Providing your website with a structured content model is not only the best solution to better organize your content, but also a powerful strategy to improve the SEO of your website and increase organic traffic.
In this article, we’ll explain how the WordLift entity-based model, coupled with the new feature WL Mappings, will allow you to add a more specific markup to your content and to obtain a Knowledge Graph capable of communicating to search engines in a more effective way.
Why is the content model becoming a key tool for SEO?
During his webinar on content modeling for SEO in the WordLift Academy, Cruce Saunders highlights some of the main features that make the content model an indispensable tool for managing and enhancing online content.
In fact, the content model:
Specifies how information is organized on your website
Makes content more visible to search engines
Allows you to reuse content through different channels
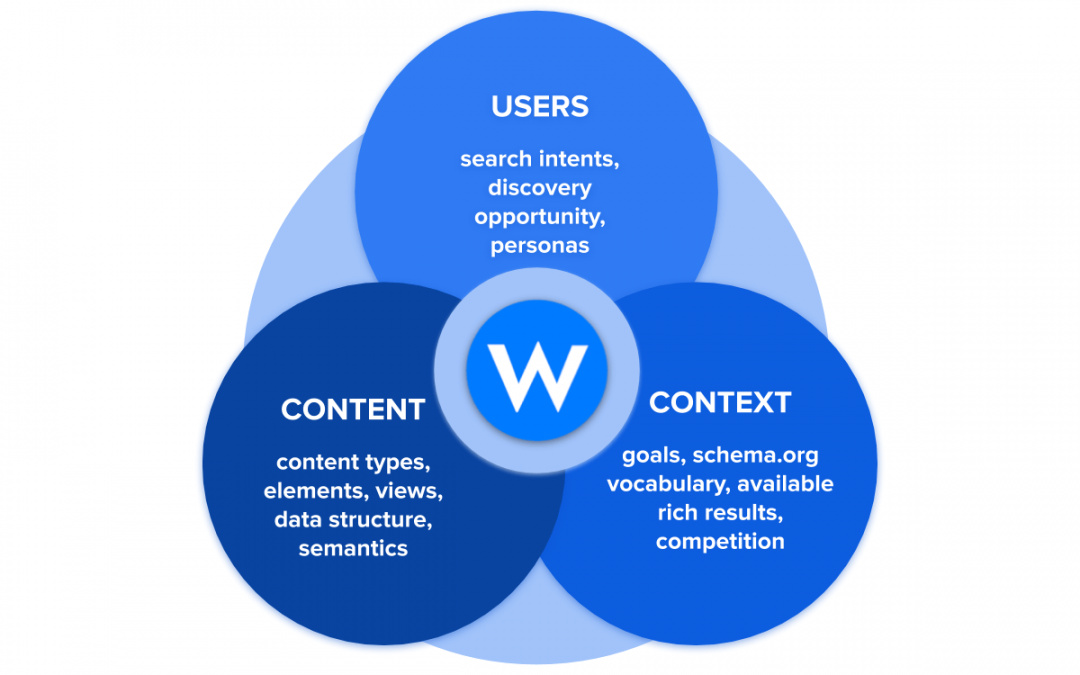
Structured content model, in short, not only allows you to better organize data and information but to do it within a malleable structure capable of communicating:
to search engines through the use of structured data
to users through the enhancement of the user experience and the possibility of reusing the content by presenting it in the form of different layouts both on the site and in the SERP to respond to specific search intents (the same article, for example, may appear in the form of a snippet, of blue link, promotion, etc.)
Structuring your content model means creating a three-dimensional identity capable of highlighting your content and the relationships underlying it. This allows search engines to recognize you among hundreds of pieces of information, making you more visible to users who correspond to the search intent related to your business.
The more the content model is rich in structured data, the more chances you’ll have to meet exactly the users interested in you. That’s why we created WordLift Mappings, a new feature that allows you to select the information and connections that are truly relevant for your business and to create an increasingly specific and refined Knowledge Graph to highlight only the most relevant facets that make your identity more authoritative.
Through our entity-based model and WordLift Mappings, your content model becomes a powerful SEO weapon and a valuable resource to increase the value of your online data.
WordLift Mappings helps you create a custom Knowledge Graph and increase your online authority
WordLift creates a personalized and highly performing Knowledge Graph through the schema.org markup and the creation of a customized entity-based vocabulary containing the most relevant data to help Google better understand your online content.
Remember that Google uses entities to satisfy users’ search intent and allow them to find the best results. For this reason, an increasingly refined entity-based model such as WordLift is key to increase the visibility of your content for search engines.
WordLift Mappings increases the accuracy of this process and allows you to take greater care of your content and your Knowledge Graph.
