Come funziona il dialogo tra uomo e computer su Google
Scopri come funziona il dialogo tra uomo e computer e come possiamo costruire conversazioni sempre più reali con gli assistenti di Google attraverso il linguaggio naturale.

Dialogo uomo-computer consapevole del contesto
I ricercatori possono sempre più interagire con i computer usando il linguaggio naturale nel “dialogo da uomo a computer”. Ho scritto in precedenza su come un computer potrebbe rispondere a un ricercatore con risposte alle query in linguaggio naturale, e come questo potrebbe richiedere al computer di capire cose come le regole grammaticali e alcune delle altre stranezze delle conversazioni che gli umani hanno. Un brevetto concesso a Google il 18 gennaio 2022, riguarda alcuni dei problemi che un computer potrebbe avere quando conversa con un essere umano usando il linguaggio naturale.
Ho scritto sugli assistenti automatici di Google e sulle conversazioni tra computer e umani. Un post era sulle discussioni tra Google e i bambini, nel post How an Automated Assistant May Respond to Queries from Children. E un post più recente era su come un assistente automatizzato di Google può utilizzare modelli multimodali (altrimenti detto MUM) nel post Google Mum Update.
Gli assistenti automatizzati possono essere impostati per comprendere e rispondere alle query in linguaggio naturale con risposte comprensibili agli esseri umani in aree come:
- Risposta alle domande
- Iniziazione di un compito
- Riconoscimento di entità
- Raccomandazioni
Questo recente brevetto su “Context-Aware Human to Computer Dialog” ci dice che il problema con tali software è che quei programmi hanno “difficoltà a passare da un dominio all’altro della conversazione”.
Cosa significa esattamente?
Le persone cambiano argomento – un ricercatore e un assistente automatico parlano di un argomento (come il gioco), e il ricercatore cambia la conversazione verso un argomento non correlato (come il tempo). L’assistente automatico potrebbe non essere molto reattivo e potrebbe aver bisogno di più dialogo per rispondere in modo appropriato. Può essere difficile per un assistente computerizzato anticipare il modo in cui un ricercatore può cambiare argomento.
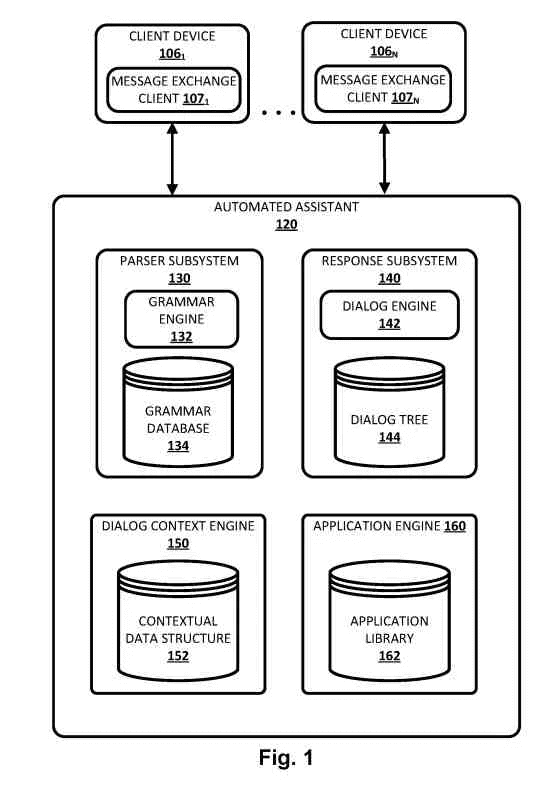
Viene descritto un approccio per migliorare un dialogo uomo-computer per rendere un assistente automatico capace di interpretare e rispondere quando un ricercatore cambia l’argomento del dialogo uomo-computer tra i soggetti. Una “struttura di dati contestuale” può essere usata per mantenere “argomenti” rilevanti per un dialogo uomo-computer in corso. Gli argomenti potrebbero aiutare a selezionare la grammatica per capire cosa sta dicendo il ricercatore.
