Schemas are ubiquitous in the data landscape. In the past, data exchanges within and outside companies were relatively straightforward, especially with monolithic architectures. However, the rise of distributed architectures has led to an exponential increase in touch points and, consequently, specifications for data exchanges. This repetition of describing the same data in various languages, formats, and types has resulted in data getting lost and falling out of sync, presenting challenges to data quality.
Schemas serve as foundational elements in data management, offering a fundamental structure that dictates how data is organized and presented. Their extensive use is rooted in their ability to furnish a standardized blueprint for representing and structuring information across diverse domains.
A key function of schemas is to establish a structured framework for data by specifying types, relationships, and constraints. This methodical approach enhances data comprehensibility for both human interpretation and machine processing. Additionally, schemas foster interoperability by cultivating a shared understanding of data structures among different systems and platforms, facilitating smooth data exchange and integration.
In the realm of data operations (dataOps), which centers around automating data-related processes, schemas play a pivotal role in defining the structure of data pipelines. This ensures a seamless flow of data through various operational stages. Concurrently, schemas significantly contribute to data integrity by enforcing rules and constraints, thereby preventing inconsistencies and errors.
The impact of schemas extends to data quality, where they play a crucial role in validating and cleansing incoming data by defining data types, constraints, and relationships. This, in turn, enhances the overall quality of the dataset. Moreover, schemas support controlled changes to data structures over time, enabling adaptations to evolving business needs without disrupting existing data.
In the context of data synchronization, schemas are indispensable for ensuring that data shared across distributed databases adheres to a standardized structure. This minimizes the likelihood of inconsistencies and mismatches when data is exchanged between different sources and destinations. Beyond their structural role, schemas also function as a form of metadata, offering valuable information about the structure and semantics of the data. Effective metadata management is essential for comprehending, governing, and maintaining the entire data lifecycle.
Tim Berners-Lee’s And Wordlift’s Visions Changed The Way I See Schemas And SEO Forever
Schemas like schema markup truly permeate every aspect of our world. I find their influence fascinating, not just in their inherent power but also in their ability to bring together individuals from diverse backgrounds, cultures, technical setups, and languages to reach the same insights and conclusions through the interoperability they facilitate.
My deeper engagement with Schema.org began after a more profound exploration during my visit to CERN in 2019, courtesy of my partner. While there, I had the privilege of discussing with individuals working at CERN and even had a glimpse of Tim Berners-Lee’s office. For those unfamiliar, Tim is the mind behind the invention of the World Wide Web (WWW). Even though I had previously encountered schema structures in a comprehensive course on Web-based systems, it was during this visit that I truly grasped the broader vision and the trajectory shaping the future of it.
However, this isn’t a narrative about my visit to CERN. I simply want to emphasize the significance of understanding where to direct your attention and how to approach thinking when it comes to recognizing visionaries in the SEO field. Even though Tim Berners-Lee wasn’t specifically contemplating SEO or had any direct connection to it, he, as a computer scientist, aimed to enhance CERN’s internal documentation handling and, in the process, ended up positively transforming the world.
The Debate In The Women In Tech SEO Community
I feel incredibly fortunate to be a part of the Women in Tech SEO community. Areej AbuAli did an outstanding job of bringing together all the brilliant women in the field here. Recently, we had a discussion about the future and necessity of schema markup overall, presenting two contrasting worldviews:
One perspective suggests that schema markup will diminish over time due to the highly advanced and rapidly improving NLP and NLU technology at Google, which supposedly requires minimal assistance for content understanding.
The opposing view contends that schema markup is here to stay, backed by Google’s active investments in it.
While I passionately advocated for the latter, I must be transparent and admit that I held the former viewpoint a few years ago. During interviews when questioned about trends in the SEO field, I used to align with the first point. Reflecting on it now, I realize how my perspective has evolved. Was I really blind, or was there a bigger picture? Is there a scientific approach or method that can conclusively settle this debate once and for all?
Let’s agree to disagree, that’s my first goal 🙂Before delving in, I’d like to extend my gratitude to those who have significantly influenced my thought process:
A special acknowledgement to Tyler Blankenship (HomeToGo) for sparking the early version of this presentation during our insightful discussion at InHouseSEODay Berlin 2023.
A big shout-out to the SEO community that actively participated in my poll on X (Twitter).
And to you, the consumer of this content, I genuinely hope to meet your high expectations and contribute to your further advancement with my research.
SEO Visionaries Have A Secret Advantage
Let me pose my first question to you, dear reader: Can you articulate the present to predict the future?
Time to embrace some open-minded and analytical thinking.
You see, having vision is crucial. Visionary SEO leaders aren’t merely lucky; they’ve mastered the art of analyzing information, learning from history, identifying patterns and leveraging both approaches to predict and anticipate the future. I’ve pondered whether I can find a way to become one myself, especially if I’m not one already.
The reassuring news is that being visionary is a skill that can be cultivated. Let me show you how.
Indicators As An Educated Approach
My time at the Faculty of Computer Science and Engineering – Skopje has been incredibly enlightening in terms of my scientific endeavors. These experiences have equipped me with a framework to approach any problem: leveraging indicators in my analysis.
Well-formulated indicators are not only straightforward to comprehend but also prove to be valuable when formulating initial hypotheses. Now, as I navigate through the process of addressing the pivotal question of whether SEO schema markup is a lasting trend, I’ve outlined the following indicators to guide my thinking:
The pulse of the SEO community
Schema markup webmaster guidelines
Schema markup investments
Research and reports
Measurable schema markup case studies
Complexity layers
The GenAI challenge
The pulse of the SEO community
I decided to gauge the pulse by exploring the sentiments within the broader SEO community regarding the topic on X. With a small yet dynamic community centered around my interests, such as technical SEO and content engineering, this presented the perfect chance to gather preliminary insights on a larger scale. The question I posed was: is schema still relevant in 2024? Check out the results below.
Approximately 80% of the votes (totaling 102) leaned towards supporting the continued significance of schema markup in 2024. However, when considering the future beyond that, can we adopt a more scientific approach to ascertain whether structured data via schema markup will stand the test of time or merely be a fleeting trend?
Schema markup webmaster guidelines
The poll was decent, but it’s susceptible to biases, and some may contend that it lacks statistical significance on a global scale, given that I collected just over 100 answers. The community of SEO professionals worldwide is much larger, and I couldn’t ensure that the responses exclusively came from SEO professionals.
This led me to opt for a historical examination of the webmaster guidelines offered by the developer relations teams at two of the largest search engines globally: Google and Bing.
Examining the guidance offered by John Muller and Fabrice Cannel, whether through blog posts or official webmaster documentation, leads us to the conclusion that schema markup remains relevant. A notable piece by Rogger Monti on Search Engine Journal, titled “Bing Explains SEO For AI Search” underscores the significance of adding structured data for content understanding.
See for yourself. If that’s not enough, let’s analyze the historical trendline on schema-related updates on Google’s side: there were 11 positive schema markup updates since August 23rd, 2023 or 13 in total.
Deprecated schema types:
August 23, 2023: HowTo is removed
August 23, 2023: FAQ is is removed
New schema types and rich snippets to build your digital passport:
October 16, 2023: Vehicle structured data listing was added.
October 2023: Google emphasizes importance of schema on SCL Zurich 2023.
November 15, 2023: Course info structured data was added
November 27, 2023: documentations for ProfilePage, DiscussionForum were added along with enhanced guidelines for Q&A page (reliance on SD to develop EEAT).
November 29, 2023: an update for organization structured data.
December 4, 2023: Vacation Rental structured data was added.
January 2024: discount rich results on all devices was launched in the U.S.
February 2024: structured data support for product variants is added.
Well, this one is huge: Google just announced increased support for GS1 on the Global Forum 2024! Now, everything falls into place, and the narrative doesn’t end there. For those tracking the schema.org repository managed by Dan Brickley, a Google engineer, it’s evident that the entire Schema.org project is very much active. Schema is here to stay, it’s truly not going anywhere, I thought, but are Google’s or search engines’ investments a reliable indicator to make an informed judgment?
I’ll take on the role of devil’s advocate once more and want to remind you that Google has had its share of failures, including Google Optimize and numerous other projects it heavily invested in. Public relations hype can be deceptive and isn’t always reliable. Unfortunately, schema.org isn’t disclosed in their financial reports, preventing us from gauging how much search engines invest to shape our perspectives. Nevertheless, delving into a more thorough historical analysis can help clarify the picture I’ve just presented to you. Hope you’ll enjoy the ride.
The past, the present and the future: what do they show us?
Let’s start with the mission that Tim Berners-Lee crafted and cultivated at CERN: the findability and interoperability of data. Instead of delving into the intricate details of how he developed the World Wide Web and the entire history leading up to it, let’s focus on the byproducts it generated: Linked Data and the 5-star rating system for data publication on the Web.
Let me clarify this a bit. The essence of the 5-star rating system lies in the idea that we should organize our data in a standardized format and link it using URIs and URLs to provide context on its meaning. The ultimate aim is to offer organized content, or as described in Content Rules, to craft “semantically rich, format-independent, modularized content that can be automatically discovered, reconfigured, and adapted.”
Sounds like a solid plan, right?