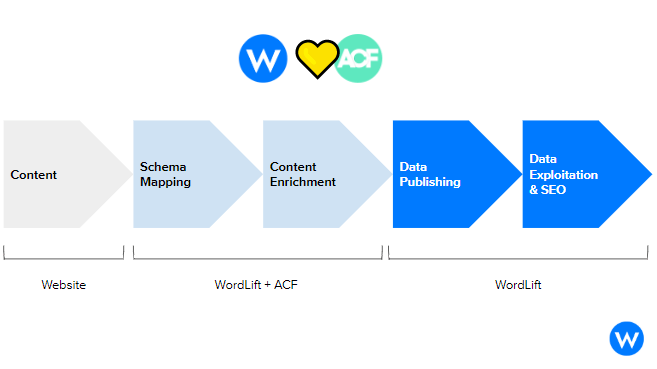
Advanced Custom Field for Schema.org: how the new WordLift extension works
By connecting to ACF (Advanced Custom Field), a WordPress plugin that allows you to create advanced fields to specify the attributes that characterize your content, WordLift Mappings allows you to structure your data starting from the fields that you have already configured with ACF or from new fields based on the schema.org taxonomy.
This means having more and more structured content, which can be used to add relevant details to your Knowledge Graph and shaped in different configurations to improve the user experience.
In this webinar, Andrea Volpini and Jason Barnard explain how they used WordLift Mappings to improve Jason’s content model and Knowledge Graph. Jason shows how he obtains a Knowledge Graph in which only the most relevant data to create an authoritarian and coherent Brand SERP are structured to stand out in the search results.
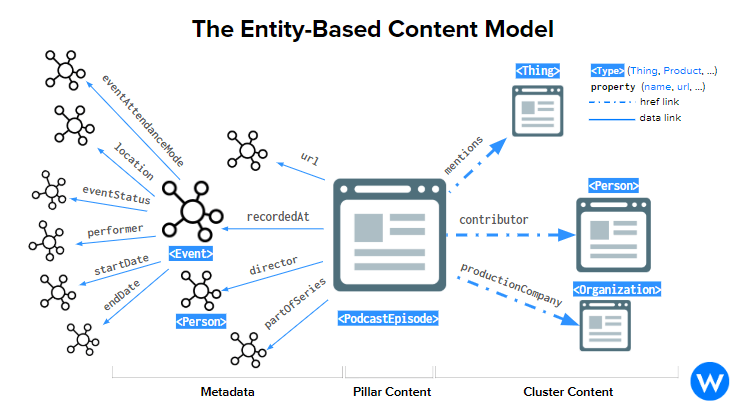
With over 100 podcasts made in collaboration with some of the greatest SEO experts on the planet, Kalicube – Jason Barnard‘s website – has an enviable wealth of content, relevant to the entire digital marketing sector. Thanks to WordLift Mappings, we helped Jason structure this content by following a model that focuses on content, events and people. Thus, each guest of Jason’s podcast has his own page connected with the podcasts in which he participated and with the events in which the podcasts were recorded.
In this way, the architecture of the Knowledge Graph is customized on the basis of the content model and the “network” of the links between the contents becomes the bearer of meanings and allows you to predict further connections. Below you can see the entity-based content model applied to Kalicube through WordLift Mappings.
What can you realistically expect in terms of traffic? How long does it take?
In recent weeks, our SEO team has implemented a new content model on the site of an American customer who deals with the dismantling and re-evaluation of used hardware on a large scale.
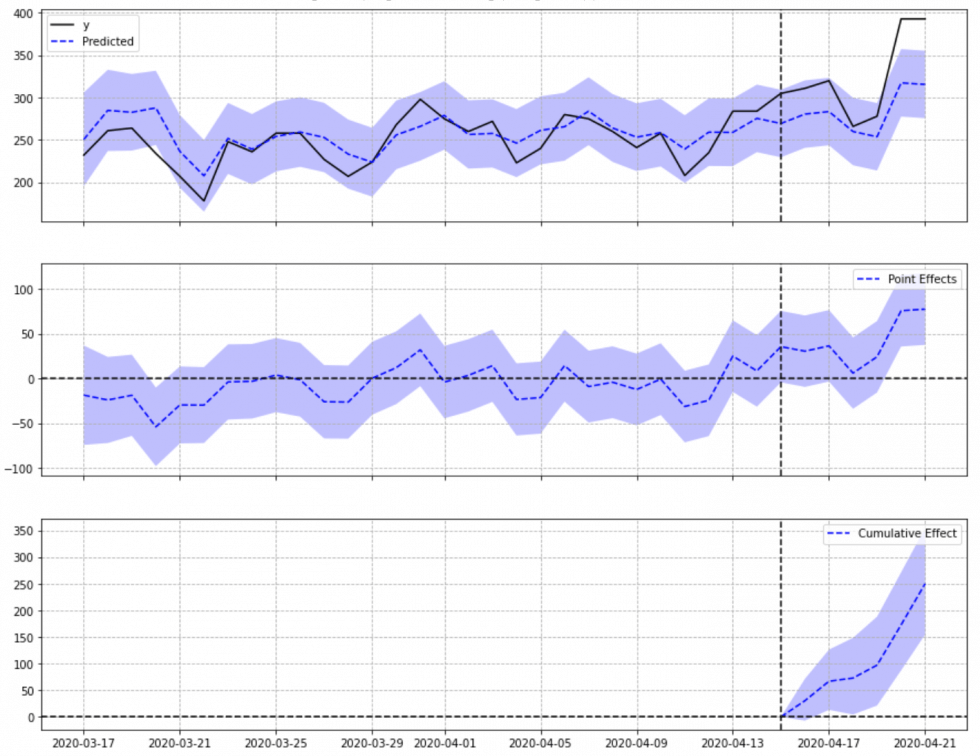
The results? After the first week, traffic increased by 14.6% and the growth curve does not seem to stop. To analyze the impact, isolating other factors that may influence the SEO of the site, we have developed a predictive model based on Bayesian networks which, analyzing the traffic in the month preceding the introduction of the WordLift Mappings, allowed us to isolate the benefit to the net of other ranking factors (it’s called causal inference analysis).
