Semantic publishing or dynamic semantic publishing, refers to publishing online documents along with the linked metadata that describe them.
Adding machine-readable metadata helps crawlers and software agents to understand the meaning, structure, and context of a piece of information.
What is Semantic Publishing?
It was back in 2001 when Tim Berners-Lee in a publication of Scientific American that later became a milestone for the Web industry first introduced the term Semantic Web.
The Semantic Web will bring structure to the meaningful content of Web pages, creating an environment where software agents roaming from page to page can readily carry out sophisticated tasks for users […..]. The Semantic Web is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better enabling computers and people to work in cooperation.
The limitations of the Web as a collection of documents and links have been well known for quite some time.
Way before the WWW was born – back in 1960 – a visionary called Ted Nelson introduced the idea of a “digital repository scheme for worldwide electronic publishing“. Nelson introduced a machine-language program which would store and display documents, together with the ability to perform edits.
When in the 80s Berners-Lee began structuring the WWW as we know it today, a rivalry emerged: Nelson had a strong and justified reaction when Wired magazine published in 1995 a controversial article titled “The Curse of Xanadu”.
Now – without getting into too many details – one of the differences between WWW and Xanadu, the system that Nelson envisioned, is that information from one document can be embedded into another document (a mechanism known as “transclusion”) with explicit permission given by the author of the document. This mechanism of sharing information in a consistent way between parties was lost with the implementation of hyperlinks and HTML web pages that we use today.
Web pages have been originally designed to display information for humans and had little or no information to help machines process, sift and organize this information. Hyperlinks also have been originally conceived as free pathways from one document to the other without requiring any specific logic and/or approval by the linked party as it was with Xanadu’s transclusions.
The Semantic Web addresses these concerns and extends the World Wide Web by making information machine-readable, specifying provenance and allowing software agents to automatically accomplish complex tasks such as text mining, categorization, and search. The linked metadata introduced by semantic web technologies also helps search engines understand the content being indexed and provide more accurate results to their end-users.
Hyperlinks are an essential feature of the World Wide Web but provide no meaning on why two pages are connected. A machine when analyzing a hyperlink can only see that the first page is promoting the second one and is using a specific keyword to enable the link. There is no way that the machine can grasp why that link was created and by whom. The Web is a large graph of connected pages made of unspecified links.
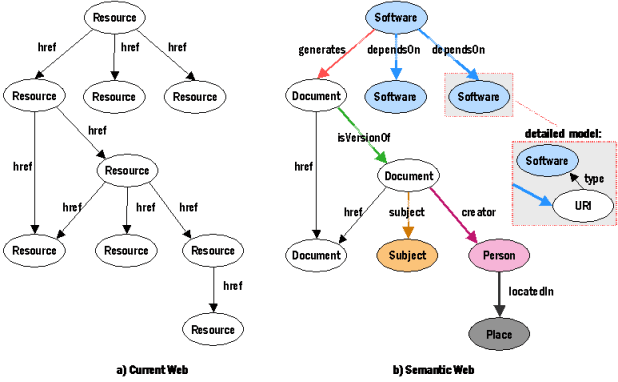
In the Semantic Web each node has a unique identifier and the relationship with the other nodes helps computers understand the meaning and the structure of the content. In semantic web publishing, the nodes are represented by core concepts or entities that are unambiguously connected with shared definitions, accessible to everyone on the Internet.
Wait a second where is this information stored?
Entities are stored publicly on the Web using a set of best practices for publishing and connecting structured data known as linked data. Linked data entitles several techniques to help machine analyze content, index it and fetch answers back to users. In semantic publishing, the metadata describing an article is stored using linked data.
Why large media companies invest in Semantic Publishing?
It has been quite some time since large online publishers have begun advocating semantic publishing. Web publishing is going through a significant transformation and the driving forces of this transformation are:
- Mobile users are on the rise and content is consumed contextually and on-the-go
- The attention span is shrinking. In a recent consumer research study, Microsoft claims that the average human attention span is down to 8 seconds, down from 12 seconds in 2000
- Long formats have become popular online and have negatively impacted advertising metrics. They are more expensive to produce and generate less engagement in terms of page views.
- SEO is a must and machines have become more demanding in terms of the metadata they require, editors, are challenged by the evolving algorithms and content marketing techniques.
- Social Media are driving more referral traffic than search engines. Initiating conversation online and nurturing the audience requires ready-to-use actionable information
- Fake news are undermining the work of journalists. In world where “everyone is a publisher” true journalists strive to remain authoritative voices. Professional journalists often become prey of all kind of manipulation.
In this context semantic publishing represent a concrete solution to tackle these challenges. Here are some of the reasons:
- More compelling and authoritative content can be created with the help of semantic publishing
- Content, published with semantic markup, drives more engagement (have a look at one of our use cases to see how dwell time and organic traffic have been increased) and helps users discover content more quickly
- Search engines promote semantically marked up content in various ways as they can better understand the context of it. Google Rich Snippets are an example. Several studies demonstrated how Rich Snippets boost CTR on SERP pages by 30%
- Linked metadata provides completely a new way to craft a personalized reading experience with meaningful recommendations and a logical linking structure
- The editorial productivity in small to mid-sized editorial teams is increased as entities become a shared knowledge base within the newsdesk
- The structured metadata allows publishers to package content in easy to us API-driven feeds (here is a simple example of a feed containing all the persons we talked about in this blog).
- Semantic publishing enables the most contextually relevant ads that match articles, therefore, increasing CTR on advertising and business value.
- Semantic publishing reduces the amount of manual work required by editors by automating tagging, linking, SEO tasks and categorization.
- As content is sliced and categorized using concepts and topics new interactive ways of interacting with it are presented to the user. Topical pages (such as the one you’re reading now) represent a new interactive glossary and replace traditional tag pages adding widgets to discover new content (see the example below).
How does Semantic Publishing work?
There are three major components in a semantic publishing architecture:
- Text mining. The technology required to extract information from a text written using natural language.
- A graph database. This is the repository of all the semantic information. Typically structured in a graph (triple store) the databases uses linked data technologies and stores information in triples (a data structure made of three components: the subject, which is a URI reference or a blank node. the predicate, which is a URI reference. the object, which is a URI reference, a literal or a blank node).
- A content discovery engine. This provides the data to discovery widgets and search engines to help users find the content they want to read.
WordLift helps you structure content by extracting named entities and concepts and linking them with publicly available Linked Data graphs along with your custom datasets. The extracted data is stored in a triple store and injected as JSON-LD using the schema.org vocabulary for improving the SEO of the content.
WordLift enhances articles and pages by using several NLP tasks including:
- Language Detection
- Named Entity Recognition
- Nouns Recognition
- Entity Linking
- Topic Annotation
- Content Classification
Are You Ready to Give Semantic Publishing a Try? Contact Us and Book a Skype demo