If you are a developer, you probably have already worked with or heard about SEO (Search Engine Optimization). Nowadays, when optimizing websites for search engines, the focus is on annotating websites’ content so that search engines can easily extract and “understand” the content. Annotating, in this case, is the representation of information presented on a website in a machine-understandable way by using a specific predefined structure. Noteworthy, the structure must be understood by the search engines. Therefore, in 2011 the four most prominent search engine providers Google, Microsoft, Yahoo!, and Yandex, founded Schema.org. Schema.org provides patterns for the information you might want to annotate on your websites, including some examples. Those examples allow web developers to get an idea of making the information on their website understandable by search engines.
Knowledge Graphs
Besides using the websites’ annotations to provide more precise results to the users, search engines use them to build so-called Knowledge Graphs. Knowledge Graphs are huge semantic nets describing “things” and their connections between each other.
Consider three “things”, i.e. three hiking trails “Auf dem Jakobsweg”, “Lofer – Auer Wiesen – Maybergklamm” and “Wandergolfrunde St. Martin” which are located in the region “Salzburger Saalachtal” (another “thing”). “Salzburger Saalachtal” is located in the state “Salzburg,” which is part of “Austria.” If we drew those connections on a sheet, we would end up with something that looks like the following.
This is just a small extract of a Knowledge Graph, but it shows pretty well how things are connected with each other. Search engine providers collect data from a vast amount of websites and connect the data with each other. Not only search engine providers are doing so but even more companies are building Knowledge Graphs. Also, you can build a Knowledge Graph based on your annotations, as they are a good starting point. Now you might think that the amount of data is not sufficient for a Knowledge Graph. It is essential to mention that you can connect your data with other data sources, i.e., link your data or import data from external sources. There exists a vast Linked Open Data Cloud providing linked data sets of different categories. Linked in this case means that the different data sets are connected via certain relationships. Open implies that everyone can use it and import it into its own Knowledge Graph.
An excellent use case for including data from the Linked Open Data Cloud is to integrate geodata. For example, as mentioned earlier, the Knowledge Graph should be built based on the annotations of hiking trails. Still, you don’t have concrete data on the cities, regions, and countries. Then, you could integrate geodata from the Linked Open Data Cloud, providing detailed information on cities, regions, and countries.
Over time, your Knowledge Graph will grow and become quite huge and even more powerful due to all the connections between the different “things.”
Sounds great, but how can I use the data in the Knowledge Graph?
Unfortunately, this is where a huge problem arises. For querying the Knowledge Graph, it is necessary to write so-called SPARQL queries, a standard for querying Knowledge Graphs. SPARQL is challenging to use if you are not familiar with the syntax and has a steep learning curve. Especially, if you are not into the particular area of Semantic Web Technologies. In that case, you may not want to learn such a complex query language that is not used anywhere else in your daily developer life. However, SPARQL is necessary for publishing and accessing Linked Data on the Web. But there is hope. We would not write this blog post if we did not have a solution to overcome this gap. We want to give you the possibility, on the one hand, to use the strength of Knowledge Graphs for storing and linking your data, including the integration of external data, and on the other hand, a simple query language for accessing the “knowledge” stored. The “knowledge” can then be used to power different kinds of applications, e.g., intelligent personal assistants. Now you have been tortured long enough. We will describe a simple middleware that allows you to query Knowledge Graphs by using the simple syntax of GraphQL queries.
What is GraphQL?
GraphQL is an open standard published in 2015, initially invented by Facebook. Its primary purpose is to be a flexible and developer-friendly alternative to REST APIs. Before GraphQL, developers had to use API results as predefined by the API provider even if only one value was required by the user of the API. GraphQL allows specifying a GraphQL query in a way that only the relevant data is fetched. Additionally, the JSON syntax of GraphQL makes it easy to use. Nearly every programming language has a JSON parser, and developers are familiar with representing data using JSON syntax. The simplicity and ease of use also gained interest in the Semantic Web Community as an alternative for querying RDF data. Graph database (used to store Knowledge Graphs) providers like Ontotex (GraphDB) and Stardog introduced GraphQL as an alternative query language for their databases. Unfortunately, those databases can not be exchanged easily due to the different kinds of GraphQL schemas they require. The GraphQL schema defines which information can be queried. Each of the database providers has its own way of providing this schema.