Basandosi sulle grammatiche scelte, e possibilmente su un albero di dialogo dinamico che rappresenta il dialogo in corso tra persone e computer, una risposta in linguaggio naturale per qualcosa come l’inizio di un compito può essere creata e usata dall’assistente automatico. Nel frattempo, i nuovi argomenti aggiunti al dialogo tra il ricercatore e l’assistente computerizzato possono essere aggiunti alla struttura dati contestuale. Gli argomenti che non sono stati menzionati o a cui si è alluso per un certo tempo possono essere eliminati. Ciò significa che se un ricercatore fornisce un input in linguaggio naturale su un argomento non immediatamente pertinente che può essere stato pertinente a qualche questione precedente del dialogo in corso tra uomo e computer, l’assistente automatizzato può essere in grado di tornare all’argomento precedente senza problemi.
Filtraggio contestuale del dialogo tra uomo e computer
Questa tecnica viene chiamata “filtraggio contestuale”.
Il filtraggio contestuale può evitare grammatiche che non hanno senso nel contesto della conversazione e potrebbero portare a un output senza senso.
Questo filtraggio può ridurre la grammatica applicata all’input del linguaggio naturale da parte di un umano. Questa riduzione significa ridurre l’uso dell’informatica, come i cicli del processore, la memoria e la larghezza di banda della rete. Questo può avvantaggiare i dialoghi tra uomo e computer migliorando l’efficacia di un assistente automatico e aiutandolo a rispondere all’input il più velocemente possibile.
La struttura dei dati contestuali
Se un dialogo uomo-computer è appena iniziato, e nessun argomento è pertinente, il computer può elaborare il linguaggio naturale usando tecniche convenzionali. Il sottosistema può popolare la struttura di dati contestuali in base alle questioni sollevate da un umano o da un assistente automatizzato durante il dialogo uomo-computer.
La struttura di dati contestuale può prendere molte strutture di dati immagazzinate nella memoria. Può essere usata per mantenere gli argomenti che sono stati recentemente rilevanti per un dialogo uomo-computer in corso. Quando un problema viene sollevato dal ricercatore o dall’assistente automatico, l’argomento può essere aggiunto alla struttura dati contestuale. Se un caso viene introdotto nella struttura dati contestuale, l’argomento può essere “toccato” o portato in primo piano nella conversazione ancora una volta.
In questo modo, ogni argomento nella struttura di dati contestuale può essere associato a una misura di rilevanza per il dialogo tra uomo e computer.
Determinare la rilevanza degli argomenti per un dialogo
La rilevanza di ogni argomento può essere determinata in parte contando i passaggi del dialogo uomo-computer dall’ultima volta che l’argomento è stato sollevato.
Più passaggi da quando l’argomento è stato sollevato (o aggiunto o toccato), più bassa è la rilevanza. Supponiamo che un ricercatore abbia iniziato un dialogo da uomo a computer sul tempo (il che causerebbe l’aggiunta del caso “tempo”). Tuttavia, il dialogo copriva una vasta gamma di questioni non legate al tempo. Più passaggi nel dialogo da quando è stato sollevato l’argomento del tempo, più il punteggio di rilevanza associato al tempo è diminuito.
Eliminazione di un argomento di rilevanza da un dialogo
Se l’uomo e il computer smettono di parlare di qualcosa, e un argomento diminuisce sotto una soglia di rilevanza, quell’argomento può essere eliminato del tutto dalla struttura dati contestuale.
Eliminare gli argomenti “stantii” dalla struttura dei dati contestuali può offrire vantaggi tecnici.
Più argomenti vengono filtrati contestualmente e rimossi come argomenti, più tematiche stantie vengono rilasciate. Eliminare gli argomenti stantii significa ridurre il consumo di risorse di calcolo.
E più attenzione può essere data agli argomenti rilevanti nel dialogo uomo-computer. Diventa meno probabile che vengano prodotti argomenti fuori tema o altrimenti insensati, il che significa meno possibilità che l’assistente automatico fornisca output altrettanto insensati.