Well, only if we had been quicker to adapt our behaviors and more forward-thinking at that time…
It took humanity more than 20 years to reach a consensus on a common standard for organizing website data in a structured web, and I’m referring to the establishment of Schema.org in 2015. To be more specific, it wasn’t humanity at large but rather the recognition of potential and commercial interest by major tech players such as Google, Microsoft, and others that spurred the development and cultivation of this project for the benefit of everyone.
One quote which is at the beginning of the paper particularly stands out:
“Big data makes common schema even more necessary”
As if it wasn’t already incredibly difficult with all these microservices, data storages, and data layers spanning different organizations, now we have to consider the aspect of big data as well.
Now that I’m familiar with the past and the present, can I truly catch a glimpse into the future? What does the future hold for us, enthusiasts of linked data? Will our aspirations be acknowledged at all? I’ll answer this in the upcoming sections.
Global data generated globally and why we’ll deeply drown in it
The authors were confident that big data is rendering common schemas even more crucial. But just how massive is the data, and how rapidly is it growing year after year?
As per Exploding Topics, a platform for trend analysis, a staggering 120 zettabytes are generated annually, with a notable statement noting that “90% of the world’s data was generated in the last two years alone.” That’s an exceptionally large volume of data skyrocketing at a lightning-fast pace! In mathematical terms, that’s exponential growth but it doesn’t even stop there: we need to factor generative AI in too. Oh. My. God. Good luck in estimating that.
Incorporating generative AI and its impact on generating even more data on the web with minimal investment in time and money results in a combinatorial explosion!
The escalating wave of content creation and swift publishing necessitates a modeling approach that aligns with their velocity, effectively captured by the factorial function. The exponential function is no longer sufficient – factorial comes closest to modeling our reality at this scale.
Exponential growth: but we need to factor in the GenAI impact too!
We’re making significant strides in grasping the significance of schema implementation, but one could argue that Google now boasts a BERT-like setup with advancements like MUM, Gemini, and more. It’s truly at the forefront of natural language understanding. This provides a valid point for debate.
I need to delve into a more critical analysis to uncover better supporting evidence: are there statistics that illustrate the growth of schema usage over time and indicate where it is headed?
Let’s continue to the next indicator.
Research and reports
The initial thought that crossed my mind was to delve into the insights provided on The Web Almanac website. Specifically, I focused on the section about Structured Data, and it’s worth noting that the latest report available is from 2022. I’ve included screenshots below for your reference.
The key point to highlight is encapsulated in the following quote:
“Despite numerous advancements in machine learning, especially in the realm of natural language processing, it remains imperative
to present data in a format that is machine-readable.”
Examine the figures. Schema is showing a distinct upward trend, which is promising – I’ve finally come across something more backable. Now I can confirm through data that schema is likely here to say.
The next question for you, dear reader, is how to establish a tangible connection between schema and a measurable business use case?
Enter the “Killer Whale” update. Fortunately, I have a personal connection with Jason Barnard and closely follow his work. I instantly remembered the E-E-A-T Knowledge Graph 2023 update he discussed in Search Engine Land. For those unfamiliar, Jason has created his own database where he monitors thousands of entities, knowledge panels, and SERP behavior, where all of them are super important for Google’s natural language understanding capabilities.
Why is this significant? Well, knowledge panels reflect Google’s explicit comprehension of named entities or the robustness of its data understanding capabilities. That is why Jason’s ultimate objective was to quantify volatility using Kalicube’s Knowledge Graph Sensor(created in 2015).
As Jason puts it, “Google’s SERPs were remarkably volatile on those days, too – for the first time ever.” Check out the dates below.
The Google Knowledge Graph is undergoing significant changes, and all the insights shared in his SEJ article distinctly highlight that Google is methodically evolving its knowledge graph. The focus is on diversifying points of reference, with a particular emphasis on decreasing dependence on Wikidata. Why would someone do that?
When considering structured data, Wikidata is the first association that comes to mind, at least for me. The decision to phase out Wikidata references indicates Google’s confidence in the current state of its knowledge graph. I confidently speculate that Google aims to depend more on its proprietary technology, reducing reliance and establishing a protective barrier around its data. Another driving force behind this initiative is the growing significance of structured formats. Google encourages businesses to integrate more structured, findable information, be it through their Google Business profiles, Merchant Centers, or schema markup. I’ll tweak the original quote and confidently assert that:
“Findabledata, not just data,
is the new oil in the world”
There are numerous reasons for this, leading me to the sixth indicator: complexity layers. This is where it becomes genuinely fascinating. Please bear with me.
The Why behind structured data: complexity layers
Structured data holds significant importance for various reasons. Utilizing structured data with schema markup facilitates the generation, cleansing, unification, and merging of real-world layers – not just data layers – that play a crucial role in mindful; data curation and dataOps within companies.
I call them complexity layers.
I kind of touched on complexity layers when I discussed data growth year over year but let’s take a deeper dive now.
Compute
Tyler, if you happen to come across this article, I’d like to extend my appreciation for your thought-provoking questions and the insightful discussion we had in Berlin. The entire discussion on complexity layers in this section is inspired by our conversation and originates from the notes I took during that session.
The capacity of compute is directly tied to the available financial resources and the expertise in optimizing data collection strategies and Extract-Transform-Load (ETL) processes. Google, being financially strong, can invest in substantial compute power. Furthermore, their highly skilled engineers possess the expertise to mathematically and algorithmically optimize workflows for processing larger volumes of data efficiently.
However, even for Google, compute resources are not limitless, especially considering the rapid growth of data they need to contend with (as discussed in the “Global Data generated globally and why we’ll deeply drown in it” section). The only sustainable approach for them to handle critical data at scale is to establish and enforce unified data standardization and data publishing wherever feasible.
Sound familiar? Well, that’s precisely what structured data through schema markup brings to the table.
Content generated by AI, if not refined through processes like rewriting or fact-checking, has the potential to significantly degrade the quality of search engines such as Google and Bing. The importance of quality assurance processes has never been more important than it is now. Hence, navigating compute resource management becomes especially challenging in the age of generative AI. The key to mitigating data complexity lies in leveraging structured data, such as schema markup. Therefore, I’ll modify Zdenko Vrandecic’s original quote ““In a world of infinite content, knowledge becomes valuable” to the following:
“In a world of infinite [AI-generated] content,
[reliable] knowledge becomes valuable”
Even the impressive Amsive team, led by the fantastic Lily Ray, wrote about this, describing the handling of unstructured data as a crucial aspect of AI readiness: “this lack of structure puts a burden on large language models (LLMs) developers to provide the missing structure, and to help their tools and systems continue to grow. As LLMs and AI-powered tools seek real-time information, it’s likely they will rely on signals like search engines for determining source trustworthiness, accuracy, and reliability”. This brings me to several new indicators that I will delve into, but for now, let’s focus on the legal aspect.
Legal
Organizing unstructured data, especially when dealing with Personally Identifiable Information (PII), demands compliance with data protection laws like GDPR and local regulations. Essential considerations encompass securing consent, implementing anonymization or pseudonymization, ensuring data security, practicing data minimization, upholding transparency, and seeking legal guidance. Adhering to these measures is crucial to steer clear of legal repercussions, including fines and damage to one’s reputation. While fines can be paid, repairing reputational damage is a tougher challenge.
Following the rules of data protection laws is crucial, even for big tech players who, by law, must secure explicit consent before delving into individuals’ data. They also need to explore methods like anonymization and pseudonymization to mitigate risks and fortify their data defenses through encryption and access controls.
This often leads major tech companies to actively collaborate with legal experts or data protection officers, ensuring their data practices stay in sync with the ever-changing legal landscape. Can you guess how structured data through schema markup helps address these challenges?
User experience (UX)
One of the trickiest scenarios for employing structured data. You see, user experience doesn’t just hinge on the computer cost but is also influenced by non-monetary factors like time, cognitive effort, and interactivity. Navigating the web demands cognitive investments and instruments, such as time for exploration and effort to comprehend the data and user interfaces presented.
These intricacies are well-explored in the Google Research’s paper titled “Delphic Costs and Benefits in Web Search: A Utilitarian and Historical Analysis.”
To cite the authors, “we call these costs and benefits Delphic, in contrast to explicitly financial costs and benefits…Our main thesis is that users’ satisfaction with a search engine mostly depends on their experience of Delphic cost and benefits, in other words on their utility. The consumer utility is correlated with classic measures of search engine quality, such as ranking, precision, recall, etc., but is not completely determined by them…”.
The authors identify many intermingled costs to search:
Access costs: for a suitable device and internet bandwidth
Cognitive costs: to formulate and reformulate the query, parse the search result page, choose relevant results, etc.
Interactivity costs: to type, scroll, view, click, listen, and so on
Waiting costs: for results and processing them, time costs to task completion.
How about minimizing the costs of accessing information online by standardizing data formats, facilitating swift and scalable information retrieval through the use of schema markup?
Time / Speed
This leads me to the next indicator, time to information (TTI).
Time to information typically refers to the duration or elapsed time it takes to retrieve, access, or obtain the desired information. It is a metric used to measure the efficiency and speed of accessing relevant data or content, particularly in the context of information retrieval systems, search engines, or data processing. The goal is often to minimize the time it takes for users or systems to obtain the information they are seeking, contributing to a more efficient and satisfactory user experience. While not easily quantifiable, this aspect holds immense significance, especially in domains where the timely acquisition of critical information within a short interval is make or break.