Additionally, the syntax of the GraphQL queries supported by the database providers differs due to special optimizations and extensions. Another problem is that there are still many services available on the Web that are only accessible via SPARQL. How can we overcome all this hassle and reach a simple solution applicable to arbitrary SPARQL endpoints?
GraphSPARQL
All those problems led to a conceptualization and implementation of a middleware transforming GraphQL into SPARQL queries called GraphSPARQL. As part of the R&D work that we are doing, in the context of the EU-cofounded project called WordLift Next Generation, three students from the University Innsbruck developed GraphSPARQL in the course of a Semantic Web Seminar
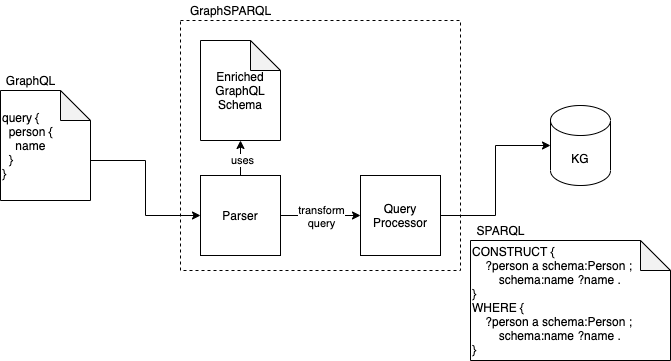
Let us consider the example of a query that results in a list of persons’ names to illustrate the functionality of GraphSPARQL. First, the user needs to provide an Enriched GraphQL Schema, in principle defining the information that should be queryable by GraphSPARQL. This schema is essential for the mapping between the GraphQL query and the SPARQL query.
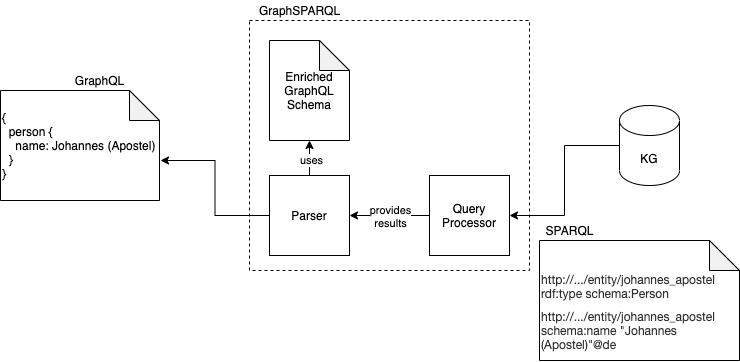
The following figure shows the process of an incoming query and transforming it to a SPARQL query. If you want to query for persons with their names, the GraphQL query shown on the left side of the figure will be used. This query is processed inside GraphSPARQL by a so-called Parser. The Parser uses the predefined schema to transform the GraphQL query into the SPARQL query. This SPARQL query is then processed by the Query Processor. It handles the connection to the Knowledge Graph. On the right side of the figure, you see the SPARQL query generated based on the GraphQL query. It is pretty confusing compared to the simple GraphQL query. Therefore, we want to hide those queries with our middleware.
As a result of the SPARQL query, the Knowledge Graph responds with something that seems quite cryptic, if you are not familiar with the syntax. You can see an example SPARQL response on the following figure’s right side. This cryptic response is returned to the Parser by the Query Processor. The Parser then, again with the help of the schema, transforms the response into a nice-looking GraphQL response. The result is a JSON containing the result of the initial query.
GraphSPARQL provides you easy access to the information stored in a Knowledge Graph using the simple GraphQL query language.