Così, il numero di giri di dialogo da uomo a computer (e quindi, gli input di linguaggio naturale forniti dal ricercatore) richiesti per raggiungere l’obiettivo particolare di un ricercatore può essere ridotto. Questo può avvantaggiare i ricercatori con limitate capacità fisiche o situazionali di fornire input multipli.
Altri fattori per le misure di rilevanza nel dialogo tra uomo e computer
Relatività degli argomenti – La misura della rilevanza di ogni argomento può essere basata sulla relazione (ad esempio, semantica) tra l’argomento e altri argomenti nella struttura contestuale dei dati.
Così, se un primo argomento non è stato sollevato per un po’, ma un secondo argomento semanticamente correlato viene sollevato più tardi, la misura della rilevanza del primo argomento può essere presentata.
Il brevetto ci dice che:
La struttura dei dati contestuali può assumere la forma di un grafico non diretto che comprende una pluralità di nodi e una pluralità di bordi che collegano la pluralità di nodi. Ogni nodo del grafo indiretto può rappresentare un dato argomento degli argomenti memorizzati come parte della struttura di dati contestuali. Ogni nodo può anche memorizzare un conteggio del dialogo uomo-computer in corso da quando il dato argomento è stato sollevato. Ogni bordo che collega due nodi può rappresentare una misura di parentela (per esempio, semantica, ecc.) tra due argomenti rappresentati dai due nodi, rispettivamente. Naturalmente, altre strutture di dati sono contemplate qui.
Inoltre, ogni grammatica può essere associata sia a un argomento che a un punteggio di rilevanza di soglia per quell’argomento.
Se l’argomento persiste nella struttura dati contestuale, ma il suo punteggio di rilevanza non soddisfa la soglia, la grammatica non può essere selezionata.
Ci viene detto che questo permette una regolazione fine di quando le grammatiche saranno applicate e quando no.
Questa comprensione degli argomenti può utilizzare grammatiche selezionate e applicate dal sottosistema parser.
Il sottosistema parser può anche fornire al sottosistema di risposta degli argomenti come parte dei parses/interpretazioni separatamente.
Questi argomenti possono trovarsi nella struttura dati contestuale e sono stati toccati dalle loro grammatiche associate che vengono applicate.
Il sottosistema di risposta può usare un albero di dialogo per dirigere il dialogo in corso da uomo a computer tra argomenti apparentemente non correlati.
In sostanza, il sottosistema di risposta interpreta gli argomenti dal sottosistema parser e dirige la conversazione lungo l’albero di dialogo in base alle questioni precedentemente sollevate.
Nodi nell’albero di dialogo
Ogni nodo dell’albero di dialogo rappresenta un processo del linguaggio naturale.
Un nodo radice dell’albero di dialogo può gestire qualsiasi input in linguaggio naturale, e può farlo iniziando un processo richiedendo la disambiguazione al ricercatore. Può quindi attivare i nodi figli corrispondenti ai processi creati in risposta all’input del linguaggio naturale da parte del ricercatore.
I processi figli possono aggiungere ulteriori processi figli per gestire aspetti del dialogo interno.
Aggiungere argomenti correlati al dialogo tra uomo e computer
Quando il sottosistema di risposta genera una risposta, come una risposta in linguaggio naturale o un’azione o un compito di risposta, per il ricercatore, il sottosistema di risposta può aggiungere argomenti correlati alla struttura dati contestuale.
Ogni nodo dell’albero di dialogo può essere associato ad argomenti (per esempio, essere selezionato da uno sviluppatore del processo sottostante il nodo).