Consider scenarios like limited-time offers on e-commerce and coupon platforms or real-time updates on protests, natural disasters, sports results, or any time-sensitive information. Even with top-tier cloud and data infrastructure, such as what Google boasts, the challenge lies in ensuring the prompt retrieval of the most up-to-date data. APIs are a potential solution, but they entail complex collaborations and partnerships between companies. Another avenue, which doesn’t involve legal and financial intricacies, is exerting pressure on website owners to structure and publish their data in a standardized manner.
Again, we need structured data like schema markup.
Generative AI
Do you see why I’m labeling them as complexity layers? Well, if they weren’t intricate enough already, you have to consider the added layer of complexity introduced by generative AI. As I’m crafting this section, I’m recognizing that it’s sufficiently intricate to warrant a separate discussion. I trust that you, dear reader, will reach the same conclusion and stay with me until I lay out all the facts before diving into the narrative for this section. If you want to jump directly to it, search for The Generative AI challenge section that will come later in this post.
Geography
Oh, this one’s a tricky one, and I name it the geo-alignment problem.
Dealing with complexities like UX, compute, legal, and the rest is complex enough, but now we’ve got to grapple with geographical considerations too.
Let me illustrate with a simple example using McDonald’s: no matter where you are in the world, the logo remains consistent and recognizable, and the core offerings are more or less the same (with some minor differences between regions). It serves as a universal symbol for affordable and quickly prepared fast food. Whether you’re in Italy, the U.S., or Thailand, you always know what McDonald’s represents.
The challenge here is that McDonald’s is just one business, one entity. We have billions of entities that we need to perceive in a consistent manner, not just in how we visually perceive them but also in how we consume them. This ensures that individuals from different corners of the globe can share a consistent experience, a mutual understanding of entities and actions when conducting online searches. Now, throw in the language barrier, and it becomes clear – schema markup is essential to standardize and streamline this process.
Fact-checking
Hmm, I believe I’ll include this in the Generative AI challenge section as well. Please bear with me 🙂
The model describing complexity layers is complex too
These layers aren’t isolated from each other, nor are they neatly stacked in an intuitive manner. If I were to visualize it for you, you might expect something like the following image: you tackle compute, then integrate legal, solve that too, and move on to UX, and so forth. Makes sense, right?
Well, not exactly. These layers are intertwined, tangled, and follow an unpredictable trajectory. They form a part of a complex network system, making it extremely challenging to anticipate obstacles. Something more like this:
Now, remember the combinatorial explosion? Good luck in dealing with that on top of complexity layers without using structured schema markup data in search engines. Like Perplexity.ai co-founder and CTO Denis Yarats says:
In terms of complexity, it’s probably even beyond flying to the moon”
The Generative AI Challenge
I’ve written several blog posts about generative AI, large language models (LLMs) for SEO and Google Search on this blog. However, until now, I didn’t have concrete numbers to illustrate the amount of time it takes to obtain information when prompting them.
Retrieving information is inherently challenging by design
I came across an analysis by Zdenko Danny Vrancedic that highlights the time costs associated with getting an answer to the same question from ChatGPT, Google, and Wikidata: “Who is the Lord Mayor of New York?”
In the initial comparison, as Denny suggests, ChatGPT runs on top-tier hardware that’s available for purchase. In the second scenario, Google utilizes the most expensive hardware that isn’t accessible to the public. Meanwhile, in the third case, Wikidata operates on a single, average server. It raises the question of how someone running a single server can deliver the answer more quickly than both Google and OpenAI? How is this even remotely possible?
LLMs face this issue because they lack real-time information and lack a solid grounding in knowledge graphs, hindering their ability to swiftly access such data. What’s more concerning is the likelihood of them generating inaccurate responses. The key statement for LLMs here is that they need to be retrained more often to provide up-to-date and correct information unless they use RAG and GraphRAG more specifically.
On the other hand, Google encounters this challenge due to its reliance on information retrieval processes tied to page ranking. In contrast, Wikidata doesn’t grapple with these issues. It efficiently organizes data in a graph-like database, storing facts and retrieving them promptly as needed.
In conclusion, when executed correctly, generative AI proves to be incredibly useful and intriguing. However, the task of swiftly obtaining accurate and current information remains a challenge without the use of structured data like schema markup. And the challenges don’t end there.
How text-to-video models can contaminate the online data space
Enter SORA, OpenAI’s latest text-to-video model. While the democratization of video production is undoubtedly positive, consider the implications of SORA for misinformation in unverified and non-professionally edited content. It has the potential to evolve into a new form of negative SEO. I delve deeper into this subject in my earlier article, “The Future Of Video SEO is Schema Markup. Here’s Why.“
Now, let’s discuss future model training. My essential question for you, dear reader, is: what labeling strategies can you use to effectively differentiate synthetic or AI-generated data, thereby avoiding its unintentional incorporation in upcoming LLM model training?
Researchers from Stanford, MIT, and the Center for Research and Teaching in Economics in Mexico endeavored to address this issue in their research work “What label should be applied to content produced by generative AI?”. While they successfully identified two labels that are widely comprehensible to the public across five countries, it remains to be seen which labeling scheme ensures consistent interpretation of the label worldwide. The complete excerpt is provided below:
“…we found that AI generated, Generated with an AI tool, and AI Manipulated are the terms that participants most consistently associated with content that was generated using AI. However, if the goal is to identify content that is misleading (e.g., our second research question), these terms perform quite poorly. Instead, Deepfake and Manipulated are the terms most consistently associated with content that is potentially misleading. The differences between AI Manipulated and Manipulated are quite striking: simply adding the “AI” qualifier dramatically changed which pieces of content participants understood the term as applying it….
This demonstrates our participants’ sensitivity to – and in general correct understanding of – the phrase “AI.” In answer to our forth research question, it is important from a generalizability perspective, as well as a practical perspective, that our findings appeared to be fairly consistent across our samples recruited from the United States,Mexico, Brazil, India, and China. Given the global nature of technology companies (and the global impact of generative AI), it is imperative that any labeling scheme ensure that the label is interpreted in a consistent manner around the world.”
And it does not even stop there! The world recently learned about EMO: a groundbreaking AI model by Alibaba that creates expressive portrait videos from just an image and audio. Like Dogan Ural reportedly shares, “..EMO captures subtle facial expressions & head movements, creating lifelike talking & singing videos…Unlike traditional methods, EMO uses a direct audio-to-video approach, ditching 3D models & landmarks. This means smoother transitions & more natural expressions…”. The full info can be found in his thread on X, while more technical details are discussed in Alibaba’s research paper.
Google has even begun advising webmasters globally to include more metadata in photos. I anticipate that videos will follow, especially in light of the recent announcement of SORA. Clearly, schema markup emerges as the solution to tackle the challenges across all these use cases.
Measurable Schema Markup Case Studies
We’re grateful for everyone, either SEOs or entrepreneurs like Inlinks, the Schema.app, Schemantra and others, who push the boundaries of what’s possible and verifiable in the field of SEO through schema markup, fact-checking and advanced content engineering.
We especially take great pride in the WordLift team, which consistently implements technical marketing strategies using schema markups and knowledge graphs for clients’ websites, making a measurable impact in the process. We continually innovate and strive to make the process of knowledge sharing more accessible to the community. One such initiative is our SEO Case Studies corner on the WordLift blog, providing you with the opportunity to get a sneak peek into our thinking, tools, and clients’ results.
The conclusion? Schema markup is here to stay, big time.
Final Words
It’s been quite a journey, and I appreciate you being with us. I sincerely hope it was worthwhile, and you gained some new insights today. Conducting this study was no easy task, but with the support of an innovative, research-backed team, anything is possible! 🙂
Structured data with schema markup is firmly entrenched and all signs point definitively in that direction. I trust this article will influence your perspective and motivate you to proactively prepare for the future.
Ready to elevate your SEO strategy with the power of schema markup and ensure your data quality is top-notch? Let’s make your content future-proof together. Talk to our team today and discover how to transform your digital presence.
Content Operations and Content Marketing of the Future
When I first delved into technical SEO, I decided to take the Web of Data course at the Faculty of Computer Science and Engineering in Skopje. Back then, I never could have envisioned myself becoming a part of the content marketing and content engineering landscape. As time went on, it became evident that content marketing and SEO held significant importance and became part of the computer science world, too. Even though we must differentiate between semantic SEO and entity SEO, both play crucial roles in today’s digital landscape.
Numerous articles address the subject of entity SEO and entity-based SEO. However, many of them overlook a fundamental aspect. They typically recommend the following practices:
Repeatedly using the same keywords.
Incorporating related phrases and synonyms related to the topic with significant entity salience.
Covering interconnected topics, among others.
Yet, a critical aspect often remains unexplored: what do we do with these entities once we identify them in the text, and what follows in the process? How do we disambiguate them? How can we link them to existing definitions on the web and connect them to the vast knowledge bases available, ensuring clarity in our content? The synergy between technology and content has grown increasingly pronounced in recent years, particularly with the advent of new generative AI experiences. We must carefully consider how we structure our content operations and assemble editorial teams. How do we train people to have a holistic, semantic, yet entity-oriented approach to SEO that is human-first?