You have a Knowledge Graph stored in a graph database that is accessible via SPARQL endpoint only? Then GraphSPARQL is the perfect solution for you. Before you can start, you need to follow two configuration steps:
Provide the so-called Enriched GraphQL Schema. This schema can either be created automatically based on a given ontology, e.g., schema.org provides its ontology as a download or can be defined manually. An example for both cases can be found on the GraphSPARQL Github page in the example folder: – automatic creation of a schema based on the DBPedia ontology – manually defined schema
Define the SPARQL endpoint GraphSPARQL should connect to. This can be done in the configuration file (see “config.json” in the example folder).
Have you done both preparation steps? Perfect, now you are ready to use GraphSPARQL on the endpoint you defined. Check the end of the blog post if you are interested in a concrete example.
Summary
– What are the benefits of GraphSPARQL? – Benefit from Knowledge Graphs by using a simple query language – Simple JSON syntax for defining queries – Parser support for the JSON syntax of GraphQL queries in nearly all programming languages – GraphQL query structure represents the structure of the expected result – Restrict data access via the provided GraphQL schema
GraphSPARQL as middleware allows querying SPARQL endpoints using GraphQL as a simple query language and is an important step to open Semantic Web Technologies to a broader audience.
Example
Docker container to test GraphSPARQL:
Two options to start the docker container are supported so far:
Use predefined configuration for DBPedia: start the GraphSPARQL docker container
If you work in SEO, you have been reading about Google and Bing becoming semantic search engines but, what does Semantic Search really mean for users, and how things work under the hood?
Semantic Search helps you surface the most relevant results for your users based on search intent and not just keywords.
Semantic (or Neural) Search uses state of the art deep learning models to provide contextual and relevant results to user queries. When we use semantic search we can immediately understand the intent behind our customers and provide significantly improved search results that can drive deeper customer engagement. This can be essential in many different sectors but – here at WordLift – we are particularly interested in applying these technologies to: travel brands, e-commerce and online publishers.
Information is often unstructured and available in different silos, using semantic search our goal is to use machine learning techniques to make sense of content and to create a context. When moving from syntax (for example how often a term appears on a webpage) to semantics, we have to create a layer of metadata that can help machines grasp the concepts behind each word. Google defines this ability to connect words to concepts as “Neural Matching” or *super synonyms* that help better match user queries with web content. Technically speaking this is achieved by using neural embeddings that transform words (or other types of content like images, video or audio clips) to fuzzier representations of the underlying concepts.
As part of the R&D work that we’re doing, in the context of the EU-cofounded project called WordLift Next Generation, I have built the prototype using an emerging open-source framework called Jina AI and the beautiful photographic material published by Salzburgerland Tourismus (also a partner in the Eurostars research project) and Österreich Werbung 🇦🇹 (Austrian National Tourist Office).
I have created this first prototype:
☝️ to understand how modern search engines work;
✌️ to re-use the same #SEO data that @wordliftit publishes as structured *linked* data for internal search.
How does Semantic Search work?
Bringing structure to information, is what WordLift does by analyzing textual information using NLP and named entity recognition, and now also images using deep learning models.
With semantic search, these capabilities are combined to let users find exactly what they need naturally.
In Jina, Flows are high-level concepts that define a sequence of steps to accomplish a task. Indexing and querying are two separate Flows; inside each flow, we run parallel Pods to analyze the content. A Pod is a basic processing unit in a Flow that can run as a dockerized application.
This is strategic as it allows us to distribute the load efficiently. In this demo, Pods are programmed to create neural embeddings: one pod to processes text and one for images. Pods can also run in parallel and the results (embeddings from the caption and embeddings from the image) are combined into one single document.
This ability to work with different content types is called multi-modality.
The user uses a text in the query to retrieve an image or vice-versa; the user uses an image, in the query, to retrieve its description.
See in the example below; I make a search using natural language at the beginning and right after, I send an image (from the results of the first search) as query to find its description 👇
Are you ready to innovate your content marketing strategy with AI? Let’s talk!
What is Jina AI?
Han Xiao, Jina AI’s CEO, calls Jina the “TensorFlow” for search 🤩. Besides the fact that I love this definition, Jina is completely open source, and designed to help you build neural (or semantic) search on the cloud. Believe me it is truly impressive. To learn more about Jina, watch Han’s latest video on YouTube “Jina 101: Basic concepts in Jina“.