Questa seguente dichiarazione dal brevetto mi ricorda l’uso di Google di FrameNet, di cui ho scritto in Semantic Frames and Word Embeddings at Google:
Come notato sopra, ogni grammatica può anche essere associata ad argomenti. Di conseguenza, aggiungendo questi argomenti alla struttura di dati contestuali, il sottosistema di risposta aggiunge il numero di grammatiche che il sottosistema del parser può applicare in qualsiasi momento. Così, se un ricercatore parla di un argomento, cambia rotta e poi ritorna all’argomento originale (o a un argomento semanticamente correlato), le grammatiche associate all’argomento originale possono ancora essere applicabili perché gli argomenti associati sono conservati nella struttura dati contestuale. Ma come notato sopra, se il dialogo uomo-computer si allontana abbastanza a lungo da un dato argomento, l’argomento può essere eliminato dalla struttura dati contestuale, per esempio, per evitare che il sottosistema del parser applichi un numero eccessivo di grammatiche ad ogni input di linguaggio naturale, il che può diventare computazionalmente costoso.
Dialogo tra uomo e computer come convergenza
Il brevetto ci parla di una conversazione tra un ricercatore e un computer. Dice che un ricercatore può iniziare un dialogo da uomo a computer con la frase: “Facciamo un gioco”. Il computer potrebbe rispondere all’argomento di un gioco con “Ok, a quale gioco vuoi giocare?
Il computer potrebbe fare qualcosa come elencare i giochi disponibili, come “Ho Sports Trivia e Historical Trivia.” per filtrare contestualmente la direzione della conversazione.
I vantaggi tecnici derivanti dal seguire questo approccio di filtraggio contestuale degli argomenti come descritto dal brevetto possono includere:
Cambiamento fluido degli argomenti di conversazione senza richiedere agli sviluppatori individuali di spendere considerevoli risorse per gestire il cambiamento degli argomenti
Limitare il numero di interpretazioni degli argomenti a solo quelli che hanno senso nel contesto di dialogo corrente può aiutare a preservare la memoria, i cicli del processore, la larghezza di banda della rete, ecc.
Determinare il design delle finestre di dialogo da parte di assistenti automatici, il che potrebbe renderle più facili da mantenere, e potrebbe consentire un facile riutilizzo del codice
La logica di business potrebbe essere sviluppata rapidamente in un unico linguaggio di programmazione, C++.
Questo brevetto di dialogo da uomo a computer si trova a:
Context-aware human-to-computer dialog
Inventori: Piotr Takiel
Cessionario: GOOGLE LLC
Brevetto USA: 11,227,124
Concesso: 18 gennaio 2022
Archiviato: 7 marzo 2019
Abstract
Metodi, apparecchi e supporti leggibili dal computer sono descritti relativi all’utilizzo di un contesto di un dialogo umano-computer in corso per migliorare la capacità di un assistente automatizzato di interpretare e rispondere quando un ricercatore bruscamente transizioni tra diversi domini (soggetti).
In varie implementazioni, l’input del linguaggio naturale può essere ricevuto da un ricercatore durante un dialogo in corso dell’uomo–informatico con un assistente automatizzato.
La grammatica (o le grammatiche) possono essere selezionate per analizzare l’input di linguaggio naturale.
La selezione può ottenere basata sull’argomento (s) immagazzinato come componente di una struttura di dati contestuale connessa con il dialogo continuo dell’uomo–informatico. L’input di lingua naturale può essere analizzato basato sulla grammatica selezionata per generare parse.
Sulla base dell’analisi, una risposta in lingua naturale può essere generata e trasmessa al ricercatore utilizzando un dispositivo di output. Qualsiasi argomento sollevato dall’analisi o dalla risposta in linguaggio naturale può essere identificato e aggiunto alla struttura dei dati contestuali.
Conclusione del dialogo tra uomo e computer
Il brevetto fornisce maggiori dettagli. Tuttavia, Google ha fornito alcuni esempi di conversazioni tra esseri umani e computer, che sono eccitanti e divertenti da ascoltare. Potrebbe essere meglio iniziare ascoltando questi esempi.
Una conversazione coinvolge un dialogo con un aeroplano di carta:
Google ha anche mostrato le capacità linguistiche che ha sviluppato, mostrando una conversazione con il pianeta Plutone:
Stai ascoltando i cambiamenti di argomenti in quelle conversazioni? O cosa tiene insieme tali discussioni? Stiamo insegnando a Google come avere conversazioni con gli esseri umani partecipando a tali dialoghi?