We must establish strategies, procedures, and skill enhancement programs to empower individuals to seamlessly bridge the backend of search, leveraging entity linking and knowledge disambiguation, with the front end. This connection should be showcased through knowledge panels and a SEO content strategy that prioritizes a human-centered approach. It might sound like a standard narrative, but I’ve had the experience of working at agencies twice and in-house twice. With over four years of consulting in technical SEO engineering, you’ll face challenges similar to what we encountered, especially if you don’t have a dependable digital partner in the mix.
The Brand Aspect of Your Content
Let’s be clear: if you communicate robotically, you won’t meet people’s expectations or provide the necessary information. Your brand will appear unattractive. That’s why achieving the right balance is crucial. You must learn to speak like a human but in a way that is also understandable to a machine.
Here’s an example to illustrate this point. I have a friend, an SEO expert named Sara Moccand Sayegh, whose aunt is a journalist. Sara says, “When my aunt speaks, I swear to God I only grasp about half of what she’s saying. She explains concepts in overly complex terms that most people can’t follow.” Just like Sara’s aunt, many businesses tend to communicate in a convoluted manner. This leaves me wondering: How can a machine understand your brand story if I, as a human, can’t comprehend what your business is trying to convey? If I’m having trouble grasping it, I seriously question whether a machine could understand it. The crux lies in striking the right balance, ensuring satisfaction on all fronts. The key is mixing your brand with the semantics and the machine logic, all of these three simultaneously.
Understanding Information Extraction
Search engines have become part of our daily lives. We use Google, Bing, Yandex, Baidu, DuckDuckGo, etc. as the main gateway to find information on the Web. We use Facebook or LinkedIn to search for people, associations, and events. We rely on Amazon or eBay for product information and comparisons, while when it comes to music we like to play stuff on YouTube or Spotify. We are decreasingly reliant on apps’ features to find connections, dispatches, notes, timetable entries, etc. We’ve grown habituated to anticipating a search box nearly near the top of the screen. We also increased our expectations to get fast responses back while we search for things.
This is how we and machines developed the use to connect information needs with information concepts and precisely how the fields of information retrieval and information emerged. Search queries are expressions of our information needs while the ranked lists of information objects are the answers provided back to the searcher.
In the past, while search engines were in the early development phase, it was easy to play with keywords and links and use shady techniques to easily rank on search engines. Now, with the development of advanced technologies and algorithms like Multitask Unified Model (MUM) and Locked Image Tuning (LiT)we need to embrace more intelligent solutions and carefully crafted content to answer user queries in the best possible way and provide a satisfactory user experience.
When dealing with natural language queries, we need to distinguish between named entities and concepts.
Named entities are real-world objects and they can include:
persons like Martin Splitt, John Mueller, Sundar Pichai;
locations like Mountain View, Silicon Valey;
organizations like Google, Pinterest;
products like Google Assistant, and Google Cloud;
events like Search UnConference, Knowledge Graph Conference, etc.
Concepts are the opposite of named entities and they represent abstract objects. Some examples include:
mathematical and philosophical concepts like distance, axiom, quantity;
physical concepts or natural phenomena like gravity, force, and wind;
psychological concepts like emotion, thought, and identity;
Social concepts like authority, human rights, and peace.
Named Entity Linking (NEL) And SEO – Smart Search Performance Optimization
In many information extraction applications, entity linking (EL) has emerged as a crucial task in understanding named entities through their linked descriptions obtained from a knowledge base like YAGO, Wikidata, DBPedia, and similar. This process is better to know as semantic mapping or semantic linking in the computer science world:
The first step of the entity linking process isentity extraction where we need to obtain the list of named entities in the text. A named entity compared to a casual entity is an entity that is already defined in a knowledge base or an NLP model;
The second step is candidate entity ranking where after analyzing the user query we obtain several entity candidates in a ranked order. E.g. depending on the context, the entity [apple] can refer to the fruit or Steve Jobs’s company;
Entity interpretation is the final step where we decide on the best candidate for a given query input from the user and use this candidate to retrieve more information from a knowledge base back.
Entity linking can boost your SEO performance by improving:
Your mobile results: entities help improve mobile capabilities and mobile-first indexing which became dominant in search and it’s growing every year.
Natural language and image understanding for rich snippets: things like photos, customer ratings, and product reviews belong in this group.
Translation optimization: synonyms, homonyms, context clues and query facets, and entity disambiguation help in translation improvements.
Increased traffic and conversions: entity linking and entity disambiguation help search algorithms understand your content better and distribute it to more targeted users so that you’ll have more visits back and increased chances to convert them into customers.
How Applied Entity Linking Can Help Online Businesses In Marketing Content Operations?
In the realm of marketing content operations, applied entity linking offers a myriad of advantages:
1. Enhanced Content Relevance: By seamlessly connecting entities in your marketing content to pertinent information in a knowledge base, you ensure content accuracy and currency. This, in turn, delivers valuable and pertinent information to your audience, fostering heightened engagement and trust.
2. Personalization and Targeting: Entity linking empowers you to grasp the context of your content more comprehensively. Armed with this knowledge, you can segment your audience with finesse, thereby delivering tailored content to distinct customer groups, augmenting the likelihood of conversions and customer satisfaction.
3. SEO Optimization: Search engines prioritize semantically rich and contextually relevant content. By employing entity linking to link relevant entities to their corresponding knowledge base entries, you can optimize content for search engines, bolstering search engine rankings, and amplifying organic traffic to your website.
4. Enhanced Content Recommendations: The act of linking entities in your content grants you valuable insights into the relationships between various topics and concepts. This knowledge is instrumental in providing users with more accurate and relevant content recommendations, thereby heightening engagement and prolonging their stay on your website.
5. Streamlined Content Curation: For online businesses grappling with copious amounts of content, entity linking comes to the rescue, streamlining content curation processes. Understanding the entities mentioned in different pieces of content enables more efficient organization and categorization, simplifying the user’s quest to find what they seek.
6. Real-time Updates: With each update to your knowledge base, entity linking ensures that your marketing content automatically reflects the latest information. This serves to maintain content accuracy and reduces the time spent on manual content updates.
7. Competitive Analysis: Entity linking can be harnessed for competitive analysis as well. By scrutinizing the entity mentions in your competitors’ content, you gain invaluable insights into their strategies, focus areas, and market positioning.
8. Sentiment Analysis and Brand Monitoring: Understanding the entities mentioned in the content, customer reviews, or social media posts facilitate sentiment analysis and brand monitoring. This insight enables you to gauge how customers perceive your brand or products, empowering you to take appropriate actions based on feedback.
9. Improved customer service: Entity linking can also be used to improve customer service. For example, if a customer contacts your company with a question about a product, you can use entity linking to quickly find the relevant information in your knowledge base. This can help you provide more accurate and helpful answers to customer questions.
10. Reduced costs: Entity linking can help you reduce costs in a number of ways. For example, it can help you save time by automating the process of linking entities to knowledge bases. It can also help you save money by reducing the need for manual research.
Overall, entity linking is a potent tool capable of enhancing various marketing content operations. If you seek ways to boost your SEO, craft more informative and captivating content, personalize content for individual users, boost brand awareness, elevate customer service, or trim costs, then incorporating entity linking into your strategy should be a thoughtful consideration.
Ready to turbocharge your SEO efforts and see your organic search performance soar?
The Key for Successful Content Teams and Unified Marketing Communication
We frequently engage in in-depth semantic and content SEO conversations with Sara Moccand Sayegh and Jason Barnard at Kalikube. I’m consistently impressed by the clarity of their insights. My interactions with them have been incredibly enlightening, offering me valuable lessons in content marketing. Through our friendship, I’ve honed my ability to pose the right questions, enhancing my writing clarity, my guidance in developing the next generation of superstar content strategists, and my overall refinement of the art of crafting content.
We unanimously concur that employing entity linking and context is essential for ensuring your message is conveyed clearly on the page. This approach serves to reaffirm and reinforce the content, enabling the machine to grasp it accurately and subsequently disseminate it effectively. We said it multiple times already, but I’ll repeat it: we need to design for clarity, and we do this to avoid uncertainty in our brand communication.
Why Designing For Content Clarity Matters
I’m sure you’ve had the experience of searching for a brand or product on Google and being impressed by the wealth of information on the search engine results page (SERP). You’ve also harbored a desire to have a similar presence for your company. So, how can we secure these coveted knowledge panels and information-rich pages for brands? It all boils down to entity linking, which significantly aids understanding and disambiguating content. It’s as straightforward as that. No tricks, no secrets behind them. Intelligent content disambiguation is what does the magic.
Discover how to set up WordLift to trigger a knowledge panel, watch this video.
How Does Entity Linking Help With Entity-oriented SEO and E-E-A-T?
I appreciate the visionary approach that WordLift and Kalikube embody because we need creative thinkers in the content industry, especially during this AI-first era. It’s imperative to prepare for the age of search-generative experiences, consolidate your content strategies, bolster your content understanding, and craft your content comprehensively.
Entity linking is a pivotal element in SEO, playing a substantial role in bolstering expertise, experience, authority, and trustworthiness, often abbreviated as E-E-A-T. These attributes are vital for achieving high rankings in search engines, especially when dealing with YMYL (Your Money or Your Life) content. Here’s how entity linking contributes to E-E-A-T:
1. Expertise:
Elevated Content Quality: Entity linking enriches content by weaving together pertinent entities and concepts, demonstrating a profound grasp of the subject matter.