How can we optimize content for Semantic Search?
Here is what I learned from this experiment:
When creating content, we shall focus on concepts (also referred to as entities) and search intents rather than keywords. An entity is a broader concept that groups different queries. The search intent (or user intent) is the user’s goal when making the query to the search engine. This intent can be expressed using different queries. The search engines interpret and disambiguate the meaning behind these queries by using the metadata that we provide.
Information Architecture shall be designed once we understand the search intent. We are used to thinking in terms of 1 page = 1 keyword, but in reality, as we transition from keywords to entities (or concepts), we can cover the same topic across multiple documents. After crawling the pages, the search engine will work with a holistic representation of our content even when it has been written across various pages (or even different media types).
Adding structured data for text, images, and videos adds precious data points that will be taken into account by the search engine. The more we provide high-quality metadata, the more we help the semantic search engine improve the matching between content and user intent.
Becoming an entity in Google’s Knowledge Graph also greatly helps Google understand who we are and what we write about. It can have an immediate impactacross multiple queries that refer to the entity. Read this post to learn more how to create an entity in Google’s graph.
Working with Semantic Search Engines like Google and Bing, require an update of your content strategy and a deep understanding of the principles of Semantic SEO and machine learning.
In the last two decades, text summarization has played an essential role in search engine optimization (SEO). There are, indeed, a lot of different marketing techniques that require a summary of the content, and that can improve ranking in search engines. Meta descriptions are probably among the most notable examples (here is a video tutorial that Andrea did on generating meta descriptions).
These text snippets provide search engines with a brief description of the page content and are still an important ranking factor and one of the most common use cases for text summarization.
Thanks to the latest NLP technologies, SEO specialists can finally summarize the content of entire webpages using algorithms that craft easy-to-read summaries.
In this article, we will discuss the importance of using text summarization in the context of SEO and digital marketing.
Summaries help create and structure the metadata that describes web pages. Text summarization also comes in handy when we want to add descriptive text to category pages for magazines and eCommerce websites or when we need to prepare the copy for promoting our latest article to Facebook or Twitter. Much like search engines use meta descriptions, social networks rely on their meta descriptors like the Facebook Open Graph meta tag (a.k.a. OG tag) to distribute content to their users. Facebook for instance, uses the summary provided in OG tags to create the card that promotes a blog post on mobile and desktop devices.
Extractive vs Abstractive
There are many different text summarization approaches, and they vary depending on the number of input documents, purpose, and output. But, they all fall into one of two categories: extractive or abstractive.
Extractive summarization algorithms identify essential sections of a text and generate verbatim to produce a subset of the sentences from the original input.
Extractive summaries are reliable because they will not change the meaning of any sentence. They are generally easier to program. It’s very logical, and in the most straightforward implementations, the most common words in the source text are the words that represent the main topic. Using today’s pre-trained Transformer models with their ground-breaking performance, we can achieve excellent results with the extractive approach.
In WordLift, for instance, BERT is used to boost the performance of extractive summarization across different languages. Here is the summary that WordLift creates for me for this article that you are reading.
In the last two decades, text summarization has played an essential role in search engine optimization (SEO). While our existing BERT-based summarization API performs well in German, we wanted to create unique content instead of only shrinking the existing text.
It is quite useful in summarizing, using the most important sentences, the content that I am writing here, and it is formally correct (or at least as valid as my writing) but not unique.
Using Transformers in extractive text summarization.
Abstractive Text Summarization
Abstractive methodologies summarize texts differently, using deep neural networks to interpret, examine, and generate new content (summary), including essential concepts from the source.
Abstractive approaches are more complicated: you will need to train a neural network that understands the content and rewrites it.
In general, training a language model to build abstract summaries is challenging and tends to be more complicated than using the extractive approach. Abstractive summarization might fail to preserve the meaning of the original text and generalizes less than extractive summarization.