Here we see the real clicks in black and the traffic we would have had in blue (that is, the traffic predicted by the mathematical model), then in the following chart the difference between the real traffic and the estimated traffic and finally the delta of increase. In this way, we can be sure that, as analyzed, it has statistical relevance and is related to the introduction of the new content model. ?
Data source: Google Search Console
In summary, WordLift Mappings allows you to:
Build a Custom Knowledge Graph based on your content model
Improve the SEO of your website through structured data
Shape the structure of your content to improve the user experience
Reuse chunks of content through different configurations to respond to different research purposes
Enhance any type of content composed of reusable elements (articles, courses, events, How-Tos etc.)
The implementation of a custom Knowledge Graph through WordLift Mappings has a positive and measurable impact on traffic.
SERP analysis is an essential step in the process of content optimization to outrank the competition on Google. In this blog post I will share a new way to run SERP analysis using machine learning and a simple python program that you can run on Google Colab.
SERP (Search Engine Result Page) analysis is part of keyword research and helps you understand if the query that you identified is relevant for your business goals. More importantly by analyzing how results are organized we can understand how Google is interpreting a specific query.
What is the intention of the usermaking that search?
What search intent Google is associating with that particular query?
The investigative work required to analyze the top results provide an answer to these questions and guide us to improve (or create) the content that best fit the searcher.
While there is an abundance of keyword research tools that provide SERP analysis functionalities, my particular interest lies in understanding the semantic data layer that Google uses to rank results and what can be inferred using natural language understanding from the corpus of results behind a query. This might also shed some light on how Google does fact extraction and verification for its own knowledge graph starting from the content we write on webpages.
Falling down the rabbit hole
It all started when Jason Barnard and I started to chat about E-A-T and what technique marketers could use to “read and visualize” Brand SERPs. Jason is a brilliant mind and has a profound understanding of Google’s algorithms, he has been studying, tracking and analyzing Brand SERPs since 2013. While Brand SERPs are a category on their own the process of interpreting search results remains the same whether you are comparing the personal brands of “Andrea Volpini” and “Jason Barnard” or analyzing the different shades of meaning between “making homemade pizza” and “make pizza at home”.
Hands-on with SERP analysis
In this pytude (simple python program) as Peter Norvig would call it, the plan goes as follow:
we will crawl Google’s top (10-15-20) results and extract the text behind each webpage,
we will look at the terms and the concepts of the corpus of text resulting from the download, parsing, and scraping of web page data (main body text) of all the results together,
we will then compare two queries “Jason Barnard” and “Andrea Volpini” in our example and we will visualize the most frequent terms for each query within the same semantic space,
After that we will focus on “Jason Barnard” in order to understand the terms that make the top 3 results unique from all the other results,
Finally using a sequence-to-sequence model we will summarize all the top results for Jason in a featured snippet like text (this is indeed impressive),
At last we will build a question-answering modelon top of the corpus of text related to “Jason Barnard” to see what facts we can extract from these pages that can extend or validate information in Google’s knowledge graph.
Text mining Google’s SERP
Our text data (Web corpus) is the result of two queries made on Google.com (you can change this parameter in the Notebook) and of the extraction of all the text behind these webpages. Depending on the website we might or might not be able to collect the text. The two queries I worked with are “Jason Barnard” and “Andrea Volpini” but you can query of course whatever you like.