Authoritative Endorsement: Effective entity linking can underscore that the content is either authored by experts or substantiated by reputable sources, reinforcing its credibility.
2. Authority:
Citations and References: By incorporating entity links, a content piece can establish its authority by referencing trustworthy sources, experts, or citations within the text, thus enhancing the trustworthiness of the presented information.
Verification Through Corroboration: Linking entities to authoritative external sources allows for cross-verification, further solidifying the reliability of the content.
3. Experience:
User-Centric Design: Thoughtful entity linking ensures that content is structured and presented in a user-friendly manner, ultimately enhancing the overall user experience.
Enhanced Relevance: Entity linking forges connections between related topics and concepts, affording users a comprehensive and informative experience.
4. Trustworthiness:
Credible Attribution: Entity linking attributes information to reputable sources or experts, thus augmenting trust in the content.
Transparency and Clarity: By implementing proper entity linking, content transparency is bolstered as the sources of information are made explicit, further enhancing trustworthiness.
In summary, entity linking in SEO establishes expertise by crafting informative and authoritative content, contributes to authority by leveraging citations and cross-verification, elevates user experience and content relevance, and reinforces trustworthiness by attributing information and enhancing transparency. These elements are paramount when building E-E-A-T and improving search engine rankings, particularly for content centered around critical subjects like health, finance, and more.
Entity-Oriented SEO Is The Future Of The Search
Entity-oriented search and optimization give context to your website. That is why it’s important to work with entities because they help to connect the world’s information together and therefore get relevant results back when searching.
One effective way to do so is to use a specific type of schema markupthat will contain all the entities in the ABOUT and MENTIONS schema attributes. Another, more advanced way is to create a knowledge graph out of your content and publish it as linked open data on the Linked Open Cloud.
This is exactly what we do with WordLift. We make a shift from the typical link-building mindset and keyword-oriented search to entity-oriented search and a more advanced link-building approach that employs entity linking between the entities and their respective descriptions in popular knowledge bases. We are also a proud member of the DBpedia Association and actively contribute to the growth of Wikidata. Wordlift is publishing high-quality web-scale knowledge by following Tim Berners Lee’s 5-star principles from CMS and the e-commerce platform. This means also building links with other public graphs.
One thing is clear: user needs are constantly evolving and it is becoming harder to keep up. Do stuff that matters and make use of linked open data to stay relevant.
Digital natives experienced the birth and the death of regular content documents.
If you are like me, you bought your first computer in the 90s and performed your first searches in a text-based browser. Back then, it was not easy to be visionary, because no one knew what direction the web would take, even though we were always excited by the idea of connecting people, knowledge and opportunities as efficiently as possible. At least, that was supposed to be our manifesto.
Documents Are Getting Old…or Is It The Approach Itself?
But something does not seem right. The way we used (and still do!) to interact with SEO content documents (articles, blog posts, research papers, whitepapers, webpages, whatever you call them) was:
Make a research about what needs to be written;
Write the article (or document existing work);
Publish it and/or share it through your content distribution channels;
Set and forget approach: once you’re done, the article stays in the back.
Or re-optimize when (and IF) the time is right, if the resources and the demand allow you to do so as well.
Documents Are Not Fundamentally Efficient
It turns out that SEO documents are anachronistic for most of their life: Once they have satisfied transient user needs, they are either deleted from the system entirely or content teams forget about them because they do not benefit the user. They are deemed obsolete, which results in them not reaching their full potential. And believe me, their potential is enormous if only they were properly semantically tagged and modularized, as they should have been from the start.
If we could just change that logic and start seeing them as islands of knowledge, we could take advantage of more than 3 sites: Voice (Chatbots), Automation (Content Operations) and Knowledge Exploration across the web (Linked Data). This has not been possible until now:
Behavior changes were happening very slowly;
We didn’t have the right, democratized technology in place;
We were in the early stage of fostering knowledge developers positions on the job market.
Documents As Learning Tools
Given the multiple touch points and interactions with content, we need to shift to this new way of thinking about SEO documents to discover the ultimate truths about the world around us beyond a tiny fraction of what’s out there. That’s the power of functional, effective content documents: exploring new worlds of knowledge that are yet to be discovered – just like new lands in ancient times.
A document is a magnificent structure that we can only imperfectly understand because we as humans are limited in our ability to reuse and analyze it in a variety of ways, as machines can. Content documents are a tool to express opinions, but also an exploration that allows us to discover new facts about the world around us. They are tools that help us satisfy our desire for more knowledge.
To go beyond what is known, we need to think critically about our current SEO document content operations, systems, and overall strategy for developing SEO content documents over time. Imagine a world where we can work more cohesively with everyone and help others solve their problems through the intelligent use of SEO document content. It’s no longer about dealing with Big Data: from now on, smart data counts through smart content engineering.
Documents As A Audience Development Tool, Sales Enablement And Science Impact Without Boundaries
Interconnected worlds of data are not primarily limited by language comprehension but rather lack of structure. They are limited by not being organized in your content management systems (CMSs) according to WWW standards which limits their usability and discovery potential over time.
So imagine you are an entrepreneur with a limited budget selling your services online via content marketing, or a researcher looking to find a way to cure disease. Even though they are two different professions, both face the same challenge in practice: they both lack comprehensive sales channels to promote their services, get funding, or uncover new facts. The process of document creation and SEO document dissemination is very manual:
You would go to a given search engine or social media.
You use some marketing techniques (ads, SEO, search operators) to promote your work or target platforms for prospect opportunities and/or search for related papers.
You search for foundations and NGOs that can fund your work.
Very, very manual. It’s not just about automation, it’s about a better approach to how we share knowledge and promote things so that each document is a valuable node in the world of the open knowledge graph. This is a critical factor in finding cures for diseases and supporting online document distribution channels. Therefore.
Next-Gen SEO Documents Are FAIR
The concept of FAIR data is not new. FAIR stands for findability, accessibility, interoperability, and reusability. These principles enable machine usability: “the capacity of computational systems to work with data with no or minimal human intervention.”
Even though this concept has been around for some time and was first introduced in the world of research, we can apply the same logic to any SEO content document that exists. Watch the video below to learn more about it👇
In this way, the value of SEO content documents will never go away, because the way they are created and maintained is evergreen and strategically different than before. They are:
True to their original intent, so their purpose is clear and to the point.
Modular, so that can be reorganized and redistributed in different and multiple ways.
Accessible, no matter the spoken language that it is used.
Measurable and testable, so it’s easy to restructure them as needed.
Trackable and self-describing: you can query and analyze them in the Linked-Open-Data world.
How To Get Perfect SEO Content Documents
If you want to apply these principles to your SEO content documents, you can start with the following:
Our SEO Add-On for Google Sheets™ – by using it you can look at the SERP by analyzing unique entities that characterize each search query (and intent).
Bring this same layer of metadata (entities) inside your own knowledge graph that can be created by using cutting-edge techniques that we employ here at WordLift.
Integrate the entities in your publishing workflow by adding a unique identifier to each document, to each author and to each relevant content piece (example: in our Knowledge Graph a FAQ has its own ID).
There is nothing more powerful than utilizing what you have on your side in the first place. Do you want to learn how you can bring your business to the next level? Book a demo.
The topic of schema markup is not new. We pioneered these concepts in the SEO industry even before they became popular buzzwords and known tactics that actually bring value to websites’ SEO performance. We have been using structured datain the past 20 years to describe data and make it more comprehensible across different datasets and systems, so that both humans and machines can process it properly and actually make something useful out of it.
Along the way, we made sure that our readers understood the use of entities and entity disambiguation, since both of these concepts form the basis of our core products and we are definitely fond of the idea to be the visionaries in the industry and lead in the era of entity oriented search. We cared about entity identifiers, entity relationships and entity attributes and it seems that as the time passes, all of these ideas, slowly over time, will become more and more adopted among SEOs until they become mainstream.
From a scientific point of view, the core problem when dealing with entities in the past 10 years was solving for entity ranking for various tasks, especially in the process of entity linking. You would have a search query that is entity rich, you would employ a retrieval method to obtain entities in the process and then perform entity ranking to form the final search results page no matter whether we speak about a platform based search like an e-commerce shop or news website or a big software like Google’s.
In the last decade, search engine optimization managed to progress to semantic search, linked data and question answering over linked data. This eventually led to ontology engineering, taxonomy optimization and knowledge engineering even though there are not many online resources to prove that this is the case. We know from practice that those companies who seriously get SEO, absolutely invest in these approaches (actually, investing more than just 6 figures on a monthly level).
Quintillion Bytes Of Data – Is Data Quantity Enough To Understand Us?
Roughly 2.5 quintillion bytes of data is created every day. When people speak about it, some of them believe that the sheer volume of available data means we have all the resources to provide an answer to a question without delay. If you can’t, they declare, the solution is to get more data.
The problem with more data, however, is that it does not necessarily mean that the search engines responsible for providing those answers can process them. If the data is not provided in a structured way, it results in a lot of computational effort and cost to understand the context behind certain user queries. What looks like a relatively simple process is actually a solution that is far from trivial and requires some scaffolding and structuring to function optimally.