As humans, when we try to summarize a lengthy document, we first read it entirely very carefully to develop a better understanding; secondly, we write highlights for its main points. As computers lack most of our human knowledge, they still struggle to generate summaries’ human-level quality.
Moreover, using abstractive approaches also poses the challenge of supporting multilingualism. The model needs to be trained for each language separately.
Training our new model for German using Google’s T5
T5 text-to-text framework pre-trained on a multi-task mixture of NLP unsupervised and supervised tasks.
As part of the WordLift NG project and, on behalf of one of our German-speaking clients, we ventured into creating a new pre-trained language model for automatic text summarization in German. While our existing BERT-based summarization API performs well in German, we wanted to create unique content instead of only shrinking the existing text.
This new language model is revolutionary as we can re-use the same model for different NLP tasks, including summarization. T5 is also language-agnostic, and we can use it with any language.
We successfully trained the new summarizer on a dataset of 100,000 texts together with reference summaries extracted from the German Wikipedia. Here is a result where we see the input summary that was provided along with the full text of the Wikipedia page on Leopold Wilhelm and the predicted summary generated by the model.
Conclusions and future work
We are very excited about this new line of work and we will continue experimenting new ways to help editors, SEOs and website owners improve their publishing workflows with the help of NLP, knowledge graphs and deep learning!
WordLift provides websites with all the AI you need to grow your traffic — whether you want to increase leads, accelerate sales on your e-commerce or build a powerful website. Let’s talk with our expert to find out more!
WordLift, Redlink GmbH, SalzburgerLand Tourismus GmbH and the Department of Computer Science of the University of Innsbruck teamed up under the WordLift Next Generation project to develop a new platform to deliver Agentive SEO technology to any website. The work started in February and will last for 36 months.
We are pleased to announce that we have received funding support from EU to develop a new technology that will be available for any Content Management System.
The project, called WordLift Next Generation, will be developed with the financial support received from Eurostars H2020, a program promoted by the European Union that supports research activities and innovative SMEs. WordLift NG is part of a financing plan allocated by the EU to make European companies more competitive through AI tools at the service of businesses and people.
As WordLift CEO Andrea Volpini stated recently, “Artificial Intelligence is shaping the online world with huge investments from GAFAM (Google, Apple, Facebook, Amazon e Microsoft). Our company successfully brought these technologies to mid/small size content owners, SMEs and news publishers worldwide using WordPress. It’s time to expand outside of the WordPress ecosystem while adding new services such as semantic search, improved content recommendations and conversational UIs for the Google Assistant and Alexa to help this market segment remain competitive.”
WordLift automates and streamlines the technical processes required to make a website discoverable through search engines and personal digital assistant; we have been first to market a Knowledge Graph optimized for SEO, combining semantic annotations with information publicly available as linked open data.
Goals of the Project
With WordLift NG, the consortium plans to improve the way in which our software understands web articles and builds knowledge bases, employing semantic technology. With a more powerful knowledge graph, it will be possible to fully decouple WordLift from WordPress to make this technology available to any website worldwide. The consortium also aims to improve the quality of the content recommendations and to bring an engaging semantic search experience. Last but not least, as the knowledge base behind each website will improve, it will be possible to enable conversational experiences over Google Assistant and Alexa (focus will be on news and media and hospitality sector).
The first partner meeting in Rome — February 2020
Meet the Consortium
To achieve these ambitious goals, WordLift has teamed with leading organizations in Europe in the field of AI, NLP and Semantic Technologies and tourismus: Redlink GmbH (led by Andreas Gruber CEO of the company), the Semantic Technology Institute at the Department of Computer Science of the University of Innsbruck (under the supervision of Ass.-Prof. Dr. Anna Fensel) and, SalzburgerLand Tourismus GmbH (with Martin Reichhart, Innovation Manager as coordinator).
Thanks to the EU funded project and the collaboration between Italy and Austria, WordLift NG will democratize the usage of agentive SEO, developing a complete new technology stack to help businesses around the world remain competitive in the ever-changing search and digital marketing landscape. The project has officially started on February 1, 2020, and will be completed in 36 months.












Recent Comments