One of the most crucial work, once the Web corpus has been created, in the text mining field is to present data visually. Using natural language processing (NLP) we can explore these SERPs from different angles and levels of detail. Using Scattertext we’re immediately able to see what terms (from the combination of the two queries) differentiate the corpus from a general English corpus. What are, in other words, the most characteristic keywords of the corpus.
The most characteristics terms in the corpus.
And you can see here besides the names (volpini, jasonbarnard, cyberandy) other relevant terms that characterize both Jason and myself. Boowa a blue dog and Kwala a yellow koala will guide us throughout this investigation so let me first introduce them: they are two cartoon characters that Jason and his wife created back in the nineties. They are still prominent as they appear on Jason’s article on a Wikipedia as part of his career as cartoon maker.
Boowa and Kwala
Visualizing term associations in two Brand SERPs
In the scatter plot below we have on the y-axis the category “Jason Barnard” (our first query), and on the x-axis the category for “Andrea Volpini”. On the top right corner of the chart we can see the most frequent terms on both SERPs – the semantic junctions between Jason and myself according to Google.
Not surprisingly there you will find terms like: Google, Knowledge, Twitter and SEO. On the top left side we can spot Boowa and Kwala for Jason and on the bottom right corner AI, WordLift and knowledge graph for myself.
Visualizing the terms related to “Jason Barnard” (y-axis) and “Andrea Volpini” (x-asix). The visualization is interactive and allows us to zoom on a specific term like “seo”. Try it.
Comparing the terms that make the top 3 results unique
When analyzing the SERP our goal is to understand how Google is interpreting the intent of the user and what terms Google considers relevant for that query. To do so, in the experiment, we split the corpus of the results related to Jason between the content that ranks in position 1, 2 and 3 and everything else.
On the top the terms extracted from the top 3 results and below everything else. Open the chart on a separate tab from here.
Summarizing Google’s Search Results
When creating well-optimized content professional SEOs analyze the top results in order to analyze the search intent and to get an overview of the competition. As Gianluca Fiorelli, whom I personally admire a lot, would say; it is vital to look at it directly.
It surprises a lot how many SEOs rarely directly look at the SERPs, but do that only through “the ? “ of a tool. Shame! Look at them & youl’ll: 1) see clearly the search intent detected by Google 2) see how to format your content 3) find On SERPS SEO opportunities pic.twitter.com/Wr4OYAcmiG
Since we now have the web corpus of all the results I decided to let the AI do the hard work in order to “read” all the content related to Jason and to create an easy to read summary. I’ve experimented quite a lot lately with both extractive and abstractive summarization techniques and I found that, when dealing with an heterogeneous multi-genre corpus like the one we get from scraping web results, BART (a sequence-to-sequence text model) does an excellent job in understanding the text and generating abstractive summaries (for English).
Let’s it in action on Jason’s results. Here is where the fun begins. Since I was working with Jason Barnard a.k.a the Brand SERP Guy, Jason was able to update his own Brand SERP as if Google was his own CMS ? and we could immediately see from the summary how these changes where impacting what Google was indexing.
Here below the transition from Jason marketer, musicians and cartoon maker to Jason full-time digital marketer.
Can we reverse-engineer Google’s answer box?
As Jason and I were progressing with the experiment I also decided to see how close a Question Answering System running Google , pre-trained models of BERT, could get to Google’s answer box for the Jason-related question below.
Quite impressively, as the web corpus was indeed, the same that Google uses, I could get exactly the same result.
A fine-tuning task on SQuAD for the corpus of result of “Jason Barnard”
This is interesting as it tells us that we can use question-answering systems to validate if the content that we’re producing responds to the question that we’re targeting.
Lesson we learned
We can produce semantically organized knowledge from raw unstructured content much like a modern search engine would do. By reverse engineering the semantic extraction layer using NER from Google’s top results we can “see” the unique terms that make web documents stand out on a given query.
We can also analyze the evolution over time and space (the same query in a different region can have a different set of results) ofthese terms.
While with keyword research tools we always see a ‘static’ representation of the SERP by running our own analysis pipeline we realize that these results are constantly changing as new content surfaces the index and as Google’s neural mind improves its understanding of the world and of the person making the query.
By comparing different queries we can find aspects in common and uniqueness that can help us inform the content strategy (and the content model behind the strategy).
Are you ready to run your first SERP Analysis using Natural Language Processing?
All of this wouldn’t happen without Jason’s challenge of “visualizing” E-A-T and brand serps and this work is dedicated to him and to the wonderful community of marketers, SEOs, clients and partners that are supporting WordLift. A big thank you also goes to the open-source technologies used in this experiment:
Jason S. Kessler. Scattertext: a Browser-Based Tool for Visualizing how Corpora Differ. ACL System Demonstrations. 2017. Link to preprint: arxiv.org/abs/1703.00565









Recent Comments