The (Future) Savior: Knowledge-First Approach
Knowledge-first approach is more user-centric, relationship-oriented and requires more context when solving problems. We ask ourselves the following questions:
Who’s the end user who will consume the data?
How is this data related to our systems and our people who work on them?
Why do we need to take care of data consumption and data activation in order to be more productive?
It is clear that in order to form a successful SEO strategy, your teams need to be versatile both in the data world but have the business acumen as well. That is why we predict that the next 10 years will include more collaboration between the data and the business teams and these hybrid positions are already in place in some of the bigger companies worldwide.
And not just that. Knowledge graph analysis and knowledge graph scraping will become the foundation on creating intelligent long-tail SEO strategies through finding similar entities in the knowledge graphs themselves.
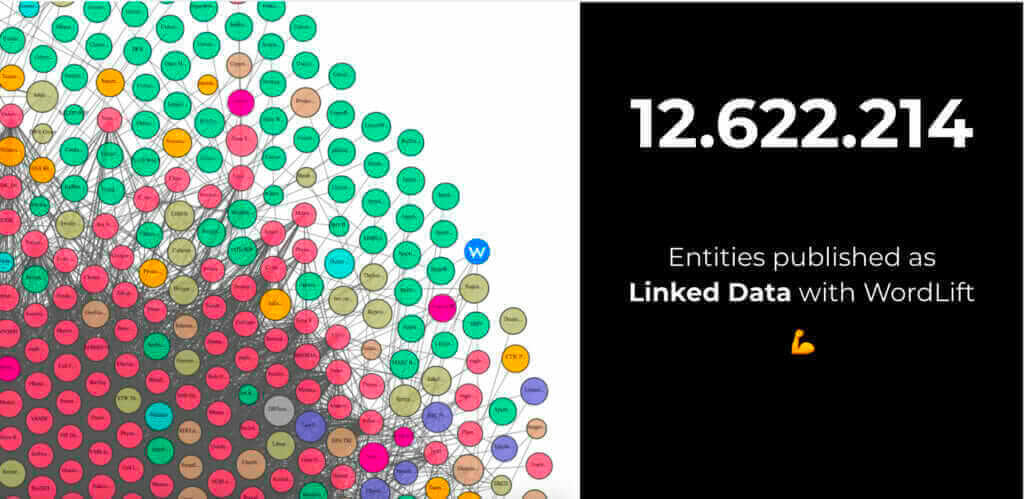
We are proud that we managed to publish more than 12.5 million entities to the Linked Open Data Cloud through our products and are still continuing with our work, making the Internet better, one day at a time.
There is nothing more powerful than utilizing what you have on your side in the first place. Do you want to learn how you can bring your business to the next level? Book a demo.
What The Future Holds For Entity Search?
The core focus in the past 10 years in entity search was focusing on retrieval models and more specifically on entity representations. Richer query annotations were taken as they are and a bit for granted. In the future, we definitely need to focus more on understanding user interactions, information needs, data sources and novel retrieval methods. Those who want to advance, will exploit the power of knowledge bases who enable the modern features of entity search.
That is why the key questions here are:
How to enable humans to maintain and expand knowledge bases at scale?
How to improve the entity annotation process so that we can increase the process of entity retrieval?
How to provide direct entity summaries to properly answer demanding user needs?
This leads us towards a zero-query search world, where search engines will need to be proactive in order to solve for reactive search.
And not just that: we definitely expect to see mashing up personal, enterprise and public data, enabling multiple views of the same data and gaining the ability to actually edit the data that we see.
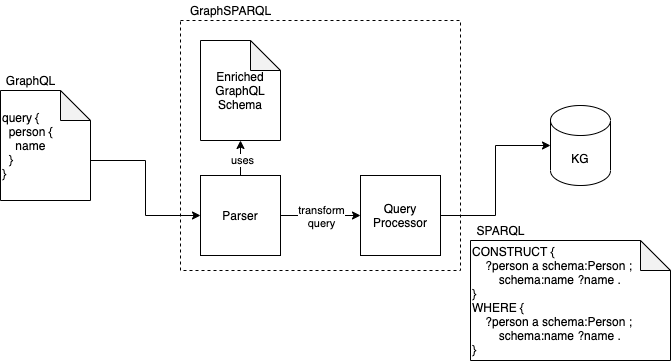
Entity search in future will be dependent on the idea of being able to “query” the Internet through SPARQL queries which will use HTML document URLs as Data Source Names. Cross-platform data manipulation will also become a thing. In addition, content hubs and content hub SEO of the future that will rely on graph embeddings and clusteringwhen creating content plans. Everything will simply go in the direction of exploiting the power of intelligent knowledge graphs and knowledge graph embeddings.
However, bear in mind that anticipating user needs in a constantly evolving world is not easy. Luckily, we at WordLift have the technology and the scientific know-how to tackle these challenges in a more structured way. The key for you to solve these ever-changing user needs is to power your content creation and maintenance process with a knowledge graph strategy where all your entities can be described and explained to search engines. We are here for what comes next and ready to work together to solve pressing user-needs.
Structured data has radically disrupted the way SEO is done. There is an SEO before Schema Markup and an SEO after Schema Markup, and this is now clear to every search ranking expert.
At the same time, manually implementing structured data is – let’s be honest – much work. That’s why more and more SEO consultants, editors and marketers are turning to solutions that simplify content markup.
Schema App was one of the pioneers in this market and one of the first to offer a tool that helps manage structured data more easily.
In this article, we will try to compare Schema App with our solution, WordLift. Before we get into the details, however, let us introduce ourselves a little better. 🙂
WordLift is the first solution that allows you to create a knowledge graph used to implement structured data and increase your website’s search engine ranking and visibility.
Now let’s get into the meat of our article, and kick off the comparison!
The phrase “Content is King” has become a cornerstone of many online marketers. But just putting out a lot of content won’t magically make your site more visible. Even if you produce a lot of great content, it can easily get lost in the billions upon billions of pages online. If your content isn’t easily crawl-able it won’t get indexed.
As Ryan Shelley states, good content is no longer enough today. If Google’s crawlers can’t understand it perfectly, your content risks getting lost in the vastness of the web.
That’s where Schema Markup comes into play. Structured data helps the search engine interpret, categorize, and distribute your content to the right users.
If you want to add structured data to your pages manually, you need to know the schema.org specific conventions very well. Otherwise, you will get into trouble. On the other hand, it is also a matter of time. Adding one by one all the proper tags to mark up your page can cost you hours of work for each individual page. This is already stressful enough for those who have a small website. You can just figure out how it can become an absolute nightmare for those who work on much larger sites: news sites, editorial portals, e-commerce, sites of large and very structured enterprises.
From this point of view, a tool that automatically detects the “hot spots” of your content and suggests how to transform them into markup is a real godsend!
Are WordLift and Schema App alternative solutions?
Both WordLift and Schema App help you add structured data to your pages to speak Google’s language without having to write a line of code.
The way they do it, though, is very different!
WordLift relies on artificial intelligence that analyzes your content and automatically suggests entities to add schema.org markup to your website. The process is fast and smooth, the interface is extremely simple, and anyone can use it.
Schema App instead uses an Editor to insert Schema Markup on every page of your website. In this case, you control the content and fill in the recommended fields (again, without intervening directly on the code). So you have more control over the data, but indeed the working time is longer.
In other words, the peculiarity of WordLift is the ability to generate a knowledge graph and use artificial intelligence to extract and mark up concepts extracted from the content. Schema App, on its hand, was the first solution to allow very granular markup customization – something that is now also possible with WordLift Business using Mappings.
How WordLift and Schema App work
WordLift’s NLP (our artificial intelligence) scans the page you’re working on and suggests key concepts that characterize the content, identifying the relevant markup.
As we show you in the video above, WordLift can tell you which entities you could mark in your content and which properties you should assign to them. In addition, your entities are automatically connected with entities that already exist on DBpedia or Wikipedia.
In the gif below, you can further verify how easy it is to mark your content with WordLift. Just a few clicks to declare to Google that in your article you are talking about Michelangelo, the famous Renaissance artist; as soon as you do this, WordLift will add the schema type Persona and connect the name to the related Wikipedia page.
As you can see, WordLift guides users step by step, and they don’t even need to know what’s going on the code side. That’s why our solution is suitable for SEO experts (who often choose us to simplify and speed up processes), and also for marketers and web editors who don’t know code but want to improve their content thanks to structured data.
Even if you need to add a new, unknown entity to WordLift (such as a person or a local business), the software will show you how to do it at every step. Once you create a new entity, you can save it and reuse it later — or other website users can reuse it.
Pay attention because this is a key step!
Entity after entity, you can create a personal vocabulary of your core entities (concepts, people, companies, places, and more) that you can then use to mark new occurrences on different pages with a single click. What’s more, content you’ve already published can be converted into entities and can thus benefit from better markup and the ability to expand the number of internal links.
Try WordLift and let AI and Machine Learning help you with SEO image. Discover our SEO Management Service.
Andrea Volpini
The Schema App Editor allows users to mark up web pages one by one by creating data points for each entity. So if you use Schema App, you don’t need to know the code, but you do need to know in advance what you want to mark up (and how) in your content.
Basically, with Schema App, you have total control over your structured data. Still, you need a deep understanding of semantic markup and SEO to make the best decisions for your content.
Once you have processed the markup, you can finally export it and add it to your page as a JSON-LD.
