni tra le entità come parte della sua decisione su cosa includere nei risultati di ricerca.