Content modelling with WordLift and Schema App
One of the biggest challenges you face if you manually manage your page markup is definitely the time it takes to enter data on each page.
WordLift has solved this problem with WordLift Mapping, one of the time-saving features that will make you love our software.
WordLift Mapping allows you to create templates to apply Schema Markup and a large number of pages more quickly and describe your content model to Google. On each page, you can:
Reuse fields that you have already configured through the Advanced Custom Fields plugin or directly through the CMS in use
Create new fields based on schema.org taxonomy.
Even with Schema App’s Highlighter (available with the Enterprise plan), you can do something very similar: mark your page visually via front-end and scale the markup, using the same template for many similar pages.
APIs and integrations
Both the Schema App Editor & Highlighter have APIs and can be integrated with any website. WordLift addresses different needs and interacts with data from different CMSs through the app.wordlift.io platform.
In addition, WordLift provides developers with its own APIs allowing our customers to query their database via GraphQL, use artificial intelligence to synthesize text, classify content, analyze the markup schema present on the site and access many other features.
#1 Plus: WordLift’s Knowledge Graph
Simplifying, we could say that the Knowledge Graph is a huge database where information is organized and related. Thus, the main benefit of a Knowledge Graph is that it allows you to contextualize and connect large amounts of data in a perfectly understandable way for all types of machines.
As we all know, Google has its own Knowledge Graph. But not only Google: all tech giants have developed similar technologies to manage data better internally and, at the same time, communicate more efficiently with search engines, thus achieving greater organic visibility.
WordLift allows all companies to create their own Knowledge Graph. In other words, WordLift connects the markup schema of your pages with the database that search engines use to understand your online content.
Just as your sitemap.html shows Google the most important pages within your site, WordLift creates a kind of semantic sitemap or map of meanings and relationships. The result will then be a network of connections that helps define every concept, person, product, or other type of entity presented on your website, allowing Google to interpret and index them perfectly.
WordLift’s widgets leverage the data contained in your Knowledge Graph to improve engagement on your site, thus marrying SEO and User Experience.
It does this through internal links, widgets, and context cards: thanks to these features, you can double the time spent on each page by users and the pages consulted per session in a few days!
Data visualization widgets (such as maps and timelines) and widgets dedicated to recommended content will allow you to improve users’ experience on your web pages and push them to explore more pages, and increase time spent on the site.
And now, let’s understand better what we’re talking about!
Above, you can see the Faceted Search, a widget for suggesting other content to your users that might interest them. WordLift selects each piece of content based on the entities mentioned on the page.
Another super useful feature for improving engagement is WordLift Geomap, which creates a custom map linked to your content.
If you have an e-commerce, you might find exciting the related products widget – included in our e-commerce extension. Also, in this case, WordLift itself will suggest to you a selection of products based on semantic connections.
#3 Plus: Automatic Summarization
Thanks to its artificial intelligence and, more specifically, the so-called NLP, WordLift allows you to summarize your contents in a few lines. This function generates an extract that WordLift uses in various ways:
To add the schema.org property description;
To create interactive context cards that are activated when you mouse over internal links;
To suggest an automatic Excerpt that WordPress uses where the template requires it.
Want to know more? Find out everything you need to know about our automatic summaries.
Schema App and WordLift: plans and costs
Both WordLift and Schema App provide different subscription plans. Let’s take a look at the differences now.
Schema App
Schema App offers two different subscription solutions, the Pro version and the Enterprise version. There is also a free version of the WordPress software that includes automatic markup of Posts and Pages. However, the free plan is quite basic and allows only minimal customizations. Here you can see the Schema Types offered with the free plugin:
It would be best to consider that the simplified automatic markup has limited benefits, as the output is very repetitive and therefore not very useful for search engines. That’s why, in any case, the Pro version is highly recommended for anyone who wants to get serious about structured data.
WordLift
WordLift subscription plans, on the other hand, all give you access to the same technology. Any plan you choose, you can indeed:
Use artificial intelligence to automate content analysis and Schema Markup implementation;
Publish your Knowledge Graph;
Access the recommended content widget.
Users who choose WordLift’s Business Subscription Plan also have access to the E-Commerce extension, which enables advanced markup functionality for shops and product suggestion widgets, and also allows you to create a specific Knowledge Graph for products on sale.
Schema App vs WordLift: pros and cons
As you’ve probably figured out by now, Schema App and WordLift are very different solutions for handling structured data, each with its own specific advantages. Let’s try to compare them in this summary table:
WordLift
Schema App
WordLift provides a simple and intuitive interface that allows anyone to add schema markup to pages. AI creates a guided path and follows you step by step.
Schema App gives users more control over the structured data they create.
With the support of artificial intelligence, WordLift allows SEO experts to speed up, automate, and eventually delegate markup-related tasks.
Even if you don’t have to write a single line of code, Schema App requires a good knowledge of schema markup.
WordLift automatically creates your Knowledge Graph from the data you enter. In addition, it links new entities with DBpedia, Freebase, GeoNames and other compatible data sources.
In addition, the entities you create with WordLift can be linked directly from Wikidata using – on the corresponding entity page in Wikidata – the WordLift URL property (which is now part of the Wikidata ontology).
With Schema App, you can add links to DBpedia as sameAs to connect your data with the web of data, but you will have to create the connections manually.
WordLift offers Knowledge Graph-based widgets that enhance the user experience on the site by making it easier to view and link to web content.
Schema App manages schema.org markup but it doesn’t have any recommendation widgets to add to the content.
With WordLift Mapping, you can use a template to add schema markup to multiple pages and describe your content model to Google.
Schema App does the same thing through the Highlighter feature (available in the Enterprise version).
With Highlighter, you can visually mark up any page and reuse the markup in similar pages.
WordLift does not have a free version. Our subscriptions start at €588 per year.
The free version of Schema App for WordPress is minimal and allows you to add basic markup to your Posts and Pages.
Schema App Pro starts at $300 (€254.57) per year.
In a nutshell, using Schema App requires advanced knowledge of Schema Markup. Sure, the software makes markup more accessible than manual entry, but it could still be complicated for users who are not so experienced.
WordLift, on the other hand, makes the benefits of structured data accessible to users with any degree of SEO expertise. Nonetheless, many experts choose our solution for the actual time savings or delegate some of the tasks to junior staff members.
However, perhaps WordLift’s greatest strength is its custom Knowledge Graph, which gives anyone access to the same technology that the tech giants use to index their content and get backlinks from sources like Wikidata and DBpedia.
Want to learn more about all the features of WordLift?
If you are a developer, you probably have already worked with or heard about SEO (Search Engine Optimization). Nowadays, when optimizing websites for search engines, the focus is on annotating websites’ content so that search engines can easily extract and “understand” the content. Annotating, in this case, is the representation of information presented on a website in a machine-understandable way by using a specific predefined structure. Noteworthy, the structure must be understood by the search engines. Therefore, in 2011 the four most prominent search engine providers Google, Microsoft, Yahoo!, and Yandex, founded Schema.org. Schema.org provides patterns for the information you might want to annotate on your websites, including some examples. Those examples allow web developers to get an idea of making the information on their website understandable by search engines.
Knowledge Graphs
Besides using the websites’ annotations to provide more precise results to the users, search engines use them to build so-called Knowledge Graphs. Knowledge Graphs are huge semantic nets describing “things” and their connections between each other.
Consider three “things”, i.e. three hiking trails “Auf dem Jakobsweg”, “Lofer – Auer Wiesen – Maybergklamm” and “Wandergolfrunde St. Martin” which are located in the region “Salzburger Saalachtal” (another “thing”). “Salzburger Saalachtal” is located in the state “Salzburg,” which is part of “Austria.” If we drew those connections on a sheet, we would end up with something that looks like the following.
This is just a small extract of a Knowledge Graph, but it shows pretty well how things are connected with each other. Search engine providers collect data from a vast amount of websites and connect the data with each other. Not only search engine providers are doing so but even more companies are building Knowledge Graphs. Also, you can build a Knowledge Graph based on your annotations, as they are a good starting point. Now you might think that the amount of data is not sufficient for a Knowledge Graph. It is essential to mention that you can connect your data with other data sources, i.e., link your data or import data from external sources. There exists a vast Linked Open Data Cloud providing linked data sets of different categories. Linked in this case means that the different data sets are connected via certain relationships. Open implies that everyone can use it and import it into its own Knowledge Graph.
An excellent use case for including data from the Linked Open Data Cloud is to integrate geodata. For example, as mentioned earlier, the Knowledge Graph should be built based on the annotations of hiking trails. Still, you don’t have concrete data on the cities, regions, and countries. Then, you could integrate geodata from the Linked Open Data Cloud, providing detailed information on cities, regions, and countries.
Over time, your Knowledge Graph will grow and become quite huge and even more powerful due to all the connections between the different “things.”
Sounds great, but how can I use the data in the Knowledge Graph?
Unfortunately, this is where a huge problem arises. For querying the Knowledge Graph, it is necessary to write so-called SPARQL queries, a standard for querying Knowledge Graphs. SPARQL is challenging to use if you are not familiar with the syntax and has a steep learning curve. Especially, if you are not into the particular area of Semantic Web Technologies. In that case, you may not want to learn such a complex query language that is not used anywhere else in your daily developer life. However, SPARQL is necessary for publishing and accessing Linked Data on the Web. But there is hope. We would not write this blog post if we did not have a solution to overcome this gap. We want to give you the possibility, on the one hand, to use the strength of Knowledge Graphs for storing and linking your data, including the integration of external data, and on the other hand, a simple query language for accessing the “knowledge” stored. The “knowledge” can then be used to power different kinds of applications, e.g., intelligent personal assistants. Now you have been tortured long enough. We will describe a simple middleware that allows you to query Knowledge Graphs by using the simple syntax of GraphQL queries.
What is GraphQL?
GraphQL is an open standard published in 2015, initially invented by Facebook. Its primary purpose is to be a flexible and developer-friendly alternative to REST APIs. Before GraphQL, developers had to use API results as predefined by the API provider even if only one value was required by the user of the API. GraphQL allows specifying a GraphQL query in a way that only the relevant data is fetched. Additionally, the JSON syntax of GraphQL makes it easy to use. Nearly every programming language has a JSON parser, and developers are familiar with representing data using JSON syntax. The simplicity and ease of use also gained interest in the Semantic Web Community as an alternative for querying RDF data. Graph database (used to store Knowledge Graphs) providers like Ontotex (GraphDB) and Stardog introduced GraphQL as an alternative query language for their databases. Unfortunately, those databases can not be exchanged easily due to the different kinds of GraphQL schemas they require. The GraphQL schema defines which information can be queried. Each of the database providers has its own way of providing this schema.
Additionally, the syntax of the GraphQL queries supported by the database providers differs due to special optimizations and extensions. Another problem is that there are still many services available on the Web that are only accessible via SPARQL. How can we overcome all this hassle and reach a simple solution applicable to arbitrary SPARQL endpoints?
GraphSPARQL
All those problems led to a conceptualization and implementation of a middleware transforming GraphQL into SPARQL queries called GraphSPARQL. As part of the R&D work that we are doing, in the context of the EU-cofounded project called WordLift Next Generation, three students from the University Innsbruck developed GraphSPARQL in the course of a Semantic Web Seminar.
Let us consider the example of a query that results in a list of persons’ names to illustrate the functionality of GraphSPARQL. First, the user needs to provide an Enriched GraphQL Schema, in principle defining the information that should be queryable by GraphSPARQL. This schema is essential for the mapping between the GraphQL query and the SPARQL query.
The following figure shows the process of an incoming query and transforming it to a SPARQL query. If you want to query for persons with their names, the GraphQL query shown on the left side of the figure will be used. This query is processed inside GraphSPARQL by a so-called Parser. The Parser uses the predefined schema to transform the GraphQL query into the SPARQL query. This SPARQL query is then processed by the Query Processor. It handles the connection to the Knowledge Graph. On the right side of the figure, you see the SPARQL query generated based on the GraphQL query. It is pretty confusing compared to the simple GraphQL query. Therefore, we want to hide those queries with our middleware.
As a result of the SPARQL query, the Knowledge Graph responds with something that seems quite cryptic, if you are not familiar with the syntax. You can see an example SPARQL response on the following figure’s right side. This cryptic response is returned to the Parser by the Query Processor. The Parser then, again with the help of the schema, transforms the response into a nice-looking GraphQL response. The result is a JSON containing the result of the initial query.
GraphSPARQL provides you easy access to the information stored in a Knowledge Graph using the simple GraphQL query language.
You have a Knowledge Graph stored in a graph database that is accessible via SPARQL endpoint only? Then GraphSPARQL is the perfect solution for you. Before you can start, you need to follow two configuration steps:
Provide the so-called Enriched GraphQL Schema. This schema can either be created automatically based on a given ontology, e.g., schema.org provides its ontology as a download or can be defined manually. An example for both cases can be found on the GraphSPARQL Github page in the example folder: – automatic creation of a schema based on the DBPedia ontology – manually defined schema
Define the SPARQL endpoint GraphSPARQL should connect to. This can be done in the configuration file (see “config.json” in the example folder).
Have you done both preparation steps? Perfect, now you are ready to use GraphSPARQL on the endpoint you defined. Check the end of the blog post if you are interested in a concrete example.
Summary
– What are the benefits of GraphSPARQL? – Benefit from Knowledge Graphs by using a simple query language – Simple JSON syntax for defining queries – Parser support for the JSON syntax of GraphQL queries in nearly all programming languages – GraphQL query structure represents the structure of the expected result – Restrict data access via the provided GraphQL schema
GraphSPARQL as middleware allows querying SPARQL endpoints using GraphQL as a simple query language and is an important step to open Semantic Web Technologies to a broader audience.
Example
Docker container to test GraphSPARQL:
Two options to start the docker container are supported so far:
Use predefined configuration for DBPedia: start the GraphSPARQL docker container


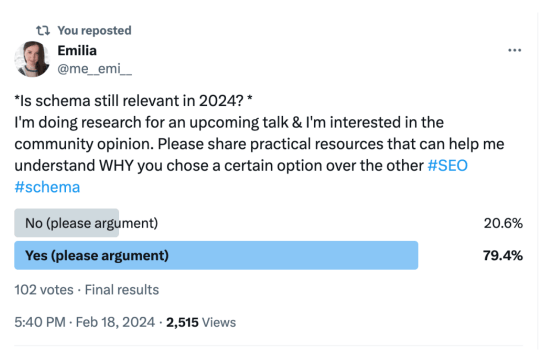





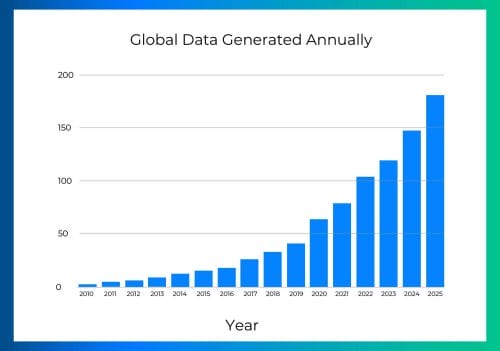
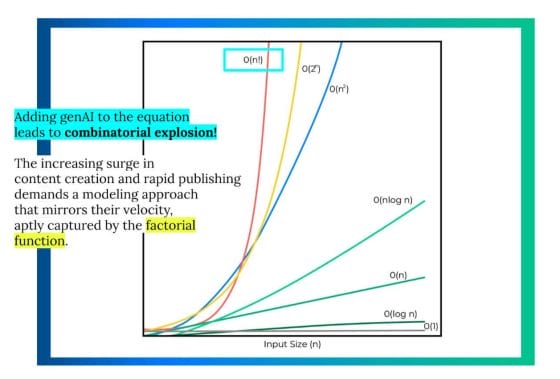

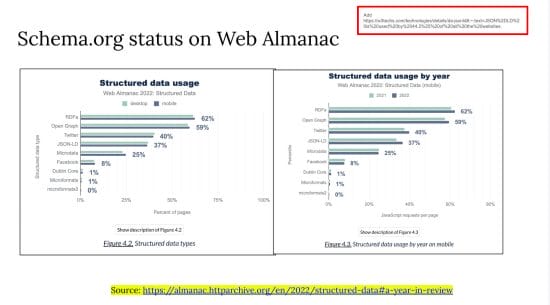
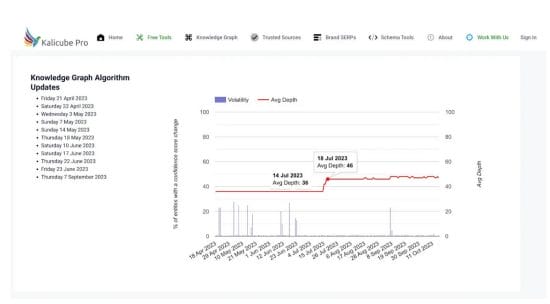
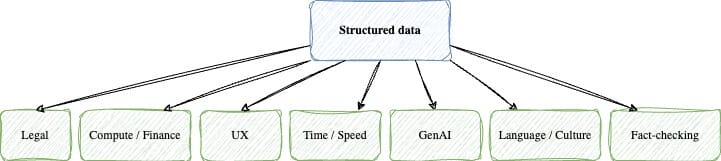







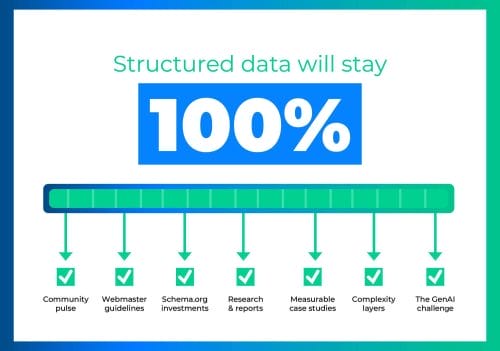


![The Lifecycle [and the Death] of SEO Content Documents As We Know Them](https://esfjz3kkrvq.exactdn.com/blog/en/wp-content/uploads/sites/3/2022/10/seo-content-documents-1080x675.jpg?strip=all&lossy=1&ssl=1)
![Entity Search: The Past And The Future [An Overview]](https://esfjz3kkrvq.exactdn.com/blog/en/wp-content/uploads/sites/3/2022/07/entity-search-1-1-1080x675.png?strip=all&lossy=1&ssl=1)